Одной из главных проблем современных ИИ-агентов при длительной работе является потеря контекста. Когда агент накапливает недели или месяцы истории взаимодействий, стандартный семантический поиск начинает давать сбои. Если пользователь просит найти "проблемы с оплатой", система может выдать вперемешку технические тикеты, диалоги о продажах и реальные споры по счетам.
Это происходит потому, что семантический поиск находит все, что близко по смыслу, но не учитывает критически важные бизнес-измерения: тип проблемы, статус или время. Для решения этой задачи Amazon Web Services представила механизм фильтрации с помощью метаданных в сервисе Bedrock AgentCore Memory.
Ранее разработчики решали проблему изоляции данных с помощью пространств имен (namespaces). Этот подход позволяет отделить данные одного клиента от данных другого. Однако по мере роста объема памяти внутри одного пространства имен релевантные сигналы начинают тонуть в семантически похожих, но контекстуально неверных результатах. Например, агент финансовой компании не может отличить высокоприоритетный разговор о ребалансировке портфеля, состоявшийся на прошлой неделе, от рутинного запроса трехмесячной давности.
Funnel showing retrieval narrowing from 10,000+ memory records to a namespace scope of about 500 records, then a metadata filter to about 100 records, then semantic search returning the top 10 matches
Фильтрация по метаданным работает как дополнительный слой над пространствами имен. Она позволяет сузить область поиска по таким параметрам, как приоритет, отдел или временной диапазон, еще до запуска семантического поиска.
Внутренние тесты Amazon на наборе из 151 вопроса (в формате многосессионных диалогов) показали значительный рост метрик. Общая точность ответов (QA accuracy) выросла с 40% до 64%. При этом для вопросов, зависящих от контекстных границ (например, поиск с ограничением по времени или фильтрация по приоритету), точность подскочила с 16% до 69%.
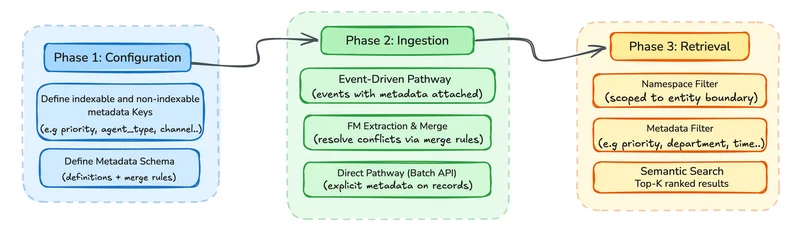
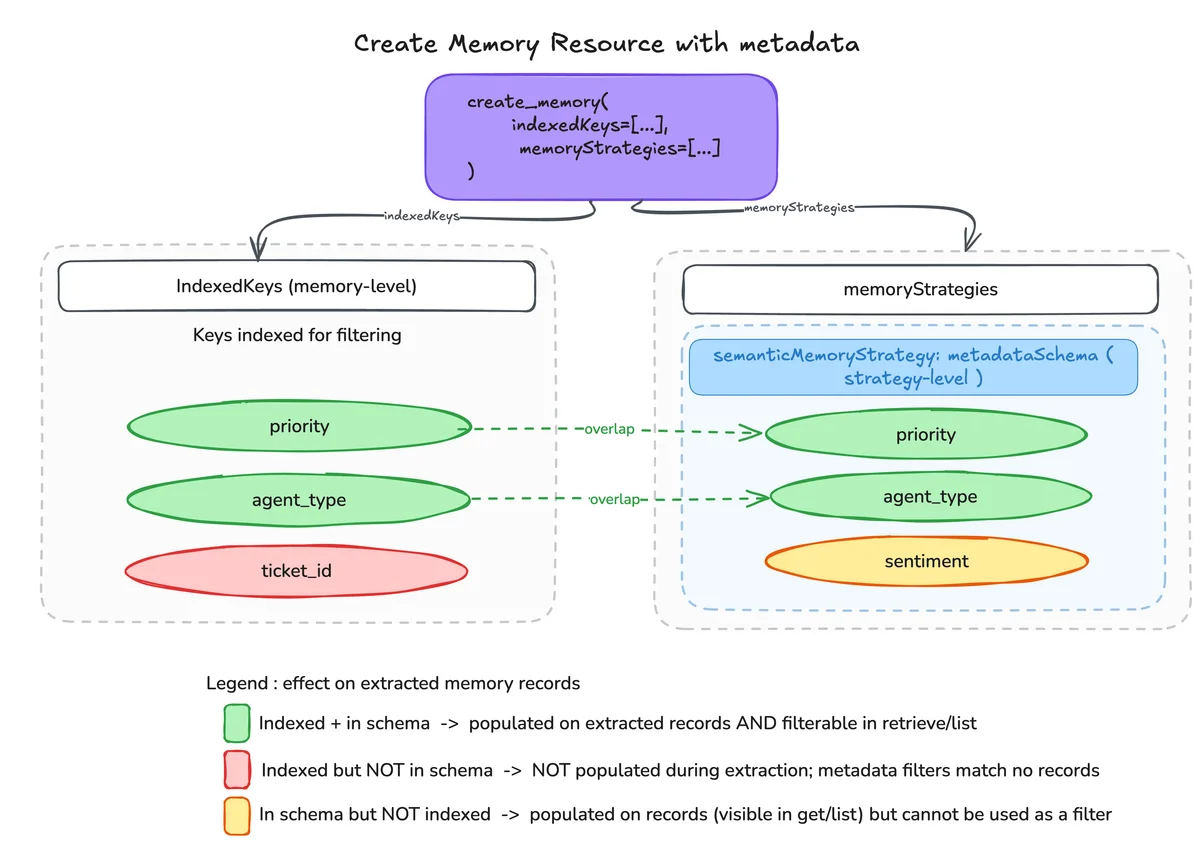
Работа с метаданными в AgentCore Memory делится на три этапа: конфигурация, поглощение (ingestion) и извлечение (retrieval). На этапе конфигурации разработчик определяет схему метаданных. Ключи, которые планируется использовать для фильтрации, индексируются для быстрого поиска.
Three-phase metadata lifecycle: Phase 1 configuration defines indexable keys and the metadata schema, Phase 2 ingestion attaches metadata through event-driven and Batch API pathways, and Phase 3 retrieval applies namespace and metadata filters before semantic search
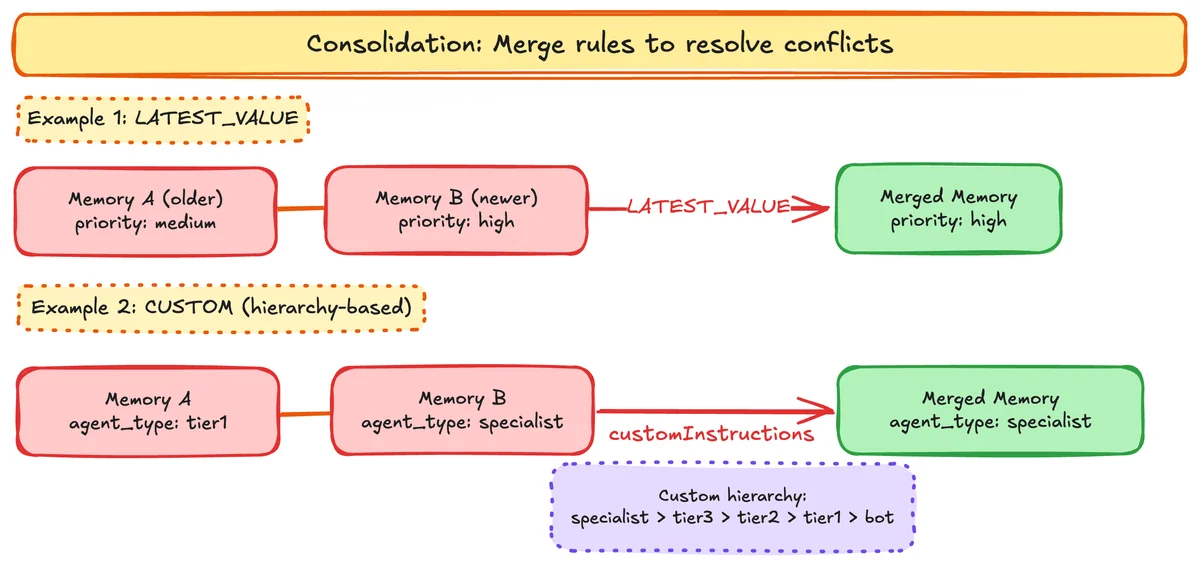
Интересной особенностью является использование больших языковых моделей (LLM) для автоматического извлечения метаданных из диалогов. Разработчик может задать инструкции для модели, объясняя, как именно нужно классифицировать информацию. Например, можно поручить модели определять тональность клиента (позитивная, нейтральная, негативная) на основе его реплик.
Для данных, которые известны заранее (например, отдел или тип взаимодействия), предусмотрен режим строгого соответствия (STRICTLY_CONSISTENT). В этом случае значения передаются в память без изменений, и языковая модель не привлекается для их повторного вывода. Это исключает вариативность, когда одно и то же слово может быть записано по-разному в разных записях.
Внедрение структурированных метаданных демонстрирует важный сдвиг в индустрии. Разработчики осознают, что чистого векторного поиска недостаточно для создания надежных корпоративных ИИ-систем. Гибридный подход, объединяющий классическую структурированную фильтрацию и семантический поиск, становится стандартом де-факто.
В будущем мы увидим еще более сложные архитектуры памяти для ИИ-агентов. Они будут напоминать полноценные реляционные базы данных, где языковые модели будут выступать не только как генераторы текста, но и как интеллектуальные маршрутизаторы и классификаторы информации.