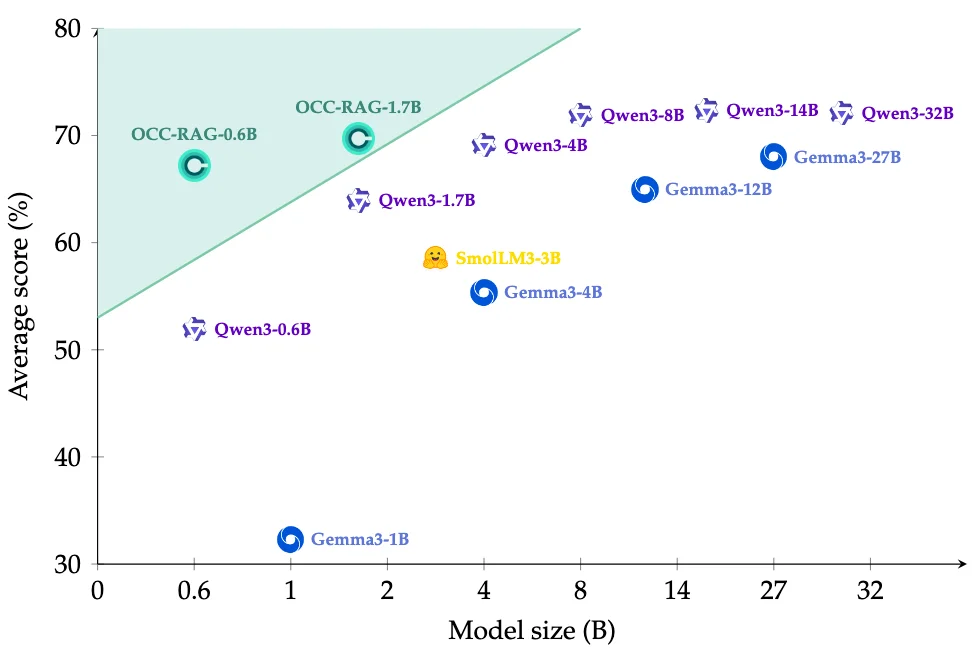
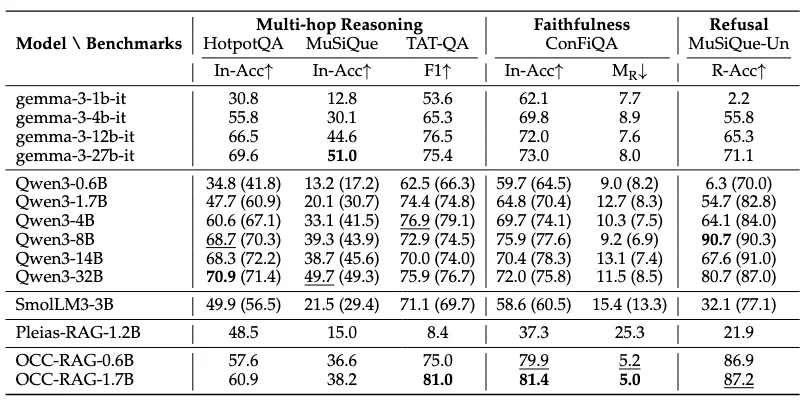
Команда Optimal Cognitive Core (OCC) из исследовательского института AIRI представила новое семейство компактных языковых моделей — OCC-RAG. Выпущены две версии с 0.6 и 1.7 миллиардами параметров. Главная особенность этих моделей заключается в том, что они оптимизированы специально для задач контекстного ответа на вопросы (Context QA) и показывают результаты на уровне моделей общего назначения, которые превосходят их по размеру в несколько раз.
В последние годы развитие искусственного интеллекта шло по пути увеличения масштаба: чем больше параметров, тем больше энциклопедических знаний модель может удержать в своих весах. Однако на практике бизнесу редко нужна модель-эрудит. Гораздо чаще требуется система, способная проанализировать предоставленный ей корпоративный документ, финансовый отчет или базу знаний, и дать точный ответ строго на основе этого текста.
Рис. 1. Трейд‑офф «качество / размер»: OCC‑RAG-0.6B и 1.7B против Qwen3, Gemma3, SmolLM3.
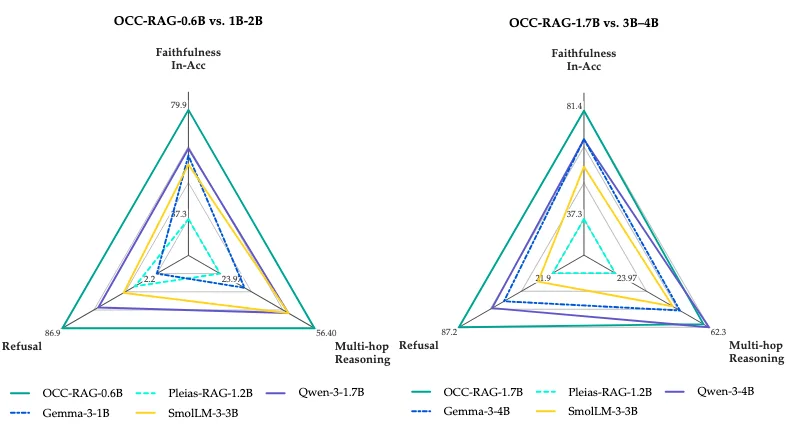
Ключевое требование к таким системам — верность контексту (faithfulness). Модель должна опираться только на предоставленные источники. Если информация в документе противоречит общеизвестным фактам или обновляется, система обязана следовать документу. Большие языковые модели (LLM) часто страдают от того, что доверяют своей внутренней параметрической памяти больше, чем тексту в запросе, что приводит к искажениям или галлюцинациям.
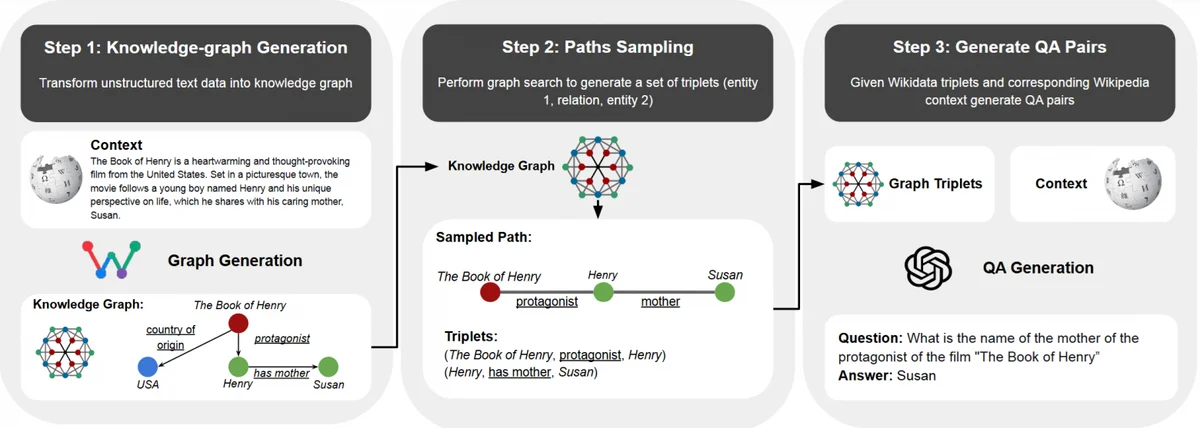
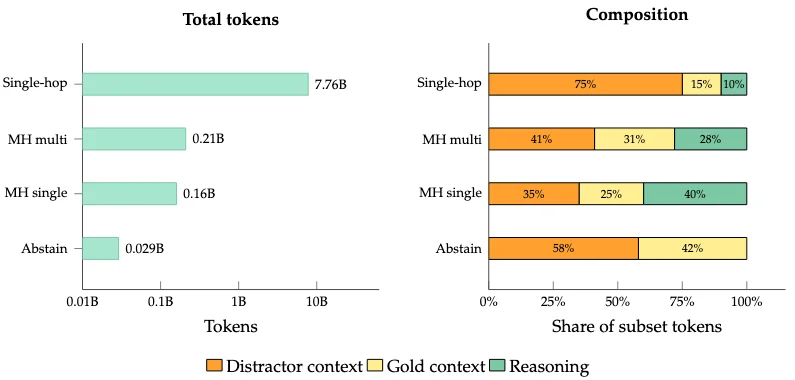
Чтобы решить эту проблему в компактном размере, исследователи из AIRI применили комплексный подход. Во-первых, они создали масштабный синтетический набор данных объемом около 3.25 миллиона пар вопросов и ответов. Для генерации сложных вопросов использовались графы знаний, что позволило обучить модель многошаговым рассуждениям (multi-hop reasoning) — способности собирать итоговый ответ из разрозненных фактов в разных частях текста.
Во-вторых, в процессе обучения разработчики внедрили строгий формат рассуждений. Ответ модели OCC-RAG всегда состоит из пяти секций: анализ запроса, анализ источников, цепочка рассуждений, статус (дискретный вердикт о том, хватает ли информации для ответа) и сам ответ. Такой подход делает логику системы прозрачной и позволяет ей вовремя остановиться, честно ответив «информации недостаточно», вместо того чтобы выдумывать факты.
Рис. 2. Faithful / Truthful / Hallucination на примере конфликта «контекст ↔ память».
Отдельного внимания заслуживает работа с многошаговыми рассуждениями в условиях нескольких источников (multi-context). Разработчики выяснили, что если модель учится связывать факты только внутри одного документа, она плохо справляется с реальными сценариями поисковой генерации (RAG), где нужные данные разбросаны по разным файлам. Добавление специализированных примеров, где факты искусственно разнесены по разным источникам, дало существенный прирост качества.
Появление таких моделей, как OCC-RAG, подчеркивает важный сдвиг в индустрии. Для решения конкретных прикладных задач, связанных с обработкой внутренних документов, больше не обязательно разворачивать огромные и дорогие модели на 70 миллиардов параметров. Компактные, целенаправленно обученные системы могут обеспечивать более высокую надежность и проверяемость ответов.
В перспективе мы увидим рост популярности малых языковых моделей (SLM), которые можно запускать локально, на недорогом оборудовании, обеспечивая при этом полную конфиденциальность данных. Подход AIRI с формализацией цепочки рассуждений доказывает, что когнитивные способности модели зависят не только от количества параметров, но и от качества обучающих данных и архитектуры процесса вывода.