Индустрия искусственного интеллекта подошла к важному рубежу: технологии машинного обучения теперь активно применяются для проектирования и производства самого оборудования, на котором этот ИИ будет работать. Ведущие тайваньские производители электроники интегрировали программный стек NVIDIA для ускорения выпуска инфраструктуры следующего поколения — Vera Rubin NVL72.
Этот процесс демонстрирует формирование замкнутого цикла. Вычислительные мощности используются для создания еще более совершенных вычислительных мощностей, что позволяет сократить сроки вывода новых продуктов на рынок и оптимизировать производственные издержки.
Тайвань исторически является центром мировой полупроводниковой промышленности. Здесь сосредоточено более 500 партнеров экосистемы, а компоненты для новых серверных стоек собираются на 25 различных заводах. Традиционные методы планирования фабрик и контроля качества перестали справляться с текущими темпами роста спроса на вычислительную инфраструктуру.
Для решения этой проблемы компании внедряют концепцию физического ИИ (physical AI) и цифровых двойников (digital twins). Это позволяет тестировать изменения в виртуальной среде до их физической реализации, избегая дорогостоящих ошибок на реальном производстве.
Каждый из ключевых игроков тайваньского рынка использует специфические инструменты для своих задач. Компания TSMC применяет библиотеки вычислительной литографии, что позволяет улучшить показатели экономической эффективности и времени цикла на 20-50% по сравнению с традиционными методами на базе центральных процессоров. Симуляция полупроводниковых материалов при этом ускоряется в среднем в 50 раз.
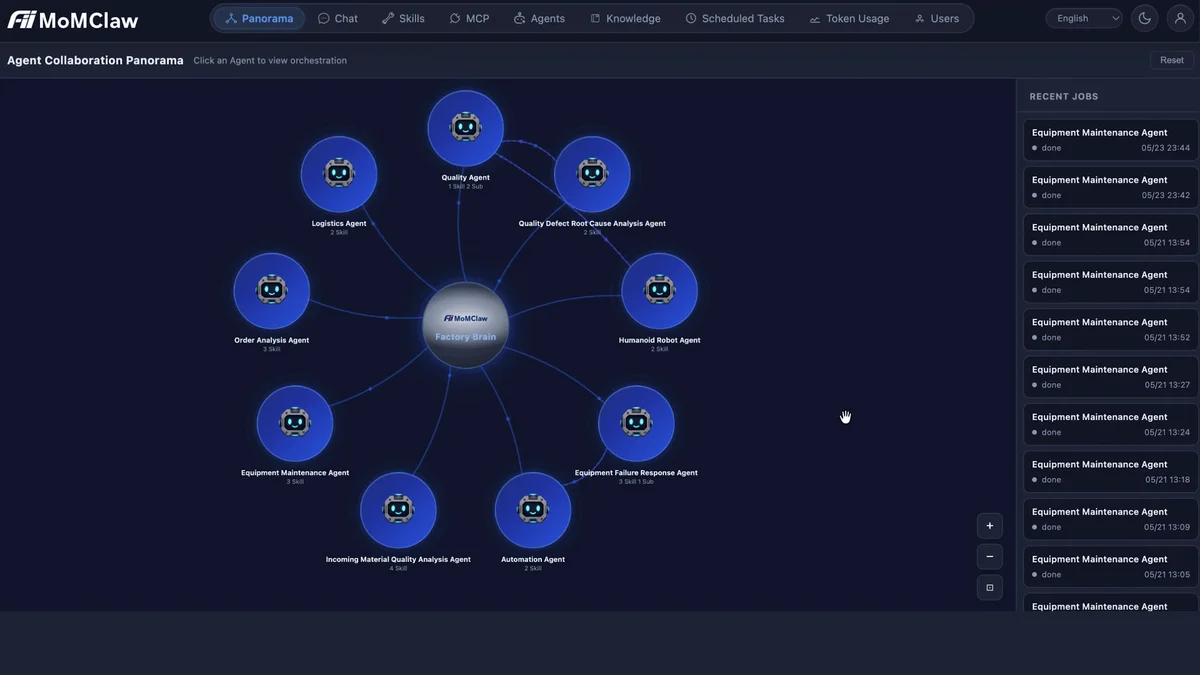
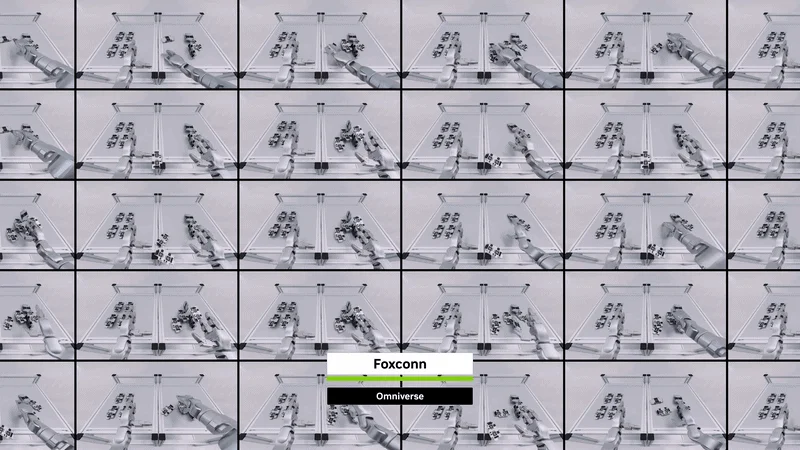
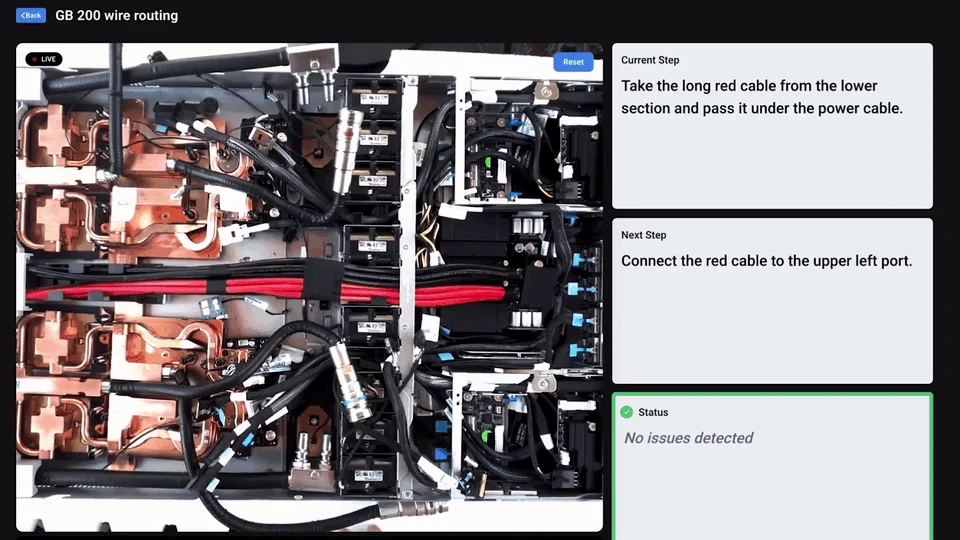
Foxconn внедряет специализированных ИИ-агентов для управления производственными операциями. Подключение датчиков к системе с интерфейсом на естественном языке позволило ускорить анализ первопричин сбоев на 80% и повысить производительность труда на 15%. Кроме того, компания активно тестирует колесных гуманоидных роботов для задач высокоточной сборки.
Производители серверов Wistron и Quanta Cloud Technology (QCT) используют платформы для создания цифровых двойников заводов. Виртуальное моделирование расположения стоек и тепловых потоков позволяет Wistron ускорить анализ планировки на 70% и снизить энергопотребление объектов на 20%.
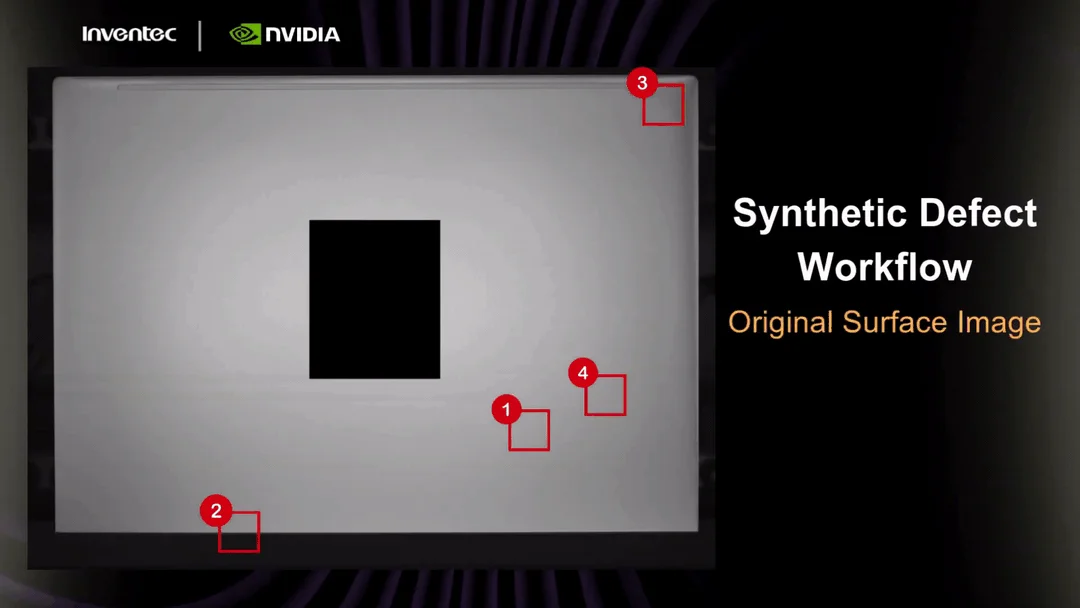
Компании Pegatron и Inventec нашли применение генеративному ИИ в сфере контроля качества. Они используют синтетические данные — искусственно сгенерированные изображения дефектов — для обучения систем автоматической оптической инспекции. Это снижает потребность в ручной разметке реального брака на 30% и сокращает время развертывания систем визуального контроля на месяцы.
Случай Тайваня показывает, что искусственный интеллект выходит за рамки программных продуктов и становится ядром тяжелой промышленности. Использование симуляций и синтетических данных решает главную проблему производства — высокую стоимость ошибки при запуске новых линий.
По мере того как архитектура Vera Rubin будет выходить на полную производственную мощность, этот высокоавтоматизированный подход станет индустриальным стандартом. В ближайшие годы конкурентное преимущество на рынке оборудования будет определяться не только доступом к кремнию, но и тем, насколько глубоко алгоритмы интегрированы в повседневные заводские процессы.