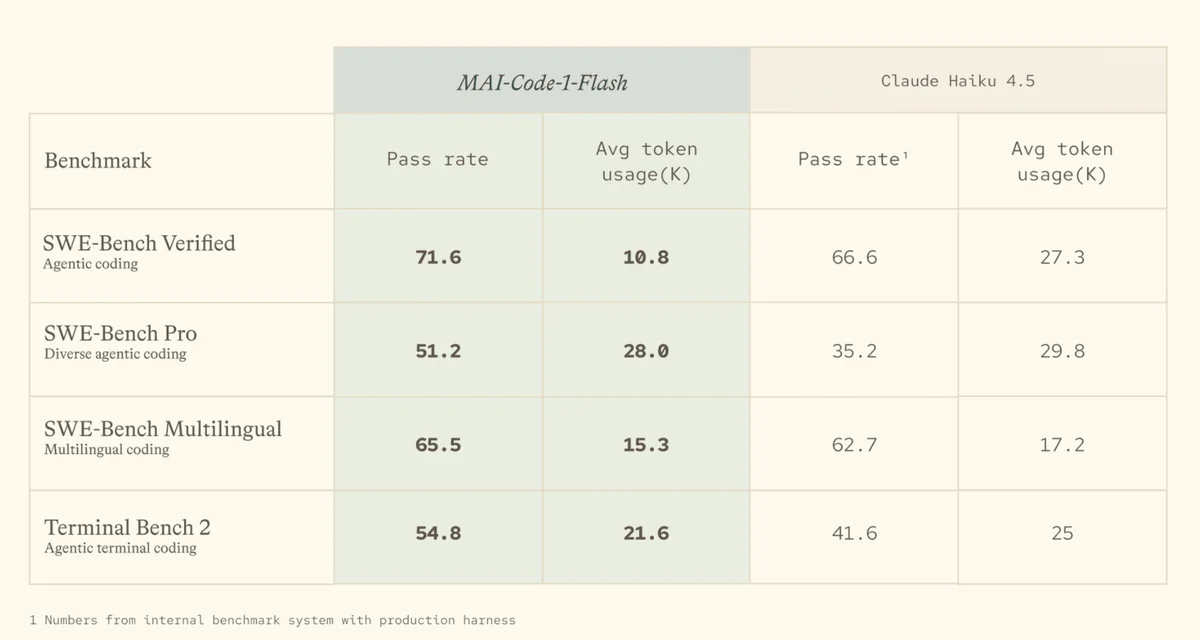
Microsoft представила новую модель для программирования MAI-Code-1-Flash, добавив в ее техническое описание необычную, но крайне важную характеристику — среднее использование токенов. Это событие знаменует фундаментальный сдвиг в индустрии: фокус рынка окончательно смещается с чистой производительности на экономическую целесообразность.
В первой же строке спецификации указано, что модель от Microsoft достигает результата в 71.6 балла на сложном тесте SWE-Bench Verified. Примечательно здесь не столько само значение, сколько тот факт, что для его достижения требуется примерно в три раза меньше токенов, чем расходует сопоставимая по уровню модель Claude Haiku 4.5.
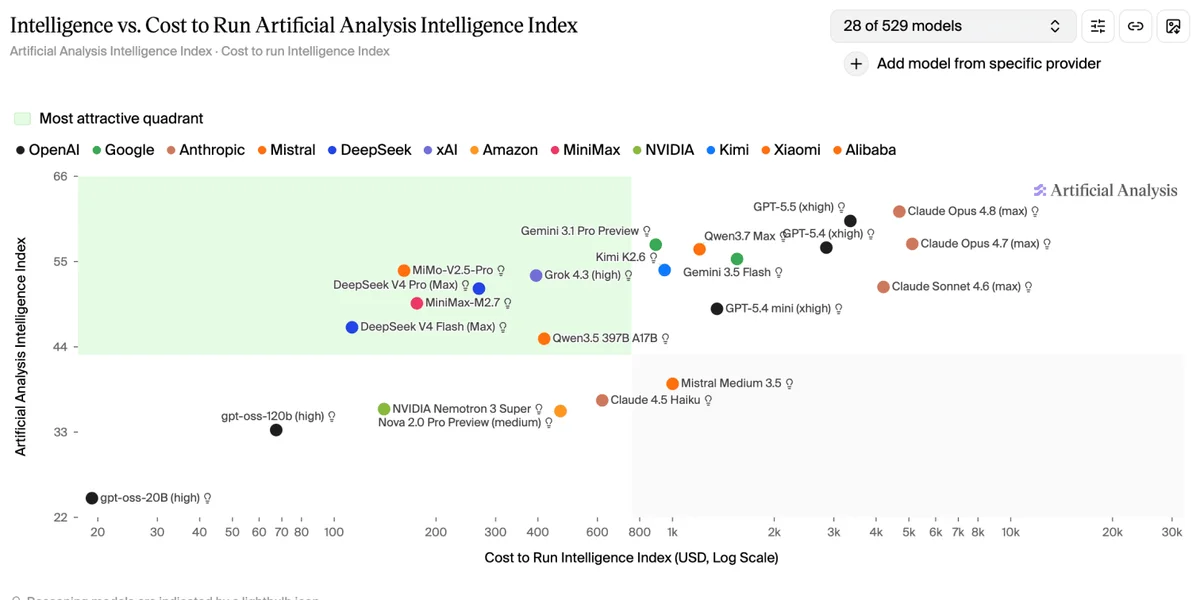
Теперь бенчмарки измеряются в двух измерениях: общий уровень интеллекта и стоимость его достижения.
Screenshot 2026-06-02 at 9.22.43 PM
Исторически индустрия находилась в фазе активного субсидирования. Разработчики базовых моделей и облачные провайдеры брали на себя часть затрат на вычисления, чтобы стимулировать внедрение технологий. Параллельно процветала практика оптимизации под бенчмарки, когда модели генерировали избыточное количество скрытых токенов рассуждений для достижения высоких оценок в тестах. Эта эпоха подходит к концу.
Компании сталкиваются с суровой финансовой реальностью. Даже самые богатые корпорации мира больше не могут позволить себе использовать передовые большие языковые модели (LLM) для каждой повседневной задачи.
Крупный бизнес уже начал применять экстренные меры. Uber был вынужден ограничить расходы сотрудников на нейросети после того, как годовой бюджет направления был исчерпан всего за четыре месяца. Salesforce потратила 300 миллионов долларов на оплату токенов Anthropic, что привело к заморозке найма новых инженеров. Показательно, что даже сама Microsoft отменила лицензии на использование Claude Code для части своих разработчиков, переведя их на более экономичный внутренний инструмент из-за неконтролируемого роста расходов.
Screenshot 2026-06-03 at 5.49.00 AM
Новый двойной стандарт оценки отвечает на главный вопрос любого корпоративного покупателя: сколько интеллекта я получаю на один вложенный доллар?
Аналитические платформы уже начали адаптироваться к этой реальности. По данным независимых исследований, модели GPT 5.5 и Claude Opus 4.8 показывают практически идентичный результат в индексе интеллекта — около 60 баллов. Однако прогон стандартного набора тестов на GPT 5.5 обходится в 3357 долларов, тогда как на Opus 4.8 эта сумма достигает 4685 долларов. Разница в стоимости составляет 40% при одинаковом качестве ответов.
В ближайшем будущем компаниям, разрабатывающим нейросети, придется вести конкурентную борьбу сразу на двух фронтах. На уровне инфраструктуры будет оцениваться соотношение цены и качества генерации.
На уровне пользовательских приложений конкуренция перейдет на ступень выше. Разработчики программного обеспечения будут бороться за метрику «стоимость результата». Заказчиков перестанет интересовать цена за миллион токенов. Их будет волновать, во сколько обойдется закрытый тикет в службе поддержки, успешно интегрированный участок кода или решенная жалоба клиента. Каждый уровень технологического стека теперь должен формировать ценообразование так, как мыслит конечный потребитель: оплата за решенную задачу, а не за вычислительные ресурсы.