Google представила новую архитектуру для распределенного обучения искусственного интеллекта под названием Decoupled DiLoCo (Distributed Low-Communication). Эта технология позволяет обучать большие языковые модели (LLM), распределяя нагрузку между географически удаленными дата-центрами. Главное достижение заключается в том, что система сохраняет высокую эффективность даже при низкой пропускной способности сети и аппаратных сбоях.
Традиционно обучение передовых моделей ИИ требует создания гигантских, жестко связанных систем. В таких кластерах тысячи идентичных чипов должны работать в состоянии практически идеальной синхронизации. Этот подход отлично зарекомендовал себя для текущего поколения моделей, но при дальнейшем масштабировании поддержание такой синхронизации становится серьезной логистической и инженерной проблемой. Любая задержка сети или выход из строя одного процессора может остановить весь процесс вычислений.
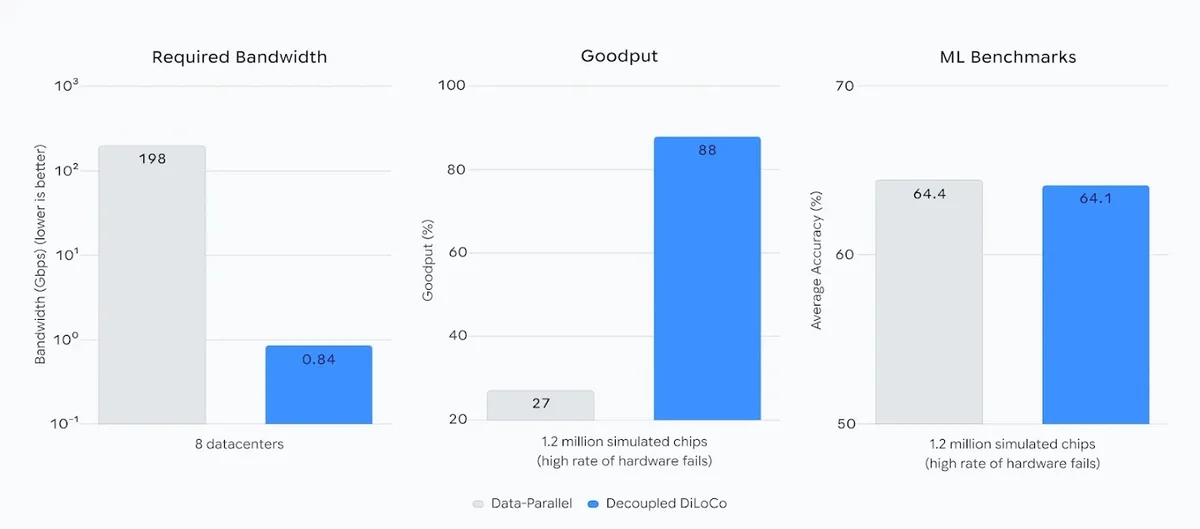
This set of three bar charts compares the performance of Data-Parallel training against Decoupled DiLoCo across communication, resilience, and accuracy metrics. The first chart, Required Bandwidth, shows that DiLoCo reduces bandwidth needs from 198 Gbps to a mere 0.84 Gbps across 8 datacenters, representing a massive efficiency gain on a logarithmic scale. The second chart, Goodput, demonstrates that in a simulated environment of 1.2 million chips with high failure rates, DiLoCo maintains a 88% goodput compared to only 27% for standard Data-Parallel methods. Finally, the ML Benchmarks chart highlights that these gains come with virtually no cost to performance, as DiLoCo achieves 64.1% average accuracy, nearly matching the 64.4% achieved by the baseline.
Архитектура Decoupled DiLoCo меняет эту парадигму, разделяя процесс обучения на независимые вычислительные «острова» (learner units). Данные между этими островами передаются асинхронно. Это означает, что локальные сбои изолируются: если часть оборудования выходит из строя, остальные элементы системы продолжают эффективно обучаться. Технология построена на базе более ранних разработок компании — системы Pathways и оригинального алгоритма DiLoCo, который существенно снизил требования к пропускной способности каналов связи.
В ходе тестирования исследователи применили метод «хаосной инженерии» (chaos engineering), искусственно вызывая аппаратные сбои во время обучения. Система Decoupled DiLoCo успешно продолжала работу даже при потере целых вычислительных блоков, а затем бесшовно интегрировала их обратно после восстановления. На практике команда успешно обучила модель семейства Gemma 4 с 12 миллиардами параметров, используя вычислительные мощности в четырех разных регионах США.
Для связи между регионами потребовалась пропускная способность всего 2-5 Гбит/с. Это уровень обычного магистрального интернета, не требующий прокладки дорогостоящих специализированных оптических линий между дата-центрами. При таких условиях система выполнила задачу более чем в 20 раз быстрее, чем традиционные методы синхронного обучения. Секрет кроется в том, что архитектура встраивает необходимые коммуникации в длительные периоды локальных вычислений, избегая ситуаций, когда одни чипы простаивают в ожидании данных от других.
Для индустрии это означает качественный сдвиг в подходе к проектированию вычислительной инфраструктуры. Архитектура позволяет объединять в одном цикле обучения чипы разных поколений, например, новые TPU v6e и более старые TPU v5p. В экспериментах Google такое смешивание оборудования, работающего на разных скоростях, не привело к падению итогового качества модели. Это критически важное свойство, так как оно позволяет продлить срок службы устаревающего оборудования и утилизировать любые доступные мощности.
В долгосрочной перспективе подобные асинхронные методы обучения могут демократизировать доступ к созданию масштабных ИИ-моделей. Компании смогут использовать простаивающие ресурсы по всему миру, превращая разрозненные серверы в единый виртуальный суперкомпьютер. По мере роста сложности моделей именно отказоустойчивость и гибкость инфраструктуры станут главными факторами, определяющими скорость развития технологий искусственного интеллекта.