Суть
Компания Google представила Gemini 3.1 Flash Live — свою самую совершенную на сегодняшний день модель для работы со звуком и голосом в реальном времени. Главное достижение обновления заключается в повышении скорости отклика и точности распознавания речи. Это делает диалог с искусственным интеллектом более плавным и естественным. Модель уже доступна для разработчиков через программный интерфейс (API), для корпоративных клиентов и для обычных пользователей в сервисах Search Live и Gemini Live.
Контекст
Индустрия искусственного интеллекта постепенно переходит от текстовых интерфейсов к голосовым (voice-first). Ранее голосовые помощники работали по каскадной схеме: перевод голоса в текст, обработка текста языковой моделью, генерация текстового ответа и его последующая озвучка. Это создавало заметные задержки и лишало систему возможности улавливать эмоциональную окраску речи. Современные мультимодальные модели, такие как Gemini 3.1 Flash Live, обрабатывают звук напрямую. Это позволяет им реагировать на изменение тона, темпа и даже на прерывания со стороны пользователя.
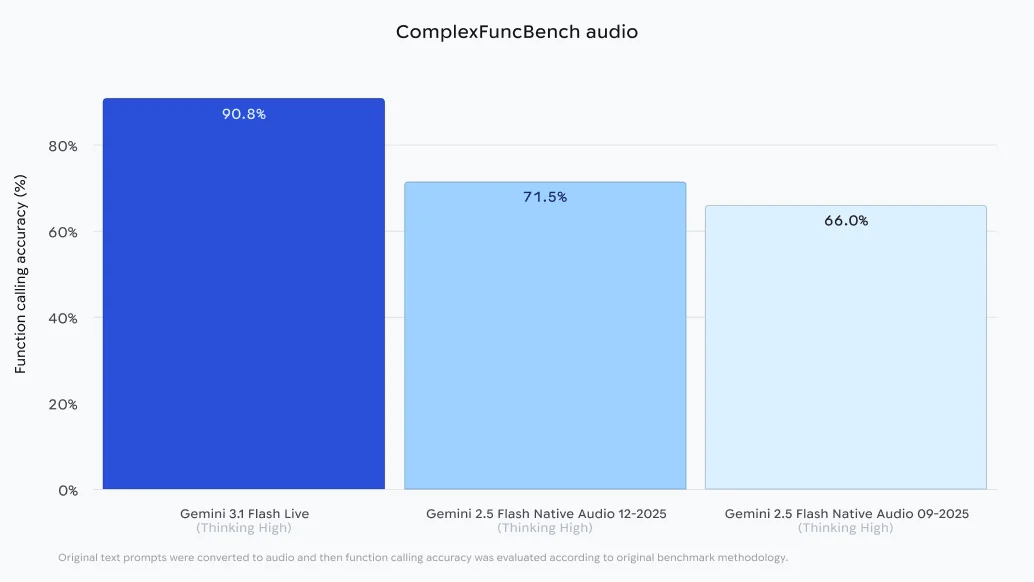
ComplexFuncBench audio bar graph
Детали
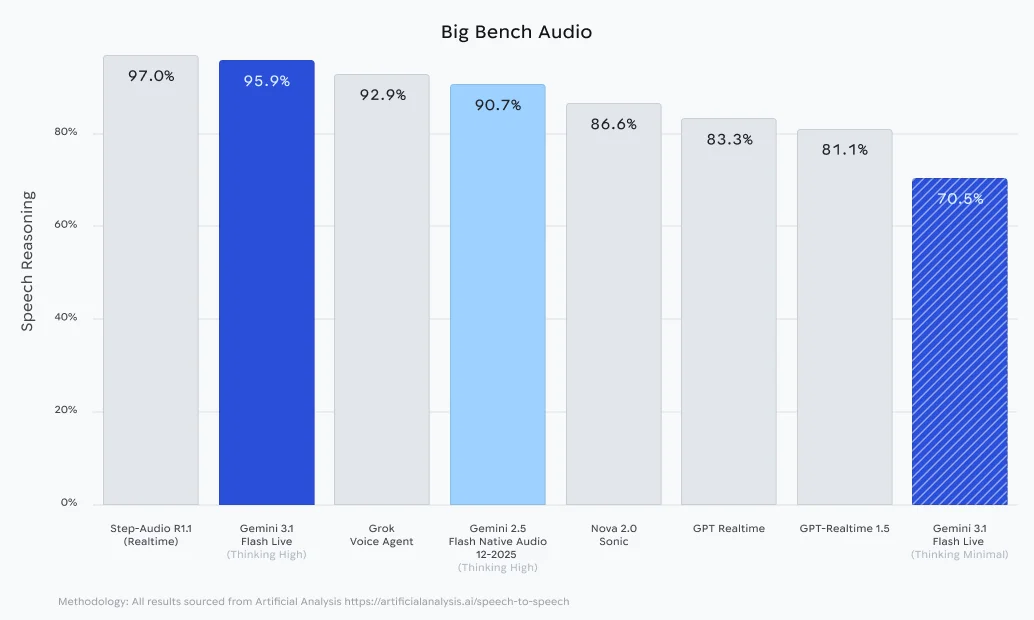
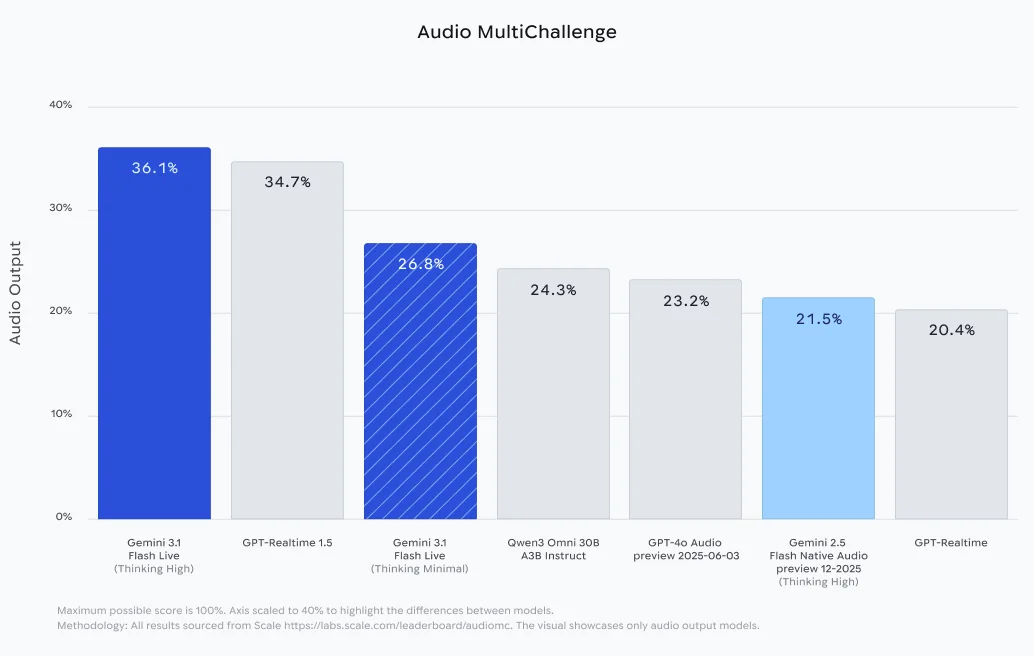
Новая модель демонстрирует значительный прогресс в решении сложных задач. В тестах ComplexFuncBench Audio, которые оценивают способность модели вызывать функции в несколько этапов с различными ограничениями, Gemini 3.1 Flash Live набрала 90.8%. В бенчмарке Audio MultiChallenge от Scale AI модель показала результат 36.1% в режиме активного «размышления», успешно справляясь со сложными инструкциями в условиях типичных для реального мира запинок и фонового шума.
Для обычных пользователей в сервисе Gemini Live модель теперь способна удерживать контекст беседы в два раза дольше, что критически важно для длительных обсуждений или мозговых штурмов. Кроме того, Search Live с поддержкой новой модели теперь работает более чем в 200 странах, обеспечивая многоязычную поддержку.
Важным техническим решением стало внедрение технологии SynthID. Весь аудиоконтент, сгенерированный моделью 3.1 Flash Live, помечается невидимым водяным знаком. Это встроено непосредственно в звуковую дорожку и помогает надежно определять контент, созданный искусственным интеллектом.
Анализ
Выпуск Gemini 3.1 Flash Live показывает, что конкуренция в сфере генеративного искусственного интеллекта смещается в сторону надежности и пользовательского опыта. Высокие баллы в тестах на выполнение сложных инструкций означают, что бизнес получает инструмент не просто для ответов на вопросы, но для создания автономных голосовых агентов. Улучшенное понимание интонаций позволяет модели динамически корректировать свои ответы, если пользователь выражает растерянность или разочарование. Это фундаментальный сдвиг для систем клиентского сервиса.
Перспектива
В ближайшем будущем мы увидим массовое внедрение подобных голосовых моделей в корпоративные процессы. Компании смогут создавать агентов поддержки, которые не звучат как роботы и способны решать многосоставные задачи в шумной среде. В то же время, обязательное использование водяных знаков SynthID задает важный индустриальный стандарт. По мере того как синтезированный голос становится неотличим от настоящего, встроенная маркировка станет главным инструментом в борьбе с дезинформацией и мошенничеством.