Суть
Компания Loka совместно с AWS продемонстрировала архитектуру нового поколения для голосовых ИИ-агентов, использующую модель Amazon Nova 2 Sonic. Переход от традиционных многоступенчатых систем к нативным моделям обработки речи (speech-to-speech) позволил решить главную проблему индустрии — неестественные задержки в общении, которые приводили к отказам клиентов и росту затрат на поддержку.
Контекст
Традиционные голосовые помощники опираются на каскадный процесс из трех шагов. Сначала система переводит речь в текст (Speech-to-Text), затем текст обрабатывается большой языковой моделью (LLM), и, наконец, текстовый ответ синтезируется обратно в голос (Text-to-Speech).
Этот конвейер неизбежно накапливает задержки на каждом этапе, что часто приводит к паузам от 3 до 5 секунд перед ответом. В контексте реального телефонного разговора такая задержка разрушает естественность общения. Более того, при переводе речи в текст теряется критически важная метаинформация: тон голоса, эмоции, паузы и срочность. Наконец, поддержка таких систем в масштабах крупных предприятий становится экономически нецелесообразной из-за высоких вычислительных затрат на потоковую обработку аудио.
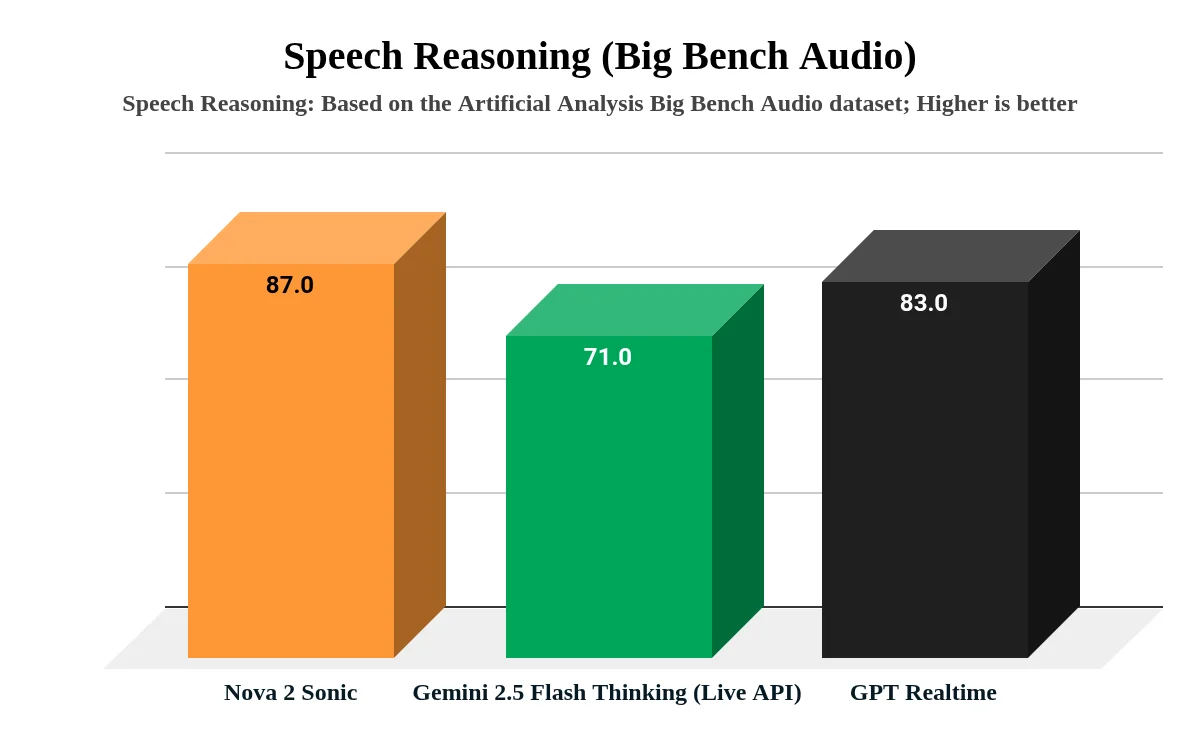
Speech reasoning scores comparison across models on Big Bench Audio benchmark
Детали
Новый подход заключается в отправке аудиопотока напрямую в модель, которая выполняет понимание, логический вывод и генерацию ответа как единая система.
Результаты тестирования Amazon Nova 2 Sonic показывают значительный прогресс:
- В тесте Big Bench Audio (оценка логики по аудиовходу) модель набрала 87.0 баллов, опередив GPT Realtime (83.0) и Gemini 2.5 Flash Native Audio (71.0).
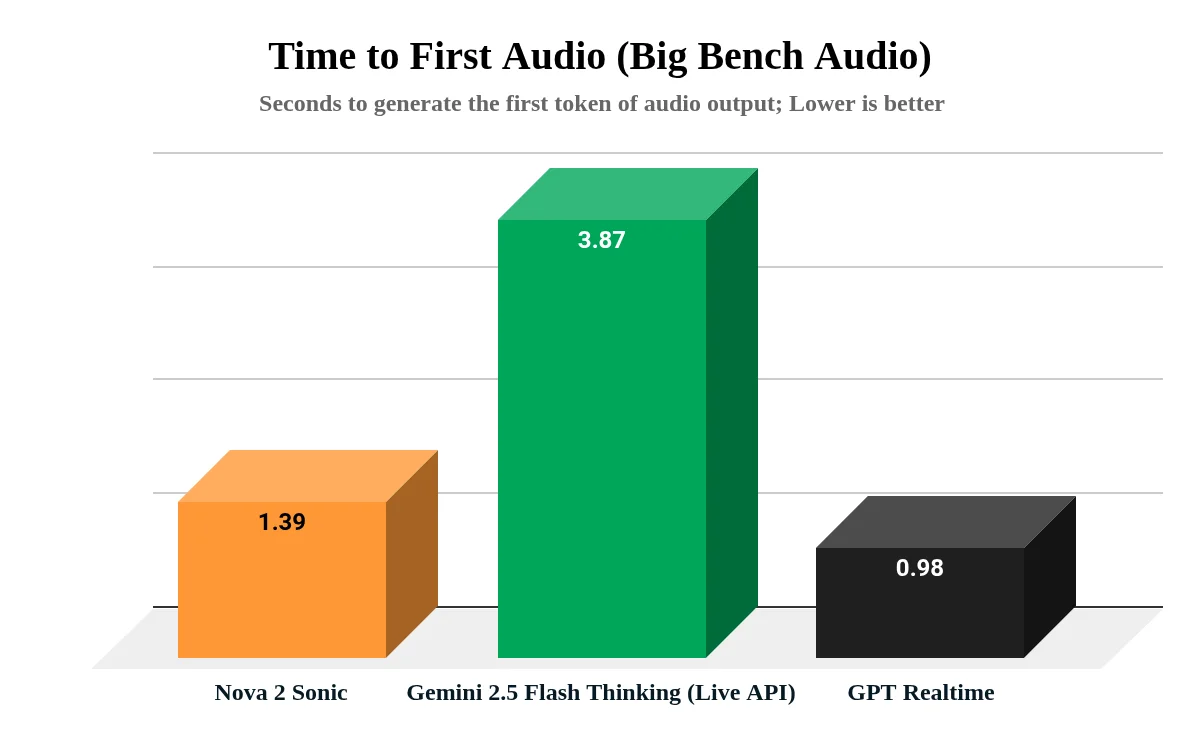
- Время до первого звука (Time to First Audio) составило всего 1.39 секунды, что позволяет пользователям естественно перебивать агента.
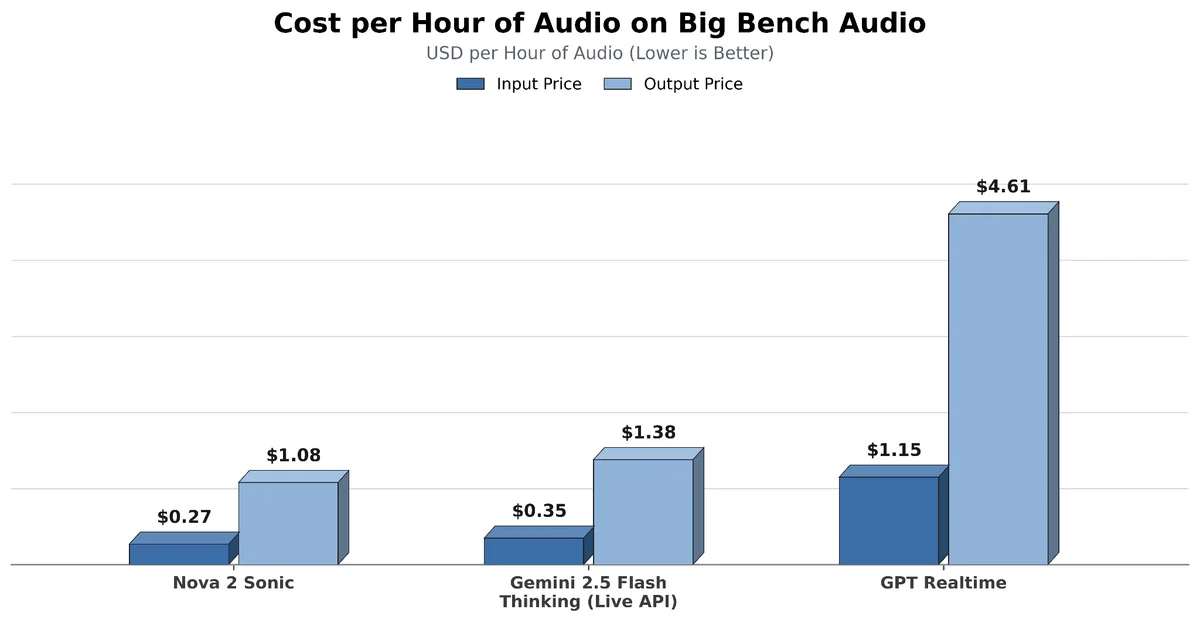
- Стоимость обработки составляет около 0.27 доллара за час входящего аудио, что существенно ниже традиционных методов.
Разработчики также применили автоматизированную систему оценки качества диалогов с использованием LLM в качестве судьи (LLM-as-a-judge). Путем итеративного улучшения системных подсказок (промптов) общую оценку качества диалога удалось поднять с базовых 2.7 до 3.8 баллов из 5.
Анализ
Time to first audio comparison across models on Big Bench Audio benchmark
Этот кейс наглядно показывает, что разработка голосовых агентов переходит из фазы экспериментов в стадию промышленной эксплуатации. Использование нативных аудиомоделей устраняет компромисс между интеллектом системы и скоростью ее реакции.
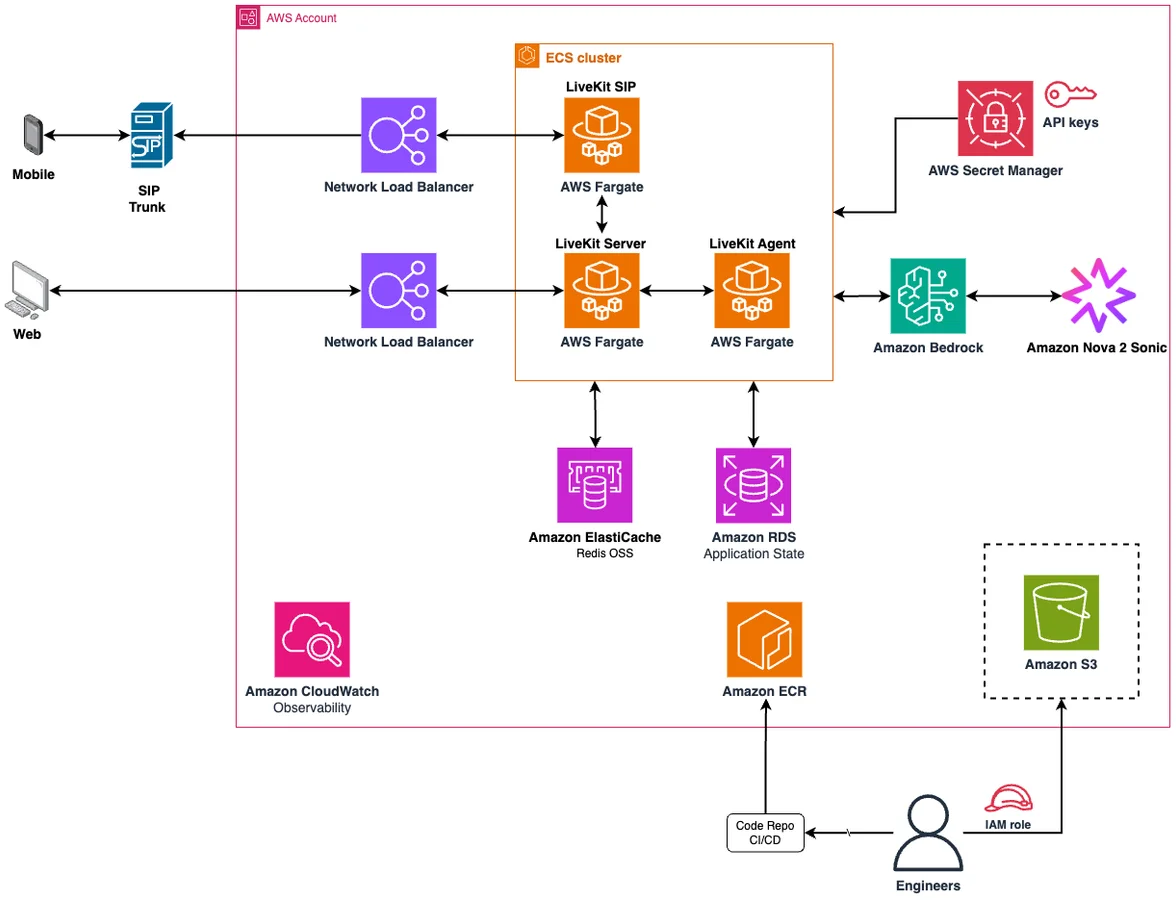
Интересно, что инженерия подсказок для таких моделей требует новых навыков. Разработчикам пришлось внедрять строгие правила очередности реплик, контроль повторений и чек-листы самопроверки модели перед ответом. Архитектура решения также потребовала использования специализированных транспортных слоев, таких как LiveKit, для абстрагирования сложностей протоколов WebRTC и SIP.
Перспектива
Тестирование на крайних случаях (edge cases) выявило как сильные, так и слабые стороны текущего поколения моделей. В то время как система отлично справляется со спешащими или раздраженными клиентами (оценка 4.5-5.0), она все еще испытывает трудности с пространными, долгими монологами, характерными для пожилых или очень общительных людей.
В ближайшем будущем можно ожидать полного отказа индустрии от каскадных систем в пользу нативных мультимодальных решений для задач реального времени. Фокус разработчиков сместится с оптимизации задержек на улучшение долгосрочной памяти агентов и их способности структурировать хаотичные пользовательские запросы.