Создание агентов для визуального дизайна: опыт платформы Moda
Как платформа Moda использует мультиагентную систему на базе Deep Agents и LangSmith для создания редактируемых визуальных материалов.
Обновлено:
3 мин чтения
2 просмотров
Как платформа Moda использует мультиагентную систему на базе Deep Agents и LangSmith для создания редактируемых визуальных материалов.
3 мин

Платформа Moda разработала подход к созданию визуального дизайна с помощью искусственного интеллекта, который кардинально отличается от привычной генерации изображений. Вместо создания статичных картинок, система использует мультиагентную архитектуру на базе фреймворка Deep Agents для работы на полностью редактируемом двумерном векторном холсте. Это позволяет людям без навыков дизайна создавать профессиональные презентации и маркетинговые материалы в режиме диалога с ИИ, подобно тому, как программисты пишут код в редакторе Cursor.
Исторически большие языковые модели (LLM) плохо справлялись с задачами визуального дизайна. Успех ИИ в генерации программного кода во многом обусловлен тем, что технологии вроде HTML и CSS уже имеют встроенные абстракции для компоновки, такие как Flexbox или Grid. Программист или ИИ описывает отношения между элементами, а не их точные пиксельные координаты.
Moda chat
В визуальном дизайне подобного стандарта нет. Ближайший аналог — это спецификация XML для PowerPoint, которой уже около 40 лет. Она перегружена избыточными данными и абсолютными координатами X и Y. Языковые модели крайне плохо оперируют такими математическими абстракциями, поэтому инструменты, пытающиеся напрямую работать с XML, выдают шаблонные и неестественные результаты.
Для решения этой проблемы инженеры Moda разработали собственный предметно-ориентированный язык (DSL). Этот слой представления контекста дает агенту чистое и компактное понимание того, что находится на холсте. Вместо сырых координат модель получает абстракции компоновки, которыми она способна эффективно манипулировать. Это не только повышает качество дизайна, но и значительно снижает затраты на токены.
Архитектура системы включает трех специализированных агентов:
Процесс обработки запроса начинается с этапа предварительной сортировки (triage), где быстрая и дешевая модель определяет формат задачи и загружает необходимые инструкции. В памяти основного агента постоянно находятся лишь 12-15 базовых инструментов. Остальные 30+ инструментов подгружаются динамически только тогда, когда они действительно нужны. Это позволяет использовать кеширование промптов и экономить вычислительные ресурсы.
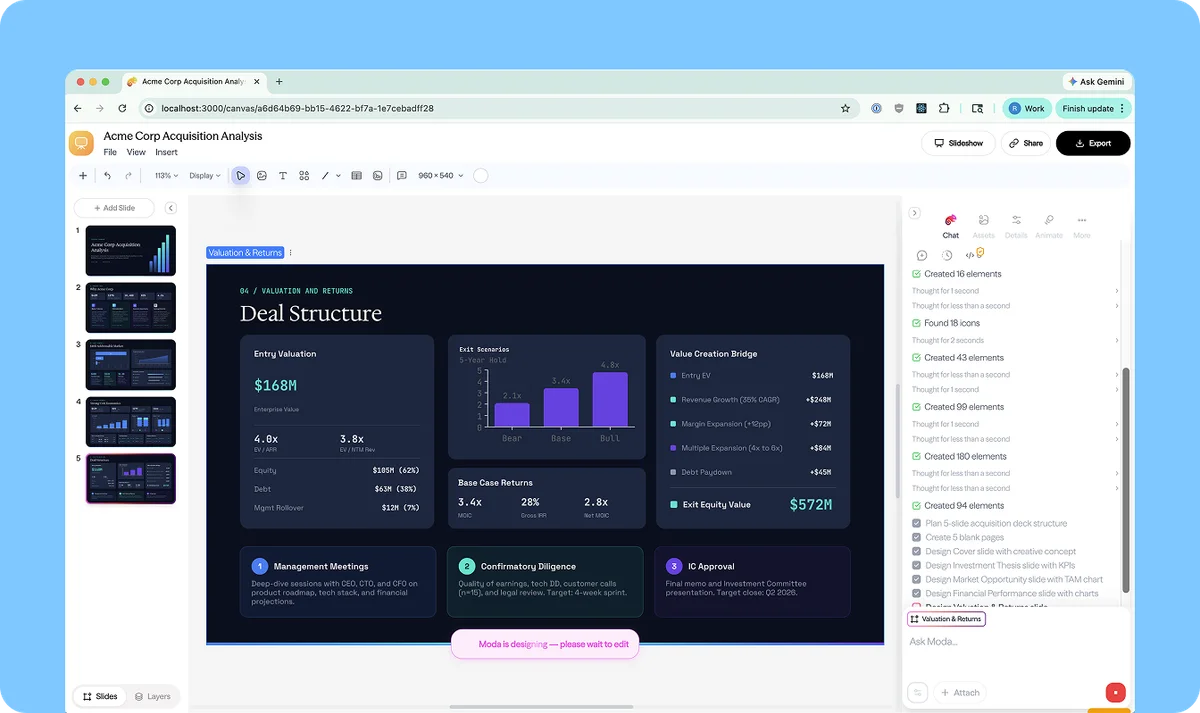
Изображение из источника
Ключевое наблюдение из опыта Moda заключается в изменении пользовательского взаимодействия. Переход от концепции "сгенерировать и принять/отклонить" к совместному редактированию на векторном холсте снижает психологический барьер для пользователей. ИИ формирует качественную отправную точку, а человек дорабатывает детали.
Кроме того, проект демонстрирует важность инструментов наблюдаемости (observability) при разработке сложных ИИ-систем. Использование платформы LangSmith позволило разработчикам Moda отслеживать каждый шаг агентов, анализировать затраты токенов на каждом узле системы и выявлять ошибки в вызовах инструментов до того, как они повлияют на пользователя.
Успех подобных систем в корпоративном сегменте показывает, что будущее генеративного дизайна лежит не в создании статичных пикселей, а в генерации структурированных, редактируемых макетов. В ближайшем будущем команда Moda планирует внедрить механизмы долгосрочной памяти для агентов и расширить поддержку мультибрендовых корпоративных клиентов. Это может стать стандартом для всех инструментов создания контента, где требуется строгое соблюдение корпоративного стиля и возможность детальной ручной настройки.
Для успешной генерации дизайна с помощью LLM необходимо переводить абсолютные пиксельные координаты в абстракции компоновки, понятные языковым моделям.
Настоящая ценность ИИ в дизайне заключается не в выдаче готового результата, а в создании интерактивной среды (подобной редакторам кода), где человек и агент совместно работают над векторным макетом.


