Как правильно оценивать навыки AI-агентов: опыт LangChain
Команда LangChain делится методологией тестирования «навыков» для кодинг-агентов. Почему просто добавить инструкции недостаточно и как построить надежный пайплайн оценки.

В индустрии разработки AI-агентов происходит важный сдвиг. Если раньше мы просто давали моделям доступ к инструментам и надеялись на лучшее, то теперь фокус смещается на создание специализированных «навыков» (skills) и, что еще важнее, на строгую оценку их эффективности. Команда LangChain опубликовала подробный разбор того, как они тестируют навыки для таких агентов, как Claude Code.
Суть проблемы: больше инструментов — не значит лучше
«Навыки» в контексте агентов — это набор инструкций, скриптов и ресурсов, которые загружаются динамически. Ключевое слово здесь — динамически. Исторически сложилось так, что если дать агенту слишком много инструментов сразу, его производительность падает: модель «теряется» в контексте. Поэтому навыки должны подгружаться только тогда, когда они релевантны текущей задаче.
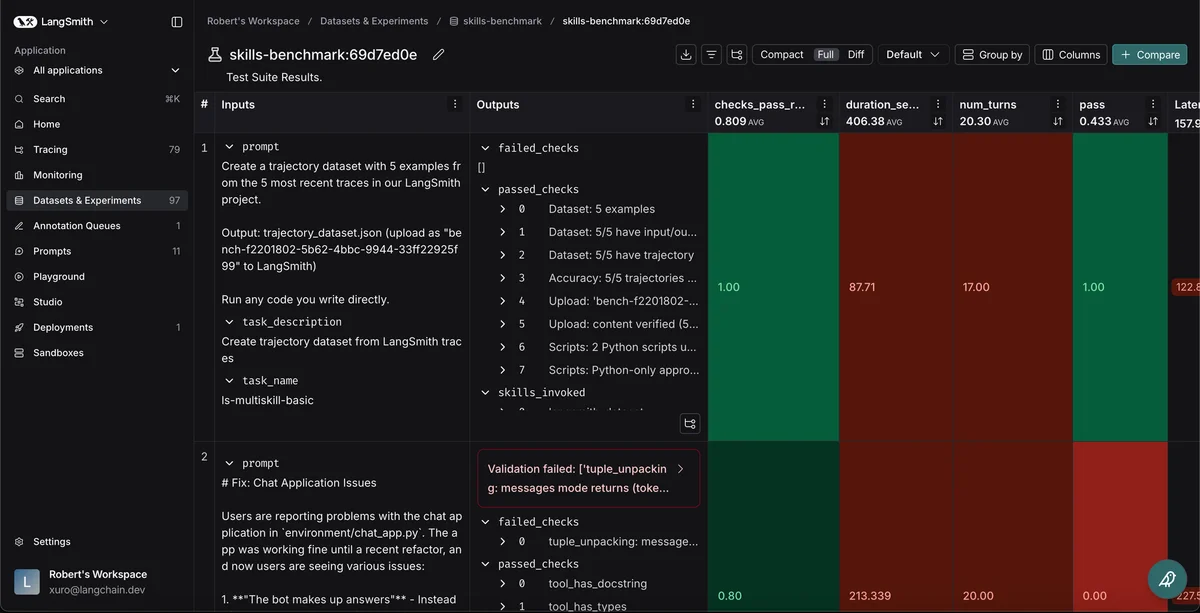
Но как понять, действительно ли добавленный навык помогает, а не сбивает агента с толку? LangChain предлагает четырехступенчатый процесс оценки.
Шаг 1: Чистая среда тестирования
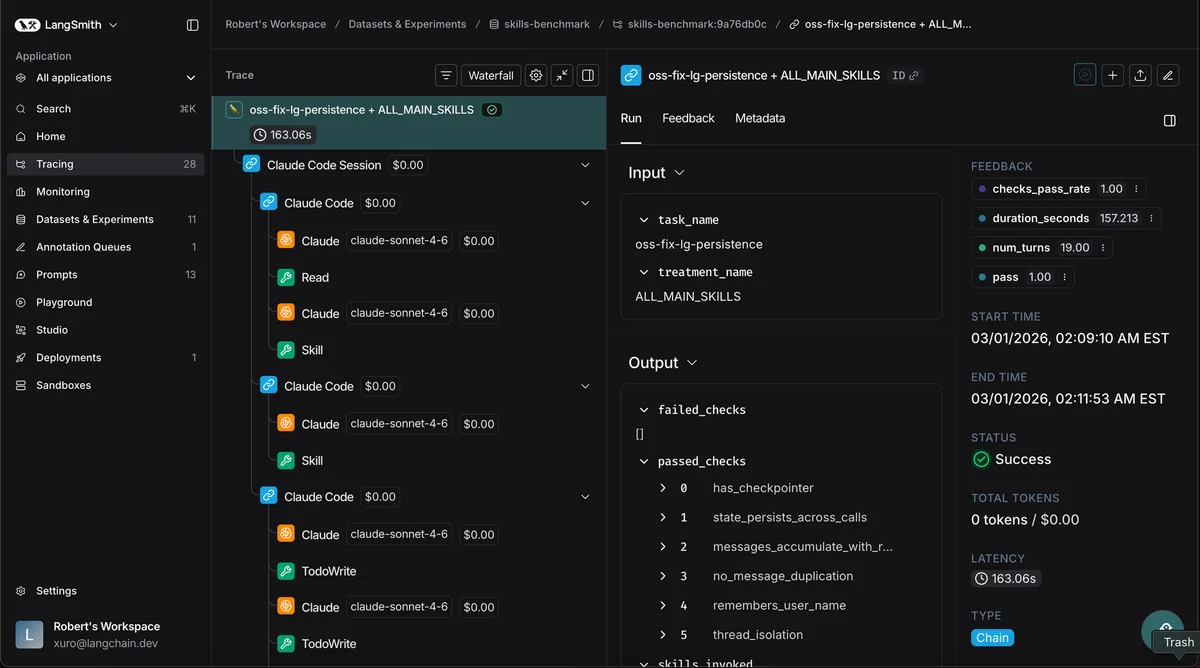
Агенты, пишущие код, чрезвычайно чувствительны к начальным условиям. Если запустить Claude Code в папке с «мусором» от предыдущих проектов, его поведение изменится. Он начнет изучать существующие файлы и подстраиваться под них.
Изображение из источника
Поэтому критически важно использовать изолированные среды. LangChain рекомендует запускать агентов в Docker-контейнерах или специальных «песочницах». Это гарантирует воспроизводимость результатов: каждый тест начинается с чистого листа.