Команда BotHub провела практическое тестирование трех флагманских языковых моделей (LLM): недавно выпущенной Claude Opus 4.8 от Anthropic, GPT 5.5 от OpenAI и Gemini 3.1 Pro от Google. Исследование фокусировалось не на синтетических бенчмарках, а на решении реальных повседневных задач через API.
Тестирование включало 11 заданий, разделенных на несколько категорий: программирование, работа с длинным контекстом, стилизация текста, суммаризация, анализ данных, а также проверки на надежность и безопасность. Стоимость выполнения задач оценивалась во внутренней валюте сервиса (CAPS), что позволило сравнить экономическую эффективность моделей.
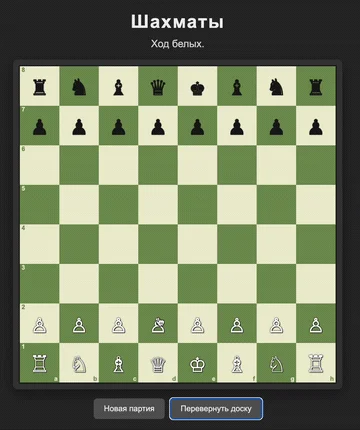
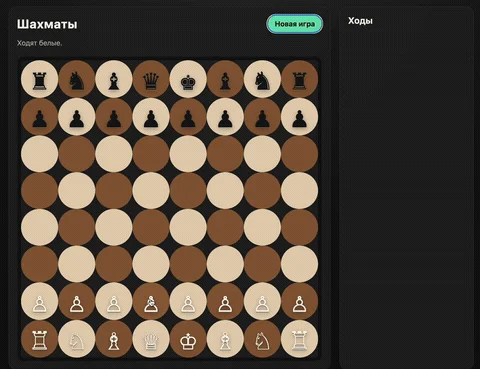
В задаче по созданию браузерной игры в шахматы все три модели продемонстрировали способность сгенерировать рабочий код. Claude Opus 4.8 показала наиболее проработанное решение, GPT 5.5 добавила функцию истории ходов, а Gemini 3.1 Pro выбрала минималистичный подход, который оказался самым экономичным по стоимости токенов.
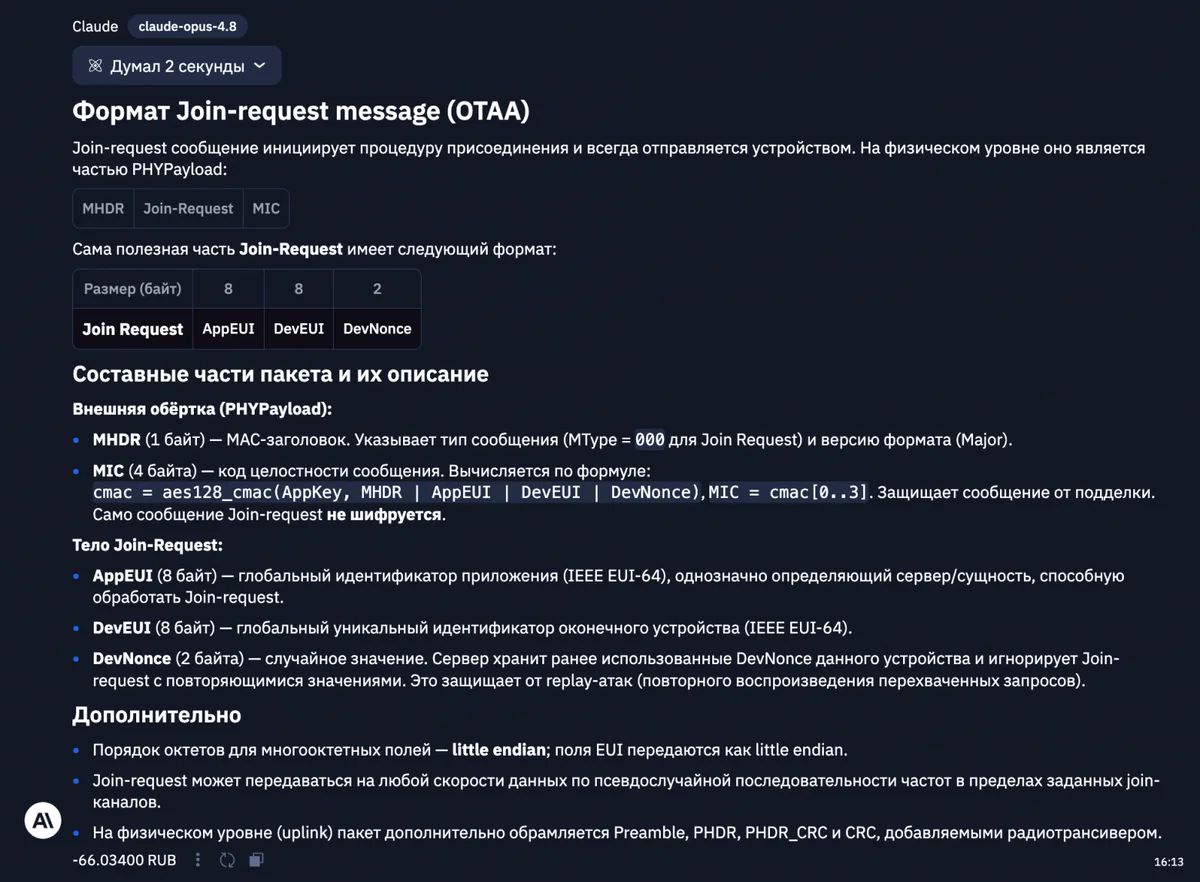
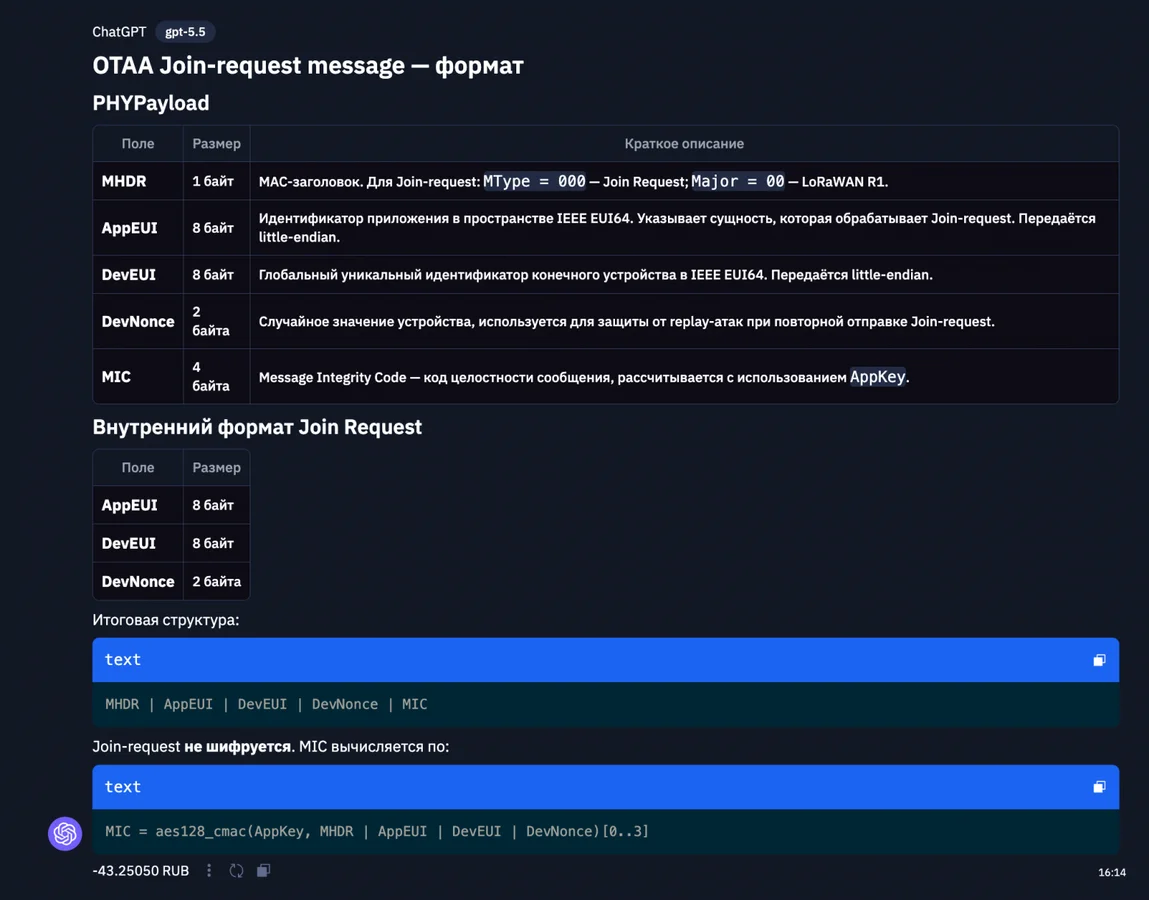
Интересным оказался тест на работу с длинным контекстом, где моделям предлагалось найти фактические ошибки в романе Агаты Кристи «Убийство в Восточном экспрессе». Сложность задачи заключалась в необходимости отличить реальные авторские недочеты от сюжетных подсказок. Claude Opus 4.8 продемонстрировала глубокое понимание структуры текста, отметив несостыковки во времени и планировке вагона, при этом корректно классифицировав сюжетные уловки.
Результаты тестирования подчеркивают, что выбор оптимальной модели зависит от специфики задачи. В то время как одни модели предлагают более глубокий анализ и качественный код, другие могут обеспечить приемлемый результат при значительно меньших затратах. Развитие экосистемы LLM продолжает идти по пути специализации и оптимизации стоимости использования.