Суть
Индустрия искусственного интеллекта преодолела важный рубеж: передовые возможности больших языковых моделей (LLM) теперь доступны прямо в вашем кармане. Недавно компания Google представила Gemma 4 E4B — бесплатную модель, которая по своим характеристикам сопоставима с GPT-4o, но при этом работает полностью локально на мобильном телефоне. Это событие подчеркивает фундаментальный сдвиг: флагманские технологии больше не остаются привилегией огромных дата-центров надолго.
Контекст
Всего два года назад идея полезного искусственного интеллекта на смартфоне казалась фантастикой. Стандартные голосовые помощники с трудом справлялись с базовыми командами, а ранние попытки запускать локальные модели приводили к генерации бессмысленного текста и быстрой разрядке батареи. Сегодня ситуация изменилась радикально. Технологический разрыв между самыми мощными серверными решениями и потребительскими устройствами стремительно сжимается.
Детали
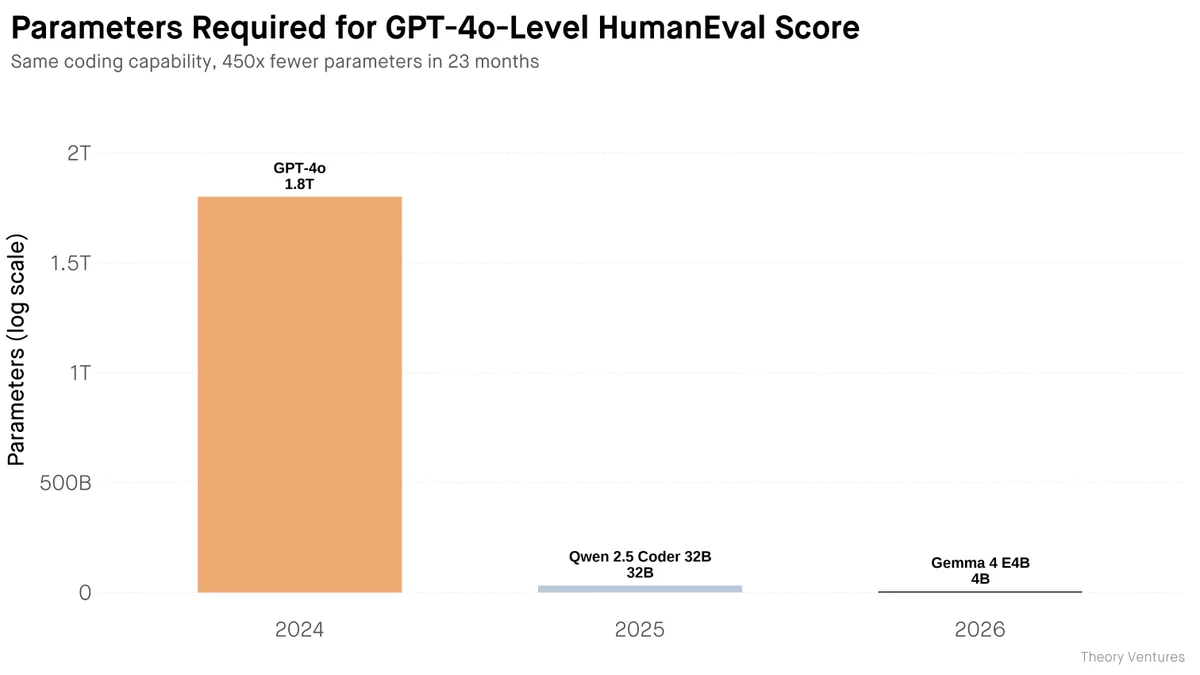
Цифры, стоящие за этим прогрессом, впечатляют. Путь от состояния «передового рубежа» (state of the art) до работы на обычном смартфоне теперь занимает всего 23 месяца. Промежуточный этап — запуск на ноутбуке — достигается еще быстрее, за три-четыре месяца.
Главный технический прорыв заключается в беспрецедентном сжатии. Вычислительная мощность и качество ответов, для которых ранее требовалась модель на 1.8 триллиона параметров, теперь умещаются в архитектуру размером всего 4 миллиарда параметров. Это означает сжатие в 450 раз без критической потери качества. Модель Gemma 4 E4B успешно конкурирует с серверными решениями в сложных тестах, включая математику и программирование.
Parameters Required for GPT-4o-Level HumanEval Score : 450x compression in 23 months
Анализ
Такая скорость оптимизации не возникает сама по себе. За ней стоят три мощные силы, формирующие современный рынок искусственного интеллекта:
Во-первых, совершенствование алгоритмов. Методы дистилляции (переноса знаний от большой модели к малой) и обучение с подкреплением позволяют втиснуть максимум интеллектуальных возможностей в минимальное количество параметров.
Во-вторых, беспрецедентная концентрация талантов. Самые быстрорастущие компании в истории программного обеспечения привлекают лучших исследователей и инженеров со всего мира, создавая высокую плотность интеллекта внутри команд.
В-третьих, колоссальный капитал. Триллионы долларов инвестируются в центры обработки данных, которые обеспечивают вычислительную базу для первоначального обучения этих моделей.
Перспектива
Гонка локальных моделей только начинается. В ближайшие недели рынок ожидает релизов компактных и мощных нейросетей от других крупных игроков, таких как DeepSeek, Qwen, Kimi и Minimax.
Для обычных пользователей это означает изменение парадигмы владения устройствами. Учитывая текущие темпы сжатия алгоритмов, телефон, который сейчас лежит в вашем кармане, сможет запускать сегодняшние флагманские модели еще до того, как вы решите заменить его на новый. Вычислительная мощность переходит из облака на устройство, обеспечивая приватность, скорость работы и независимость от интернет-соединения.