Компания OpenAI представила GeneBench-Pro — новый масштабный бенчмарк, созданный для оценки способностей систем искусственного интеллекта в области вычислительной биологии. Этот инструмент направлен на проверку того, насколько хорошо ИИ-агенты справляются с задачами исследовательского уровня, где требуется не просто следование заданному алгоритму, но и способность принимать решения в условиях неопределенности.
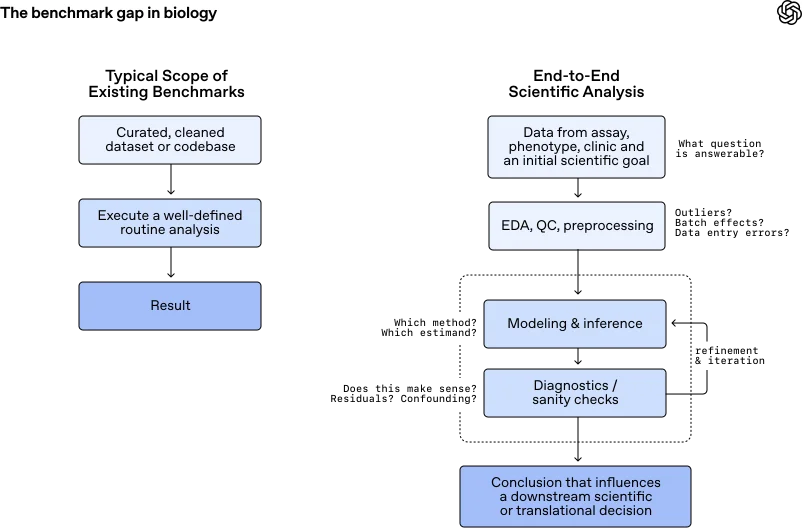
В реальной научной практике данные редко сопровождаются подробными инструкциями. Исследователям приходится самостоятельно определять, является ли наблюдаемый паттерн биологической закономерностью или просто шумом, достаточен ли объем данных для ответа на поставленный вопрос, и как полученные промежуточные результаты должны влиять на дальнейший ход эксперимента. Современные модели искусственного интеллекта все лучше справляются со сложным анализом, однако настоящая наука требует навыков высокоуровневого суждения.
Diagram titled “The benchmark gap in biology” comparing traditional benchmark workflows with end-to-end scientific analysis, showing additional steps such as preprocessing, modeling, diagnostics, and iterative refinement before reaching a scientific conclusion.
GeneBench-Pro расширяет возможности предыдущей версии бенчмарка, предлагая более сложные и реалистичные задачи в таких областях, как геномика, количественная биология и трансляционная медицина. До сих пор существовало мало убедительных методов оценки того, как системы ИИ справляются с системными решениями: пересмотром гипотез, выбором правильного пути анализа и пониманием того, когда результат готов к практическому применению. Эти навыки трудно формализовать, и поэтому их сложно строго оценивать.
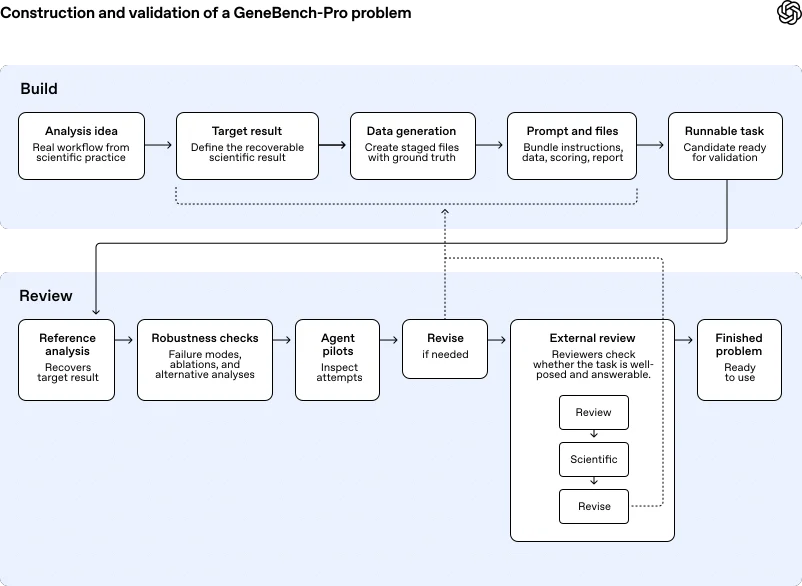
В рамках GeneBench-Pro вводится понятие «исследовательского вкуса» (research taste) — цепочки решений, определяющих ход анализа. Каждая задача в бенчмарке предоставляет модели реалистичный набор данных с шумами, краткий экспериментальный контекст и целевой параметр, связанный с последующим решением. Для успешного выполнения задачи ИИ должен исследовать данные, выбрать подходящий аналитический подход, провести итеративные эксперименты и выдать финальный ответ.
Набор данных включает 129 задач, охватывающих 10 основных доменов и 21 поддомен, таких как статистическая генетика, популяционная генетика, регуляторная омика и клиническая диагностика. Важной особенностью GeneBench-Pro является то, что все задачи созданы синтетически. Разработчики полностью контролируют процесс генерации данных и причинно-следственные связи. Это позволяет избежать проблем традиционных бенчмарков, где оценка может зависеть от субъективных предпочтений авторов или где модель может получить правильный ответ, используя алгоритмические уязвимости.
Diagram titled “Construction and validation of a GeneBench-Pro problem,” showing a workflow from building a runnable task through review, robustness checks, agent testing, expert review, revision, and a finished benchmark problem.
Каждая задача представляет собой изолированную рабочую среду, в которой агент получает доступ к данным и стандартному стеку биоинформатических инструментов (включая Python и библиотеки вроде PLINK 2.0). Оценка производится детерминированно на основе известных целевых значений, что исключает вариабельность, связанную с выбором конкретной модели или многословностью ответов, характерную для стандартных методов оценки.
OpenAI привлекла внешних экспертов — аспирантов, исследователей и профессоров — для оценки 82 из 129 задач. Эксперты подтвердили высокую сложность и реалистичность заданий, отметив, что они требуют вдумчивого анализа и понимания потенциальных подводных камней, с которыми сталкиваются исследователи в реальной практике.
Десять репрезентативных задач из GeneBench-Pro будут опубликованы в открытом доступе на платформе Hugging Face, что позволит научному сообществу детально изучить новый инструмент. Появление таких бенчмарков указывает на стремление индустрии создавать ИИ-системы, способные выступать в роли полноценных помощников-исследователей, а не просто инструментов для обработки данных.