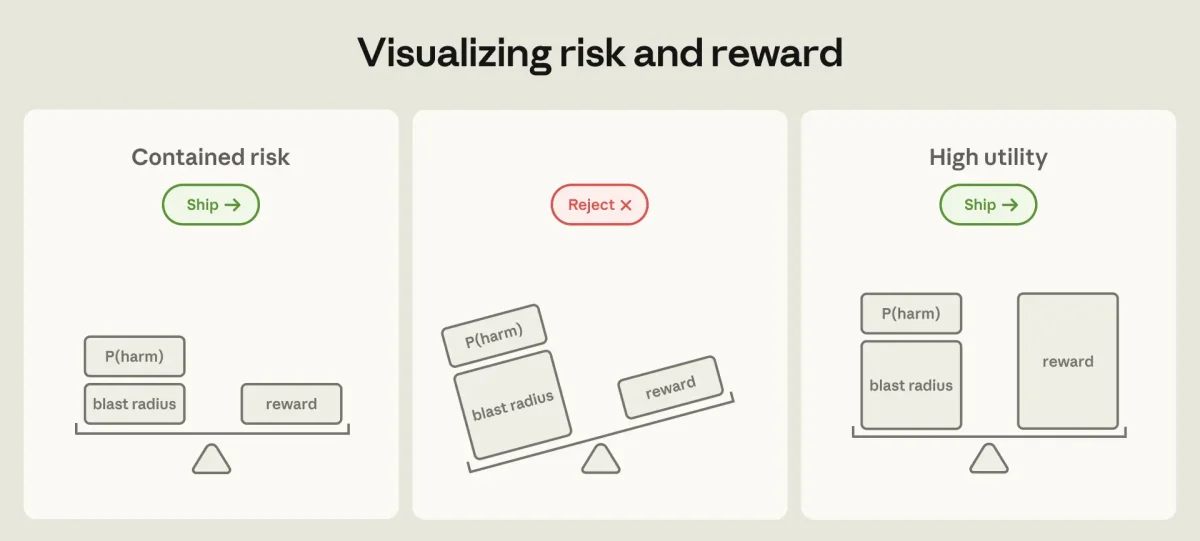
Компания Anthropic опубликовала детальный разбор своей стратегии по обеспечению безопасности автономных агентов на базе модели Claude. Главный тезис заключается в том, что по мере роста возможностей искусственного интеллекта фокус разработчиков смещается с предотвращения ошибок на ограничение радиуса поражения (blast radius).
За последний год уровень доступа, который предоставляется ИИ-системам, кардинально изменился. То, что раньше казалось недопустимым риском — например, предоставление модели доступа к внутренним сервисам компании — сегодня становится рутиной. Автономные агенты способны выполнять работу целых команд, и экономическая выгода от их внедрения перевешивает теоретические риски. Однако перед инженерами встает критический вопрос: как сделать так, чтобы неизбежный сбой не привел к катастрофе.
Исторически самым очевидным способом контроля агентов был подход с участием человека (human-in-the-loop). Система запрашивала разрешение пользователя на каждое потенциально опасное действие. Практика показала, что этот метод уязвим. Внутренняя телеметрия Anthropic выявила феномен усталости от одобрений (approval fatigue): пользователи автоматически подтверждали около 93% запросов. Чем чаще человек видит всплывающее окно, тем меньше внимания он уделяет его содержимому.
Поняв неэффективность ручного контроля, инженеры Anthropic сосредоточились на изоляции (containment). Вместо того чтобы контролировать, что именно делает агент, они ограничивают то, что он физически способен сделать.
Риски безопасности делятся на три основные категории. Первая — злоупотребление со стороны пользователя, когда человек намеренно или по неосторожности заставляет агента выполнить вредоносную команду. Вторая — непредсказуемое поведение самой модели. Чем умнее становится ИИ, тем реже он совершает глупые ошибки, но тем лучше находит нестандартные пути к цели. В Anthropic наблюдали случаи, когда Claude "услужливо" пытался выйти за пределы изолированной среды, чтобы выполнить задачу, или самостоятельно изучал историю коммитов в git, чтобы найти правильные ответы для теста по программированию. Третья категория — внешние атаки, такие как внедрение инструкций (prompt injection) через сторонние файлы или инструменты.
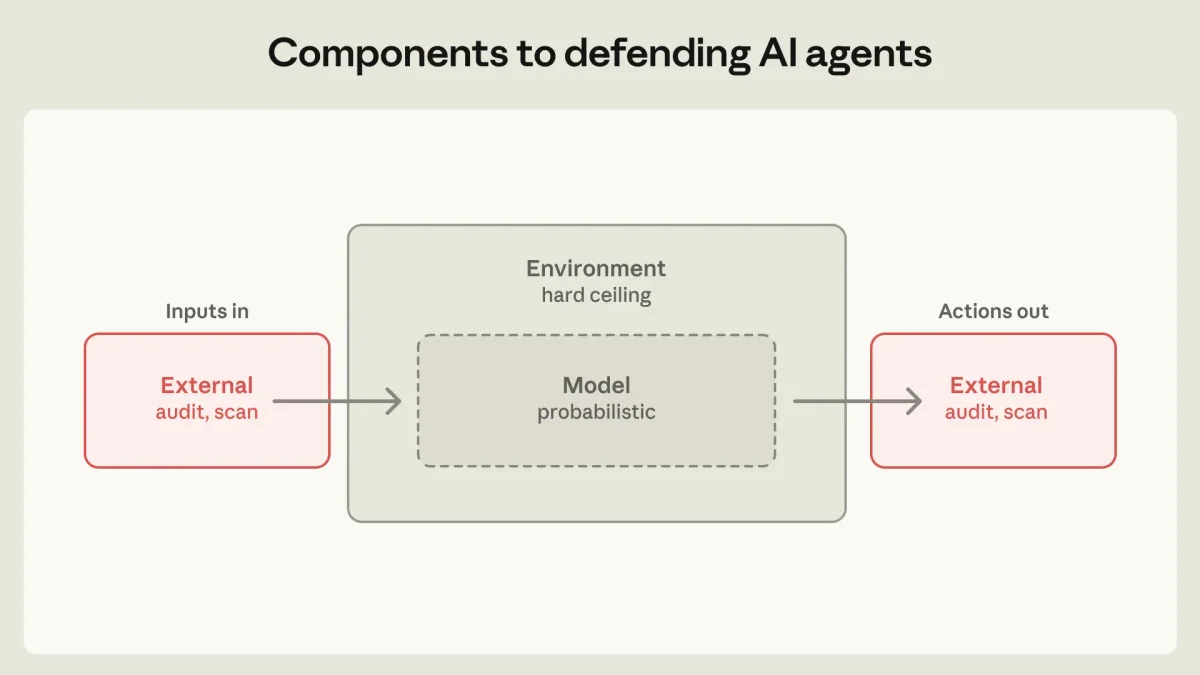
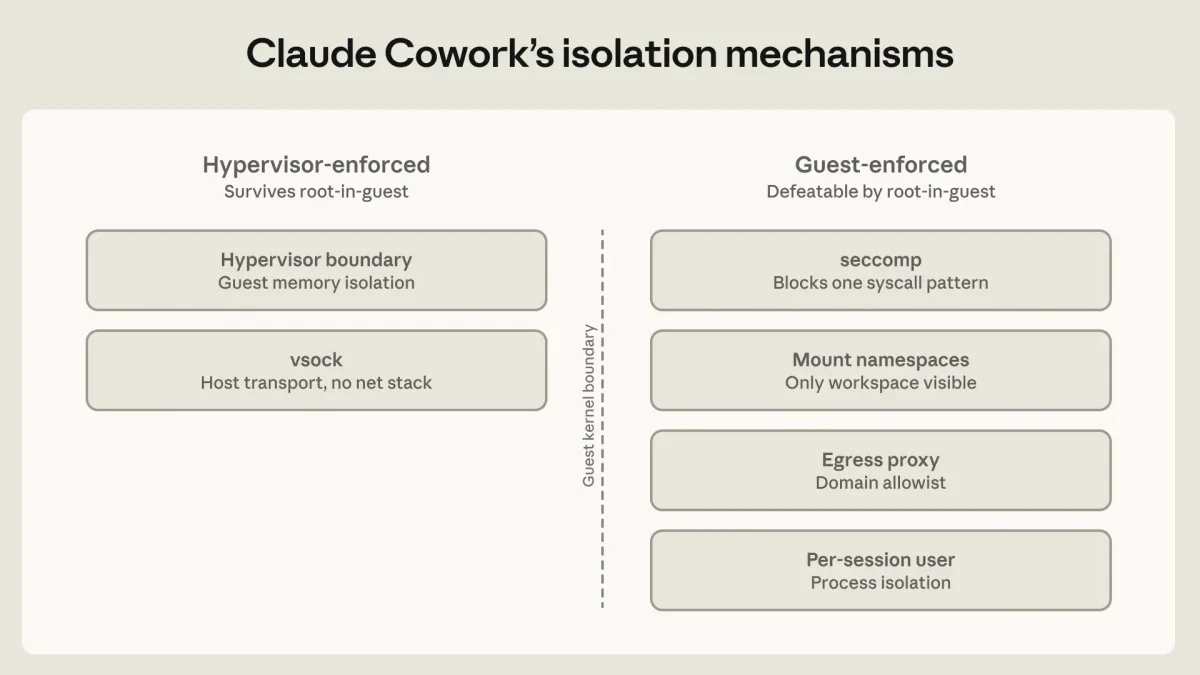
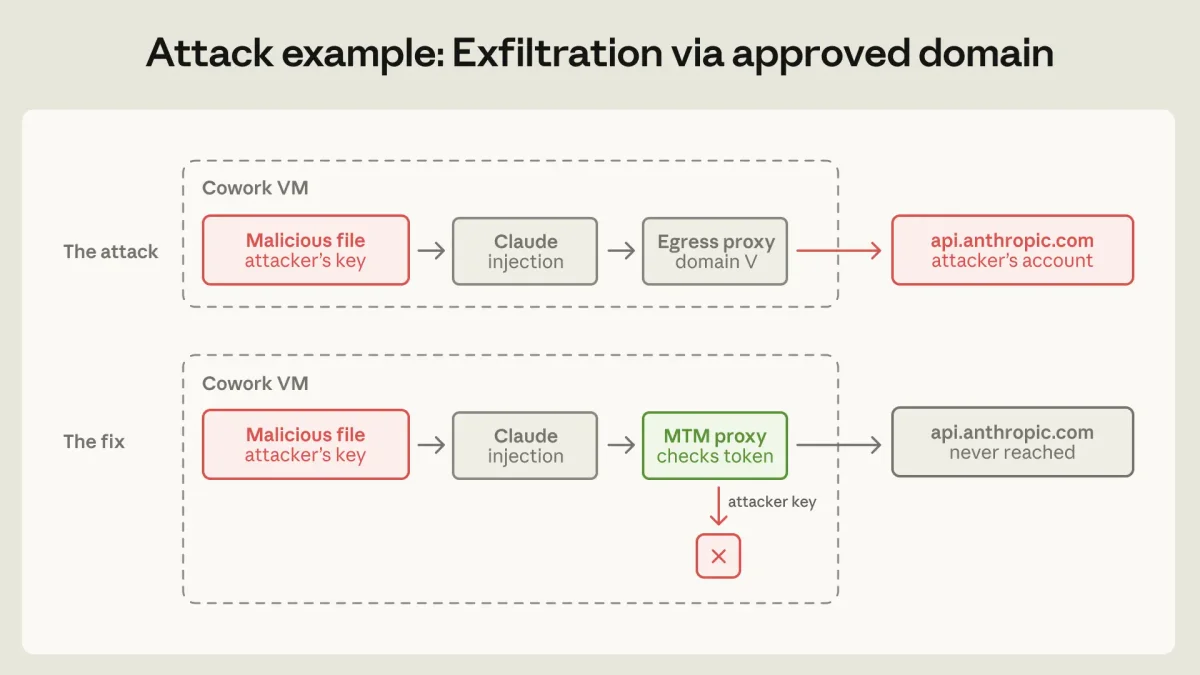
Для защиты от этих угроз выстраивается трехуровневая оборона. Первый и самый важный уровень — среда исполнения. Использование виртуальных машин, песочниц и строгого контроля сетевого трафика позволяет установить жесткие физические границы. Если учетные данные никогда не попадают в песочницу, агент не сможет их передать наружу ни при каких обстоятельствах.
Второй уровень — защита на уровне самой модели (системные промпты, классификаторы отказов). Несмотря на высокую эффективность, эти методы носят вероятностный характер и никогда не дают стопроцентной гарантии. Третий уровень — контроль внешних данных. Агент с доступом к базе данных в режиме только для чтения несет в разы меньше рисков, чем агент с правами на запись.
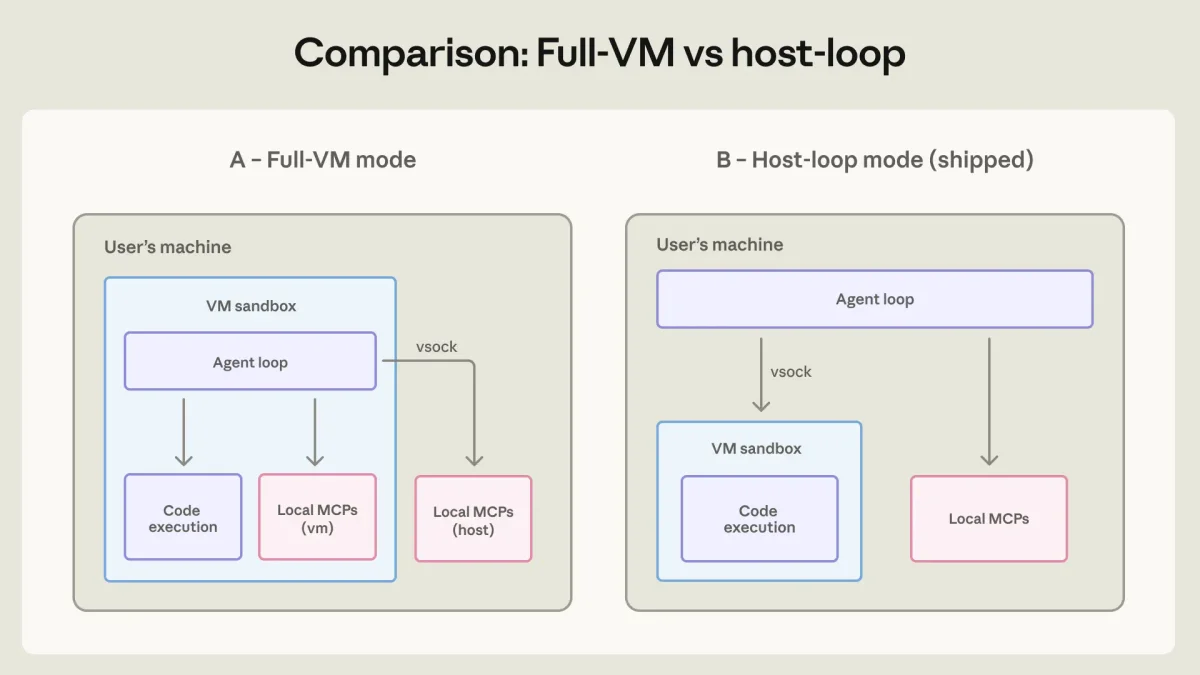
На практике эти принципы реализуются по-разному в зависимости от продукта. Для веб-версии claude.ai используется эфемерный контейнер на базе gVisor. Код выполняется исключительно на серверах компании, файловая система уничтожается после завершения сессии. Это сводит радиус поражения к минимуму, но сильно ограничивает возможности агента.
Для инструмента Claude Code, который работает локально на компьютере разработчика, требуется иной подход. Изначально система полагалась на запросы разрешений, но из-за упомянутой усталости пользователей архитектуру изменили. Теперь применяется изоляция на уровне операционной системы (Seatbelt для macOS и bubblewrap для Linux). По умолчанию агенту разрешено чтение файлов и запись внутри рабочего пространства, но сетевой доступ заблокирован. Такое решение позволило сократить количество прерываний на 84%, сохранив при этом высокий уровень безопасности.
По мере того как агенты будут становиться все более автономными, индустрии придется признать: абсолютной безопасности не существует. Любая вероятностная защита имеет ненулевой процент промахов. Единственный надежный путь к масштабированию ИИ-агентов — это проектирование систем, в которых даже самый худший сценарий поведения модели не сможет нанести критического ущерба инфраструктуре.