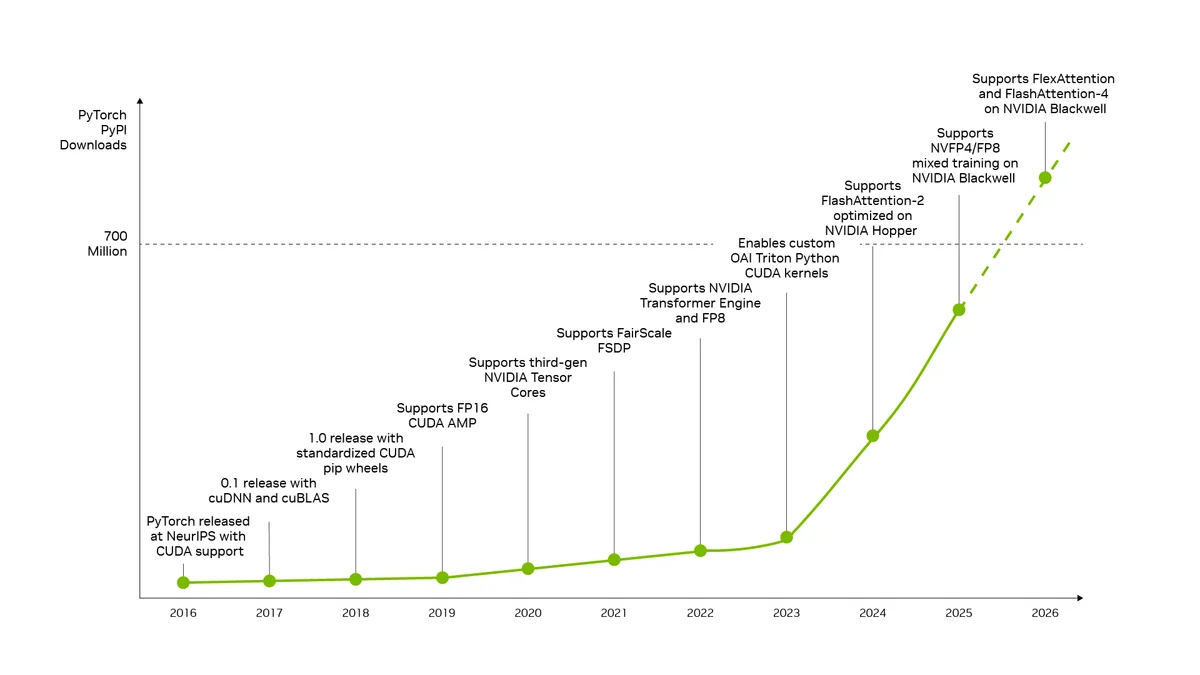
По мере перехода организаций от пилотных проектов к производственным фабрикам искусственного интеллекта, критерии оценки инфраструктуры меняются. Если раньше главным показателем были пиковые характеристики чипов, то теперь фокус сместился на стоимость токена: сколько полезных вычислений можно получить на каждый вложенный доллар, ватт энергии и в рамках заданных лимитов задержки. Программное обеспечение становится ключевым инструментом в этой оптимизации.
Контекст: сложность агентских систем
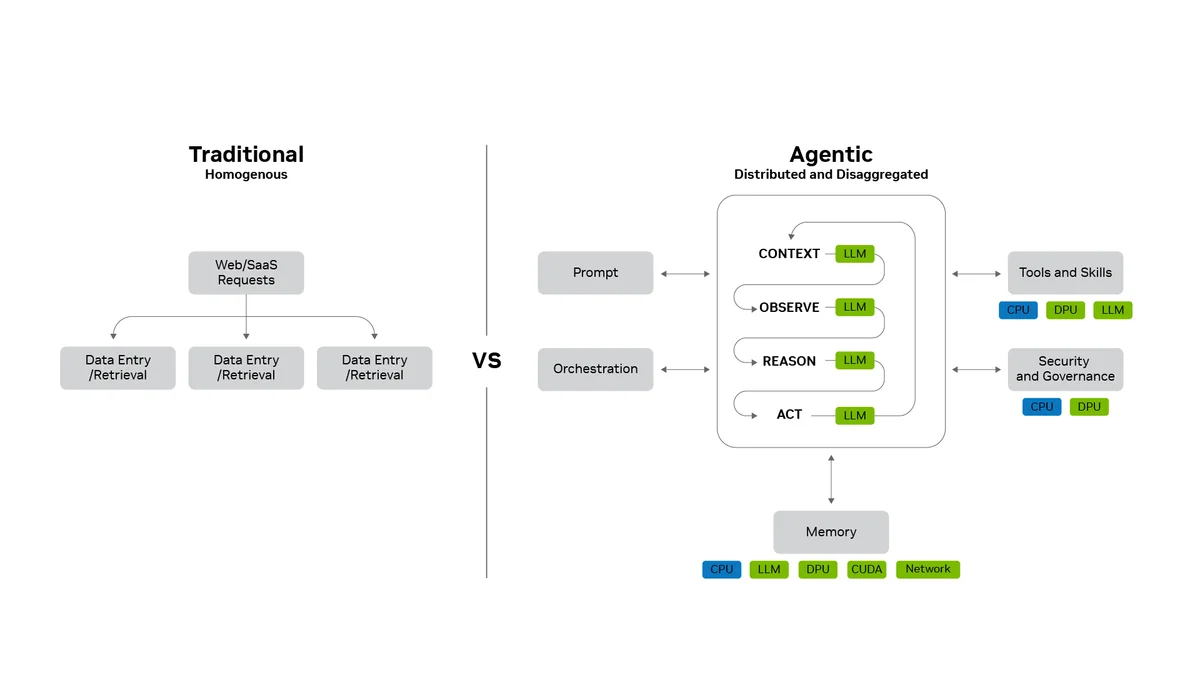
Традиционные веб-нагрузки и облачные сервисы были предсказуемыми. Запросы следовали схожим маршрутам и масштабировались простым добавлением идентичных серверов. Агентский ИИ (agentic AI) устроен иначе. Он запускает распределенные процессы, которые охватывают большие языковые модели (LLM), инструменты памяти, безопасность и сетевые ресурсы дата-центра.
Агенты способны рассуждать, планировать задачи, вызывать специализированные инструменты и управлять огромным контекстом в ходе многошаговых процессов. Один запрос пользователя может превратиться в распределенную вычислительную задачу для сотен субагентов и тысяч подзадач, выполняющихся на множестве графических (GPU) и центральных процессоров (CPU). Без правильного программного обеспечения эта сложность ведет к колоссальной потере вычислительных мощностей и росту издержек.
Детали: три уровня оптимизации
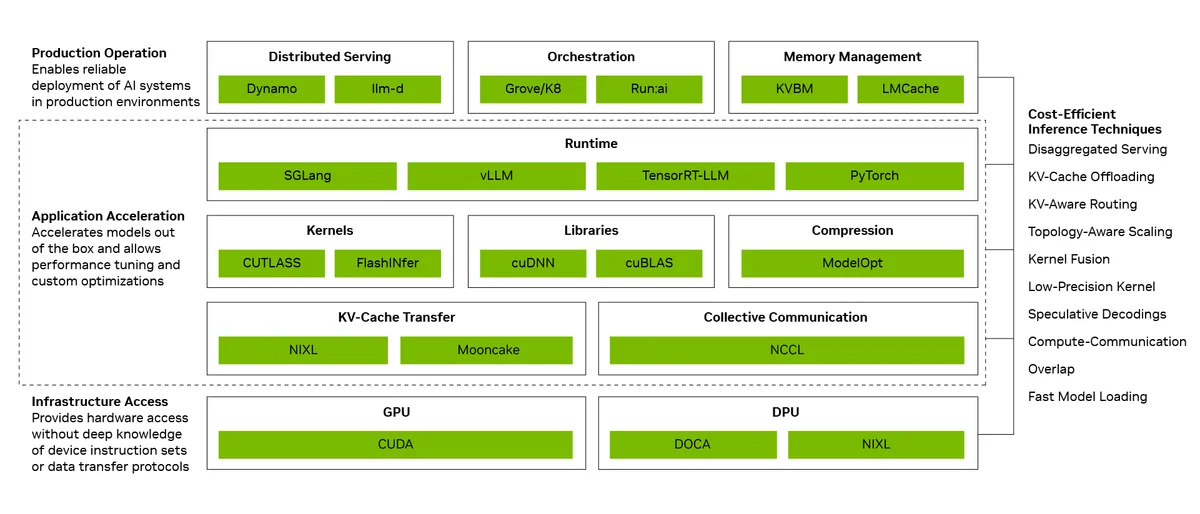
Программный стек инференса (inference software stack) NVIDIA решает эту проблему, объединяя три критически важных уровня:
- Производственные операции. Координируют распределенное обслуживание, автомасштабирование и управление памятью, чтобы вычисления происходили на оптимальных ресурсах.
- Ускорение приложений. Позволяет разработчикам настраивать модели с помощью таких оптимизаций времени выполнения, как слияние ядер и параллельное выполнение вычислений.
- Доступ к инфраструктуре. Открывает возможности GPU, сетей и памяти без необходимости прямого управления каждой инструкцией оборудования.
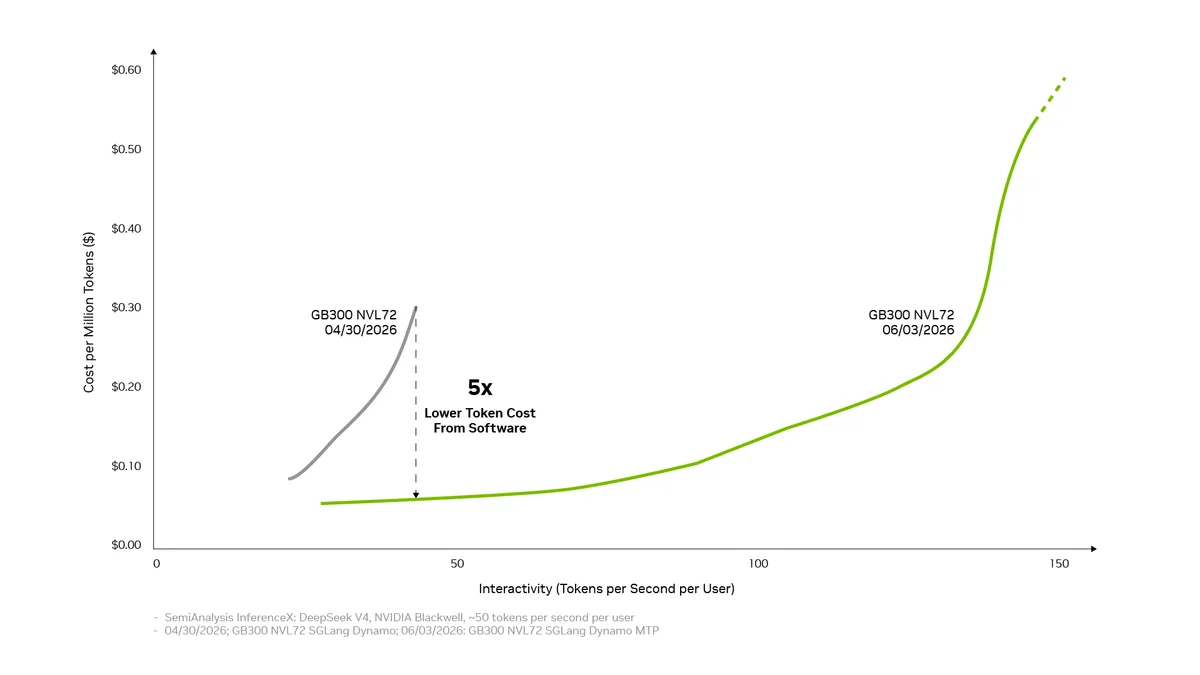
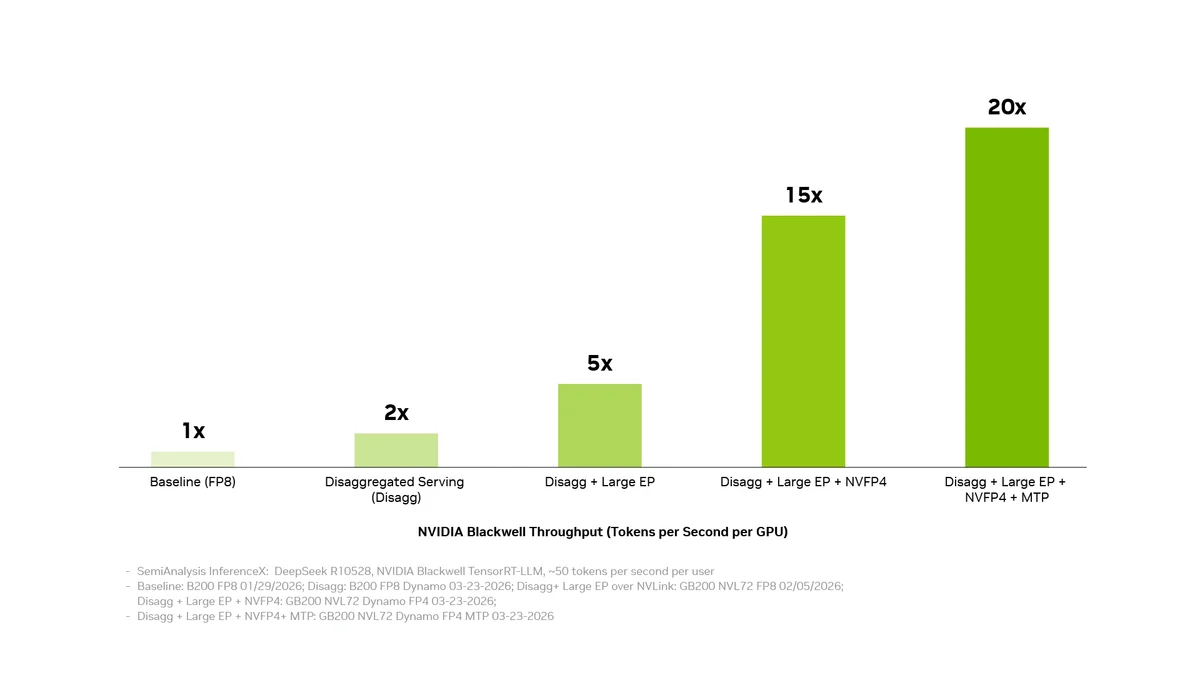
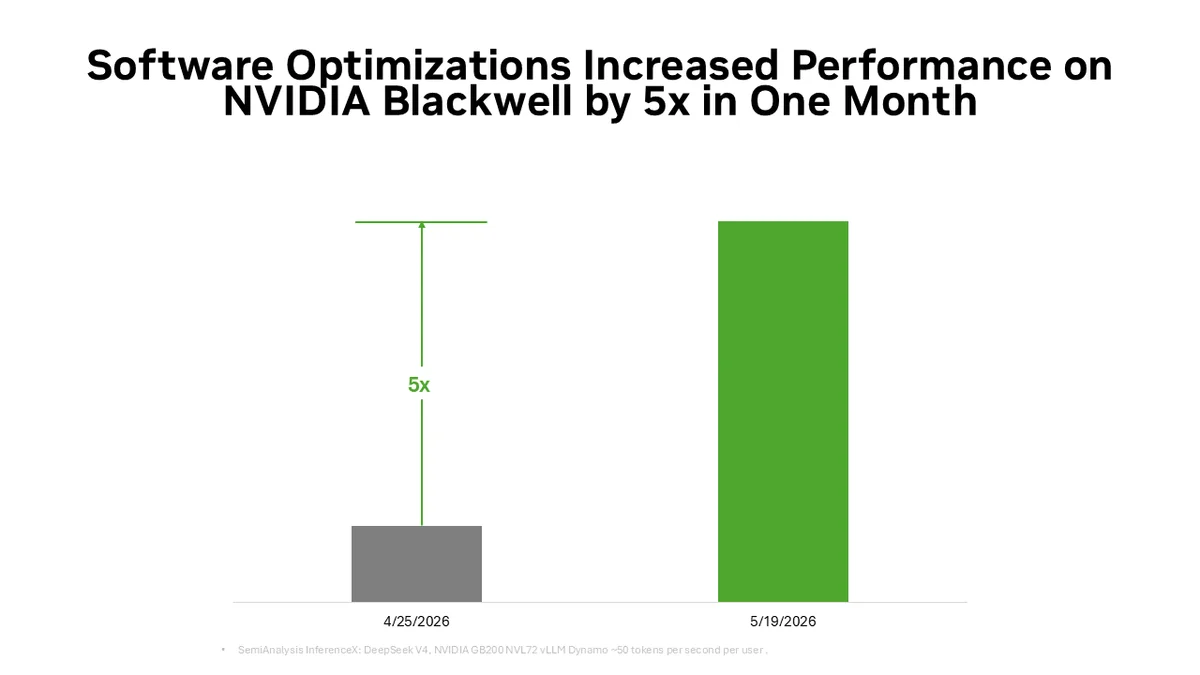
На платформе NVIDIA Blackwell этот комплексный подход уже продемонстрировал результаты. Затраты на генерацию токенов для модели DeepSeek V4 были снижены до пяти раз всего за один месяц использования. Комбинация таких технологий, как дезагрегированное обслуживание, масштабный параллелизм экспертов, точность вычислений NVFP4 и предсказание нескольких токенов, в совокупности способна увеличить пропускную способность оборудования до 20 раз.
Компании уже используют эти преимущества. Например, Baseten применяет библиотеку TensorRT-LLM для обслуживания DeepSeek V4 Pro, получая на 50% больше токенов в секунду, а Cognition использует фреймворк Dynamo для масштабирования рабочих нагрузок обучения с подкреплением.
Анализ: эффект открытого кода
Важную роль в этом процессе играет экосистема открытого исходного кода (open source). Многие популярные ИИ-фреймворки изначально создаются на базе архитектуры NVIDIA CUDA. Это означает, что новые исследовательские решения с первого дня работают с высокой производительностью на оборудовании компании.
Когда на рынке появляется новая передовая модель, фреймворки вроде vLLM и SGLang уже имеют готовые сценарии ее развертывания. Возникает накопительный эффект: чем больше разработчиков оптимизируют пути инференса, тем больше улучшений возвращается в экосистему. Каждое программное обновление увеличивает объем выдаваемых токенов и снижает их удельную стоимость.
Перспектива
По мере усложнения ИИ-моделей аппаратное обеспечение будет оставаться важнейшим, но все же фундаментом. Главная конкуренция развернется на программном уровне. Способность инфраструктурных решений заставить различные слои оптимизации работать как единое целое станет определяющим фактором для компаний, стремящихся сделать искусственный интеллект экономически выгодным в промышленных масштабах.