Суть
Подразделение Microsoft Research представило Memora — масштабируемую систему памяти, предназначенную для ИИ-агентов, работающих с долгосрочными задачами. Новая архитектура решает фундаментальную проблему современных больших языковых моделей (LLM): их неспособность эффективно сохранять, структурировать и извлекать контекст в ходе длительных взаимодействий, длящихся неделями или месяцами.
Контекст
Современные языковые модели, несмотря на свои выдающиеся способности к рассуждению, по своей природе не имеют состояния. Каждый новый сеанс работы начинается с чистого листа. Чтобы ИИ-агент "помнил" ход длительного проекта, ему приходится либо каждый раз заново анализировать всю историю переписки, либо полагаться на внешние системы памяти.
Существующие подходы упираются в жесткий компромисс между абстракцией и специфичностью. Системы поиска дополненной генерации (RAG) или такие инструменты, как Mem0, сохраняют сырые фрагменты текста. Это сберегает детали, но приводит к фрагментации: память становится разрозненной и теряет связность. С другой стороны, методы суммаризации сжимают опыт в краткие выжимки. Это эффективно для экономии токенов, но при этом безвозвратно теряются критически важные нюансы — конкретные даты, ограничения или краевые случаи. Графовые базы данных пытаются навести порядок, но требуют жестко заданных онтологий, которые плохо адаптируются к новым предметным областям.
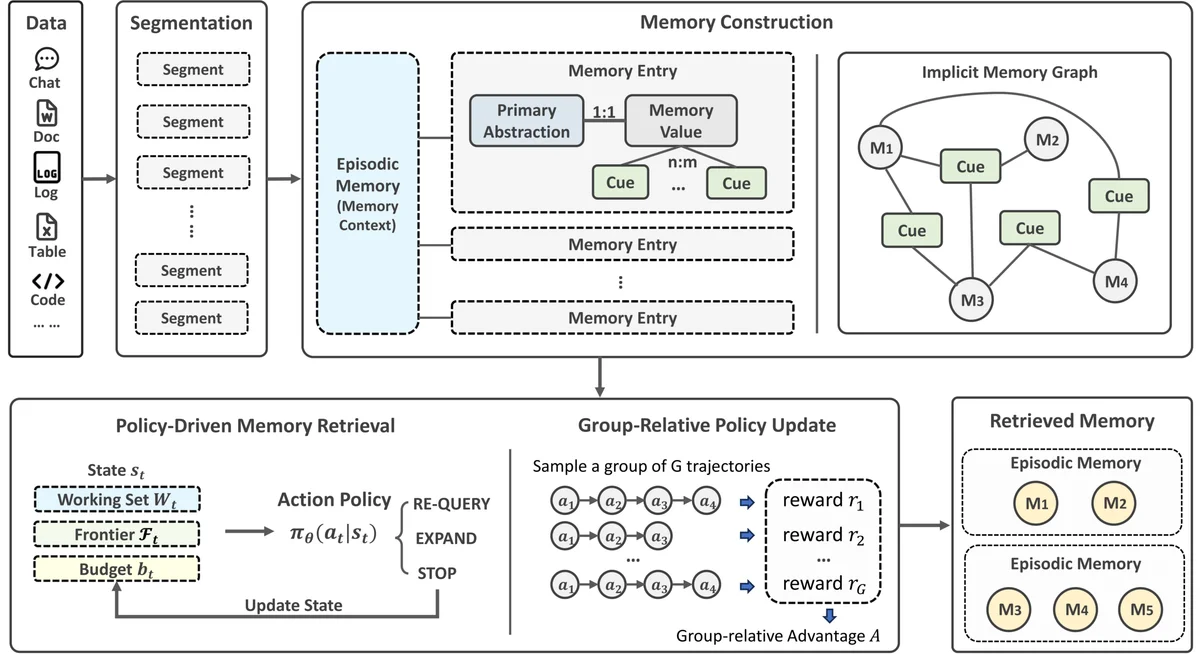
Overview of the Memora architecture showing how multimodal data is segmented, converted into structured memory entries and an implicit memory graph, then retrieved through a policy-driven process optimized with group-relative learning to return relevant episodic memories.
Детали
Архитектура Memora решает эту проблему за счет разделения того, что именно хранится, и того, как эта информация извлекается. Каждая запись в системе состоит из двух компонентов:
Во-первых, это первичная абстракция — короткая фраза из 6–8 слов, улавливающая фундаментальную суть воспоминания. Во-вторых, это само значение памяти — полная форма записи, содержащая все богатые детали и контекст.
Ключевое нововведение заключается в том, что для векторного поиска векторизуется только первичная абстракция. Само значение памяти никогда не извлекается напрямую по своему содержимому. Это означает, что новая информация о развивающейся теме сливается с существующей записью под той же абстракцией, а не плодит цепочку частичных дубликатов.
Для обеспечения гибкости система использует "якорные подсказки" (cue anchors) — короткие контекстные теги, которые генерируются органически и предоставляют альтернативные пути к одной и той же информации. Например, если пользователи договорились перенести сроки проекта, эта информация будет доступна и по запросу об участниках, и по запросу о названии проекта, без необходимости заранее прописывать жесткие связи в графе знаний.
Поиск в Memora работает не как одноразовый семантический запрос, а как итеративный процесс рассуждения. Политика извлечения позволяет агенту переходить от одного тега к другому, собирая многосоставный контекст так, как это делал бы человек, вспоминающий цепочку связанных событий.
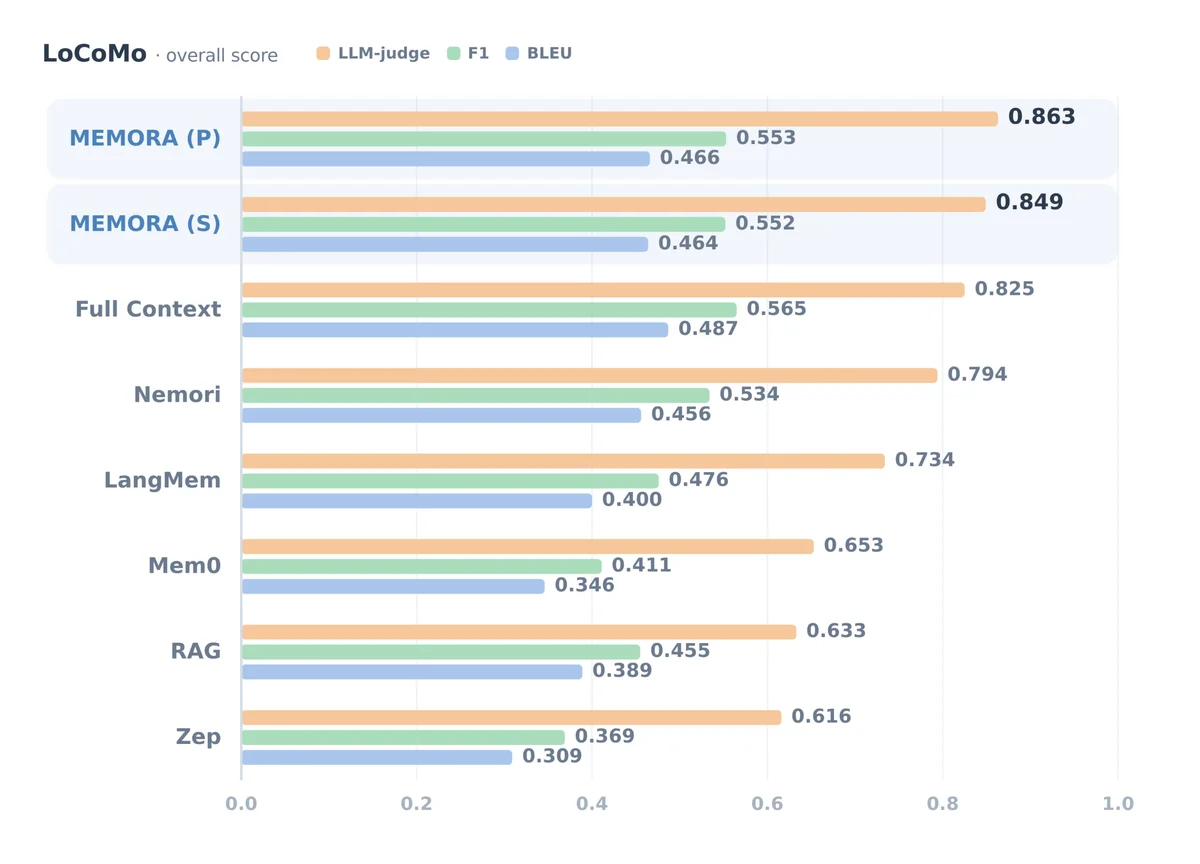
Bar chart comparing LoCoMo overall scores across memory systems using LLM-judge, F1, and BLEU metrics. Memora (P) achieves the highest LLM-judge score (0.863), followed by Memora (S) (0.849) and Full Context (0.825). Memora variants outperform other memory-based approaches across all three metrics.
Анализ
Результаты тестирования показывают, что индустрия может перестать полагаться исключительно на наращивание размера контекстного окна моделей. На бенчмарках LoCoMo (в среднем 600 реплик в диалоге) и LongMemEval (контекст до 115 000 токенов) Memora установила новый стандарт качества, превзойдя RAG, Mem0, Zep и даже метод полного контекстного вывода.
При этом эффективность системы кардинально выше: Memora сохраняет примерно в два раза меньше записей на один разговор по сравнению с Mem0 и сокращает потребление токенов до 98% по сравнению с подачей всей истории в контекст модели. Это означает радикальное снижение вычислительных затрат при одновременном повышении точности ответов, особенно в задачах, требующих многошаговых рассуждений.
Перспектива
Код проекта Memora уже опубликован в открытом доступе. Разработчики Microsoft видят в этом лишь первый шаг к созданию автономных агентов, способных накапливать институциональные знания годами.
В дальнейших планах исследователей — развитие концепции MemLoop (системы, которая учится на собственных ошибках поиска), изучение отложенной памяти (когда агент ждет накопления достаточного контекста перед сохранением факта) и создание механизмов групповой памяти для безопасного обмена знаниями между целыми командами ИИ-помощников. Переход от парадигмы агентов без состояния к агентам с долгосрочной, структурированной памятью откроет дорогу к совершенно новому классу корпоративного программного обеспечения.