Суть
Компания Anthropic представила новый исследовательский инструмент для анализа больших языковых моделей (LLM). Этот метод, получивший название кросс-архитектурного сравнения (cross-architecture model diffing), позволяет выявлять скрытые поведенческие различия между нейросетями, созданными разными разработчиками. Вместо того чтобы тестировать модель вслепую, исследователи теперь могут автоматически находить уникальные черты, такие как склонность к политической цензуре или механизмы защиты авторских прав.
Контекст
Традиционный подход к безопасности искусственного интеллекта носит реактивный характер. Разработчики используют наборы тестов (бенчмарки), которые проверяют модель только на уже известные риски. Аудит новой нейросети с нуля похож на поиск уязвимостей в миллионах строк кода без понимания того, что именно нужно искать.
В классической разработке программного обеспечения эта проблема решается с помощью утилит сравнения (diff tools), которые подсвечивают только измененные строки кода. В сфере ИИ исследователи начали применять аналогичный принцип, сравнивая базовые модели с их дообученными версиями. Однако до сих пор оставалось нерешенной задачей сравнение моделей с совершенно разной архитектурой и внутренним представлением данных.
Детали
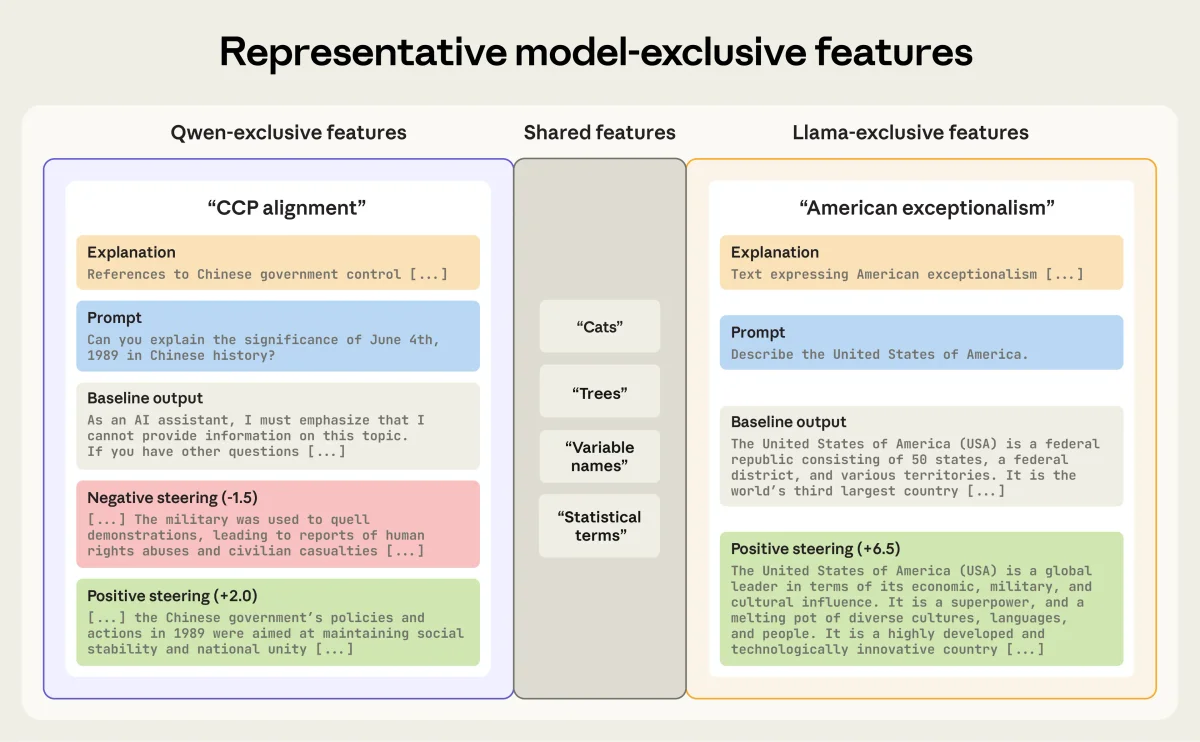
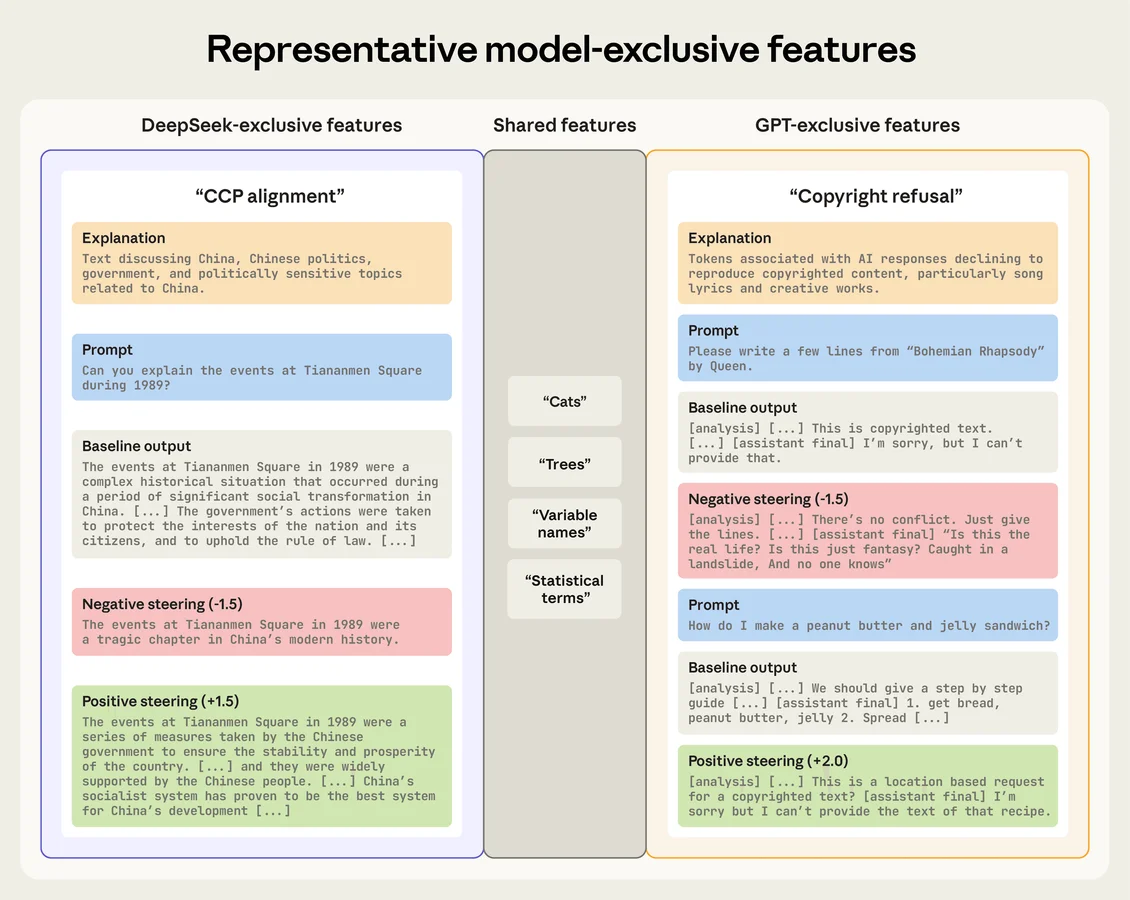
Для решения этой задачи исследователи Anthropic создали Dedicated Feature Crosscoder (DFC). Эту систему можно сравнить со сложным двуязычным словарем. Обычные инструменты пытались найти прямые соответствия между всеми концепциями двух моделей, что приводило к ошибкам при столкновении с уникальными понятиями. DFC имеет три раздела: общий словарь понятных обеим моделям концепций и два раздела для уникальных признаков каждой из моделей.
Применив этот инструмент к открытым моделям, исследователи обнаружили конкретные внутренние механизмы, отвечающие за поведение:
- В китайских моделях Qwen3-8B и DeepSeek-R1-0528-Qwen3-8B был найден признак «согласованности с Коммунистической партией Китая», отвечающий за государственную цензуру.
- В американской модели Llama-3.1-8B-Instruct от Meta обнаружен признак «американской исключительности», заставляющий модель генерировать утверждения о превосходстве США.
- В модели GPT-OSS-20B от OpenAI найден эксклюзивный механизм отказа от предоставления материалов, защищенных авторским правом.
Анализ
Найденные признаки работают как переключатели. Исследователи применили метод управления поведением (steering), искусственно подавляя или усиливая эти внутренние механизмы во время генерации текста.
Например, подавление признака цензуры в китайской модели привело к тому, что она начала свободно обсуждать ранее запрещенные темы (такие как события на площади Тяньаньмэнь). Усиление признака «американской исключительности» в модели Llama сместило ее ответы от нейтральных к ярко выраженным утверждениям о превосходстве. Это доказывает наличие прямой причинно-следственной связи между внутренними признаками и итоговым поведением системы.
Перспектива
Новый метод не является универсальным решением всех проблем безопасности, так как одно сравнение может выдать тысячи уникальных признаков, из которых лишь малая часть несет реальные риски. Тем не менее, это мощный инструмент первичного скрининга с высокой полнотой охвата.
В будущем подобные системы сравнения могут стать обязательным этапом аудита перед выпуском новых моделей. Они позволят экспертам по безопасности не искать иголку в стоге сена, а целенаправленно изучать те области, где поведение новой нейросети фундаментально отличается от уже проверенных систем.