Суть
Исследовательское подразделение Microsoft Research представило SkillOpt — новый подход к созданию и улучшению навыков для ИИ-агентов. Метод предлагает относиться к текстовым файлам с инструкциями (навыкам) как к обучаемым параметрам, которые существуют отдельно от основной языковой модели. Это позволяет систематически улучшать поведение агента без необходимости изменять веса самой нейросети.
Контекст
Современные большие языковые модели (LLM) все чаще используются в качестве агентов, способных собирать данные, использовать инструменты и выполнять многошаговые задачи. Однако главная проблема сегодня заключается в надежности их работы. Обычно инструкции для таких агентов пишутся вручную экспертами или генерируются самой моделью за один проход.
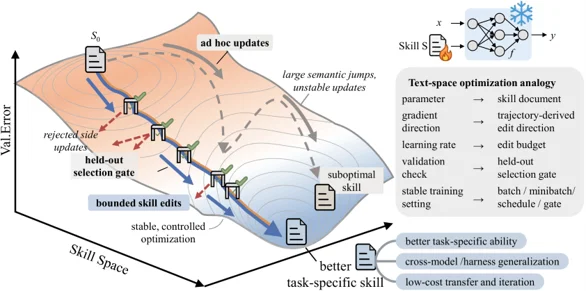
Figure 1. A frozen target model executes tasks while a separate optimizer model trains the skill layer from trajectory feedback, exporting the reusable skill file best_ skill.md through validation gating.
При попытках улучшить эти инструкции разработчики сталкиваются с тем, что промпты становятся слишком длинными, а их эффективность непредсказуемо меняется — возникает так называемый дрейф промптов (prompt drift). В отличие от классического машинного обучения, здесь нет контроля размера шага, проверки на отложенных данных и памяти о неудачных изменениях.
Детали
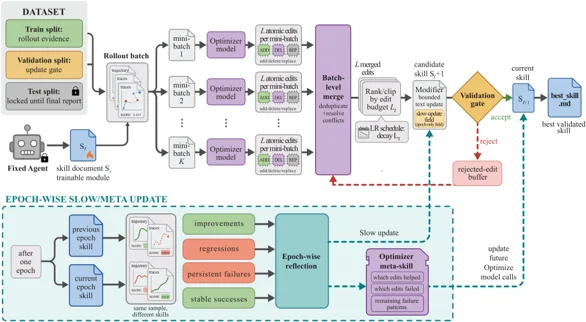
SkillOpt решает эту проблему, внедряя цикл оптимизации, похожий на обучение нейросетей, но работающий исключительно с текстом. Процесс состоит из нескольких этапов:
- Прямой проход (forward pass): целевая модель (с замороженными весами) выполняет пакет задач, используя текущую версию навыка.
- Обратный проход (backward pass): отдельная модель-оптимизатор анализирует результаты, выявляя паттерны успешных и неудачных действий.
- Обновление: оптимизатор предлагает небольшие текстовые правки (добавить, удалить, заменить).
Ключевой элемент системы — строгая валидация. Новая версия навыка принимается только в том случае, если она показывает лучший результат на проверочном наборе данных. Отклоненные правки сохраняются, чтобы модель не повторяла своих ошибок в будущем.
Figure 2. The SkillOpt pipeline: trajectory collection, minibatch reflection, bounded text updates, validation gating, and epoch-wise slow/meta updates jointly constrain skill training.
Анализ
Результаты тестирования SkillOpt демонстрируют значительный потенциал подхода. Метод был проверен на шести бенчмарках, семи различных моделях и трех режимах выполнения, показав лучшие результаты во всех 52 тестовых сценариях.
Особенно важно то, что SkillOpt стирает границы между моделями разных размеров. Например, компактная открытая модель Qwen3.5-4B с оптимизированным файлом навыков превзошла базовую версию более мощной модели GPT-5.2 без таких навыков. Более того, созданные таким образом навыки оказались универсальными: их можно переносить между моделями разного размера и различными агентными средами (например, из Codex в Claude Code), и они продолжают повышать эффективность.
Перспектива
SkillOpt указывает на новый, более легковесный путь адаптации ИИ-агентов под конкретные задачи. Вместо дорогостоящего дообучения весов (fine-tuning) или бесконечного ручного подбора промптов, команды разработчиков смогут тренировать компактный, версионируемый слой навыков на естественном языке. Если этот процесс контролируется и валидируется, текстовый навык становится стабильным и переносимым адаптером между базовыми возможностями больших моделей и реальными бизнес-задачами.