Microsoft анонсировала AgentRx — автоматизированный диагностический фреймворк, предназначенный для поиска и исправления ошибок в работе искусственного интеллекта. По мере того как ИИ эволюционирует от простых диалоговых ботов к сложным автономным системам, способным самостоятельно планировать и выполнять многошаговые задачи, цена ошибки многократно возрастает. AgentRx создан для того, чтобы сделать такие системы более прозрачными и устойчивыми к сбоям.
Долгое время взаимодействие с большими языковыми моделями (LLM) происходило в формате прямого диалога. Если модель выдавала некорректный ответ, разработчик или пользователь видел это сразу. Однако современные автономные агенты работают иначе. Они могут выполнять десятки последовательных действий: анализировать данные, обращаться к внешним интерфейсам (API), писать и тестировать программный код. В такой цепочке небольшая неточность на первом этапе может привести к критическому сбою на десятом. Традиционные методы отладки программного обеспечения, основанные на поиске ошибок в строгом, детерминированном коде, плохо подходят для вероятностной природы нейросетей.
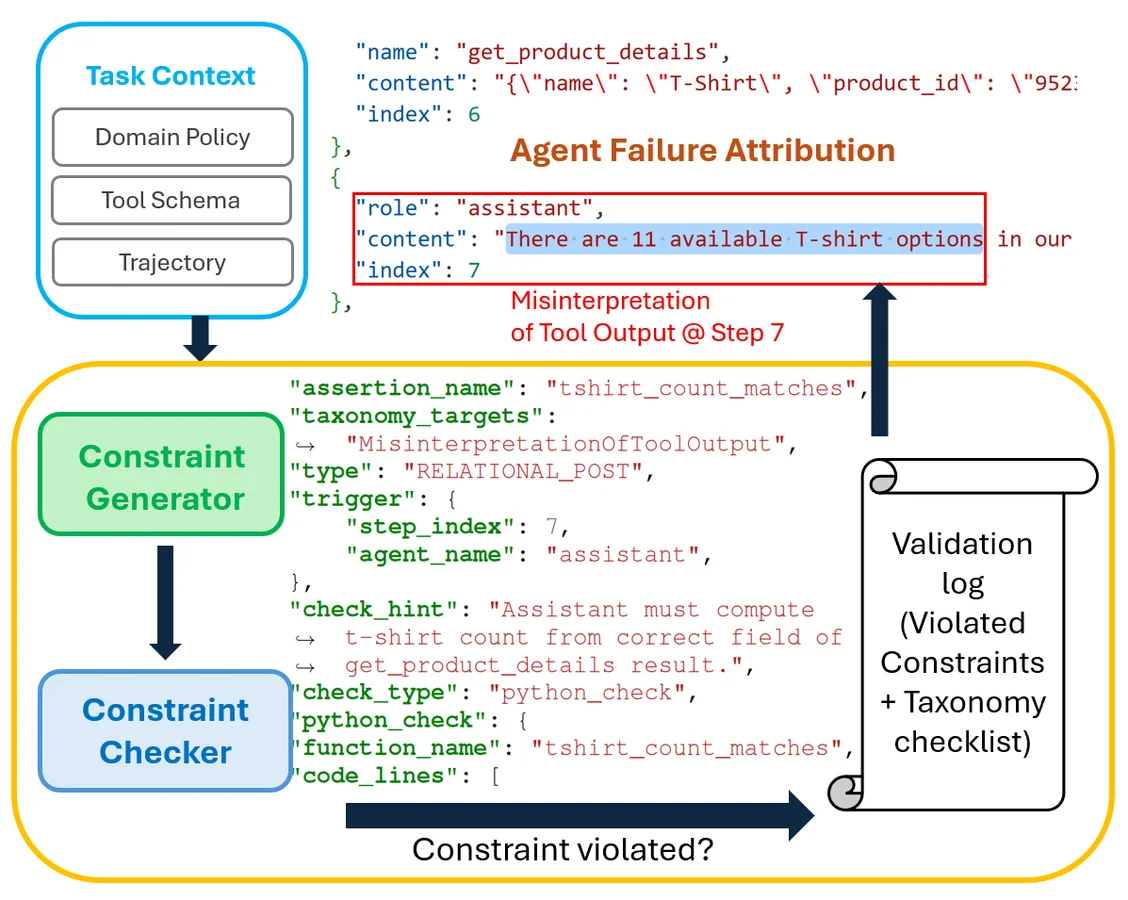
Flowchart illustrating an agent failure attribution pipeline. In the upper left, a blue rounded box labeled “Task Context” contains three stacked inputs: “Domain Policy,” “Tool Schema,” and “Trajectory.” A downward arrow leads into a large yellow rounded rectangle representing the validation pipeline. Inside this area, a green box labeled “Constraint Generator” feeds into a blue box labeled “Constraint Checker.” To their right is a JSON-like constraint specification with fields such as assertion_name:
AgentRx предлагает систематический подход к решению этой проблемы. Фреймворк способен автоматически анализировать журналы действий агента и локализовать конкретный шаг, на котором произошел сбой логики или неверная интерпретация данных. Это избавляет разработчиков от необходимости вручную просматривать огромные массивы текстовых логов в попытках понять, почему агент принял то или иное решение.
Разработка AgentRx является частью более широкой инициативы Microsoft Research по созданию надежной инфраструктуры для ИИ-агентов. В эту же экосистему входят и другие специализированные проекты компании. Например, среда Debug-gym, созданная для обучения ИИ-инструментов самостоятельному поиску ошибок в коде, или платформа AIOpsLab, направленная на разработку агентов для автономного управления облачной инфраструктурой. Также ведутся исследования в области интеграции обучения с подкреплением (reinforcement learning), что позволит агентам адаптироваться и улучшать свои навыки без необходимости прямого переписывания кода разработчиками.
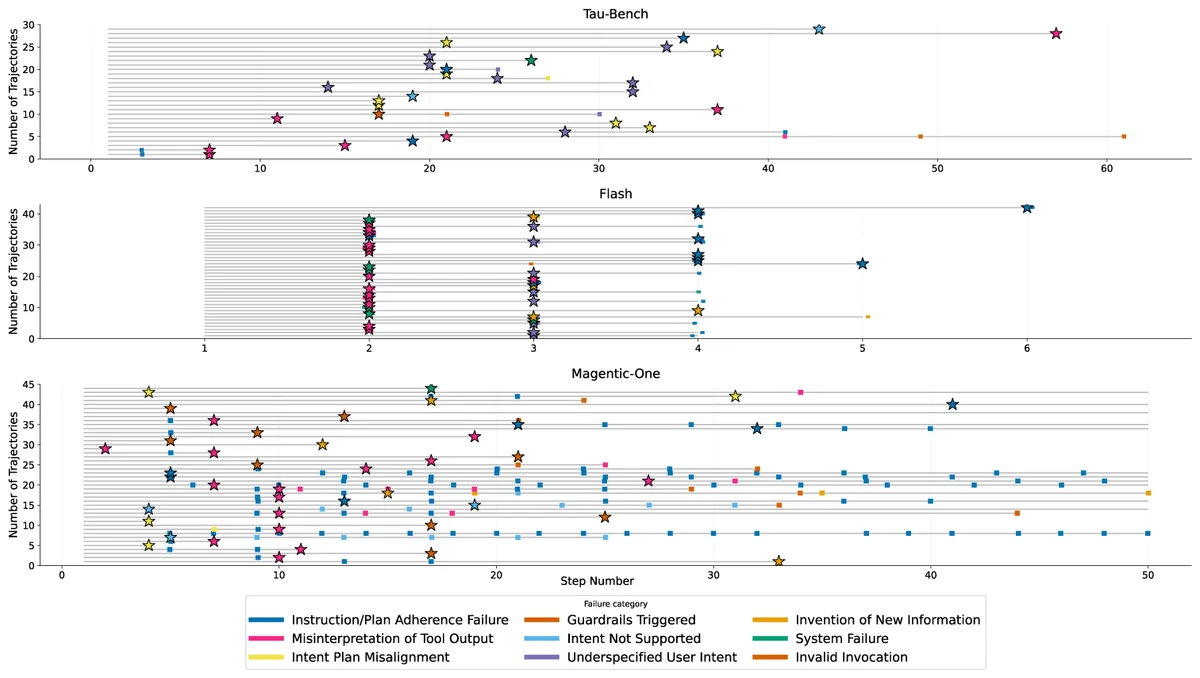
Two-column taxonomy table with a dark blue header row labeled “Taxonomy Category” and “Description.” The rows define nine agent failure types: Plan Adherence Failure, Invention of New Information, Invalid Invocation, Misinterpretation of Tool Output, Intent–Plan Misalignment, Under-specified User Intent, Intent Not Supported, Guardrails Triggered, and System Failure. Their descriptions explain, respectively, skipped or extra actions, invented facts, malformed tool calls, incorrect reading of tool outputs, wrong planning from misunderstood intent, inability to proceed due to missing information, lack of tool support, blocking by safety or access controls, and connectivity or endpoint failures.
Появление инструментов класса AgentRx сигнализирует о важном этапе взросления индустрии. Рынок переходит от создания концептуальных прототипов к разработке промышленных решений. Для бизнеса сегодня недостаточно просто иметь умного агента; критически важно понимать, как он мыслит, почему ошибается и как гарантировать его безопасность в производственной среде. Прозрачность процессов принятия решений становится не просто желательной функцией, а строгим требованием.
В перспективе мы будем наблюдать формирование совершенно новой отрасли — систем мониторинга и отладки (observability) специально для автономных ИИ-систем. Инструменты вроде AgentRx станут стандартом де-факто при разработке корпоративных агентов. Со временем эти системы научатся не только диагностировать проблемы постфактум, но и превентивно останавливать агента, если его цепочка рассуждений начинает отклоняться от заданных параметров безопасности.