Компания Google представила DiffusionGemma — экспериментальную открытую модель, которая предлагает принципиально новый подход к генерации текста. В отличие от привычных больших языковых моделей (LLM), которые предсказывают слова одно за другим, новинка использует механизм текстовой диффузии. Это позволяет генерировать целые блоки текста одновременно, что обеспечивает ускорение вывода до четырех раз на выделенных графических процессорах (GPU).
Традиционные языковые модели работают по принципу авторегрессии. Их можно сравнить с печатной машинкой: они создают текст последовательно, токен за токеном, слева направо. В облачных средах такой подход эффективен, поскольку серверы могут объединять тысячи запросов в пакеты, оптимально распределяя нагрузку. Однако при локальном запуске для одного пользователя этот процесс оставляет ресурсы современного оборудования недоиспользованными. Процессор большую часть времени просто ожидает следующего шага вычислений.
DiffusionGemma решает проблему неэффективного использования локального оборудования. Модель генерирует сразу 256 токенов параллельно. Процесс похож на работу генераторов изображений: сначала создается «холст» из случайных токенов-заполнителей, затем в ходе нескольких итераций модель фиксирует правильные элементы и использует их как контекст для уточнения остальных. В результате модель превращается из последовательной «печатной машинки» в своеобразный «печатный станок».
Технически DiffusionGemma представляет собой модель на базе архитектуры смеси экспертов (Mixture of Experts, MoE) общим объемом 26 миллиардов параметров. При этом во время вывода активируется только 3,8 миллиарда параметров. Благодаря этому в квантованном виде модель комфортно помещается в 18 ГБ видеопамяти, что делает ее доступной для высокопроизводительных потребительских видеокарт.
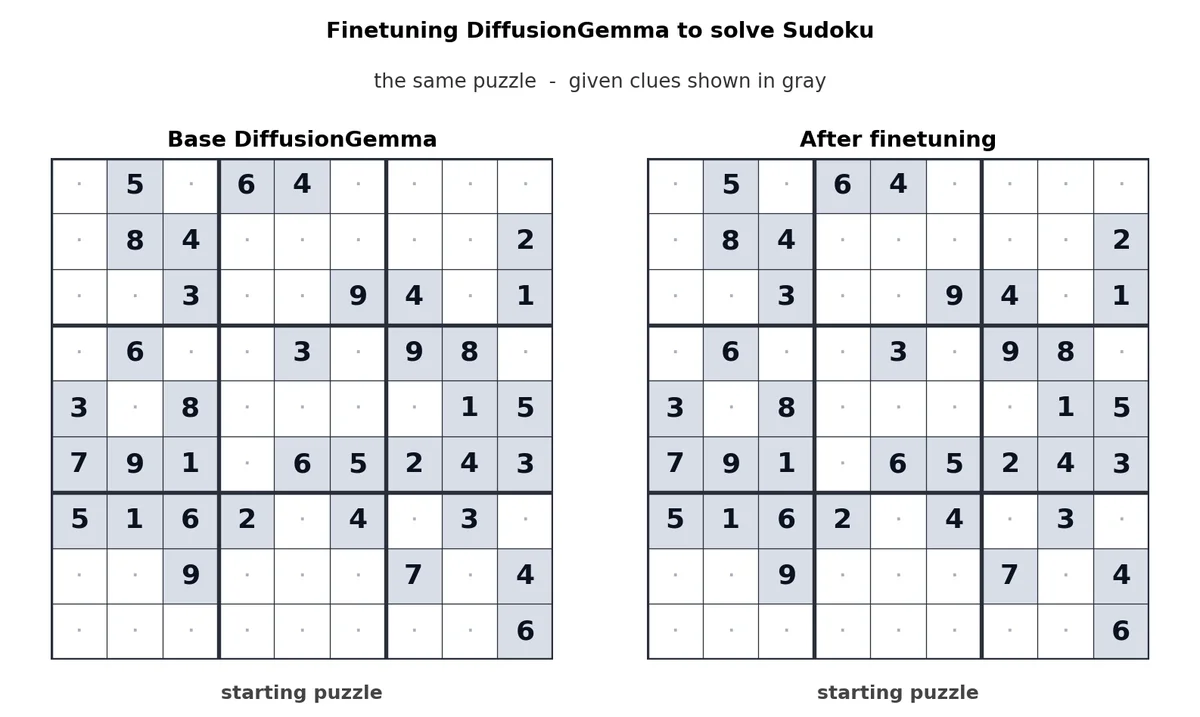
Fine-tuned DiffusionGemma solving Sudoku.
Скорость работы впечатляет: на одном ускорителе NVIDIA H100 модель выдает более 1000 токенов в секунду, а на потребительской NVIDIA GeForce RTX 5090 — более 700 токенов в секунду. Однако у такого подхода есть свои компромиссы. Поскольку приоритетом является скорость и параллельная генерация, общее качество текста уступает стандартным авторегрессионным моделям семейства Gemma 4.
Ключевое преимущество архитектуры — двунаправленное внимание (bi-directional attention). Поскольку модель обрабатывает весь блок текста сразу, каждый токен может учитывать контекст всех остальных токенов, включая те, что находятся «в будущем». Это критически важно для нелинейных задач. Например, при дообучении модель отлично справляется с решением судоку или заполнением пропусков в коде — задачами, где стандартные авторегрессионные модели часто терпят неудачу.
Появление DiffusionGemma не означает отказа от традиционных моделей. Для задач, требующих максимального качества или высокой пропускной способности в облаке (high-QPS), авторегрессионные системы остаются стандартом. Однако для исследователей и разработчиков, создающих интерактивные локальные приложения, требующие мгновенного отклика — такие как редактирование текста в реальном времени или быстрая генерация кода, — диффузионный подход открывает совершенно новые перспективы.