Суть новости
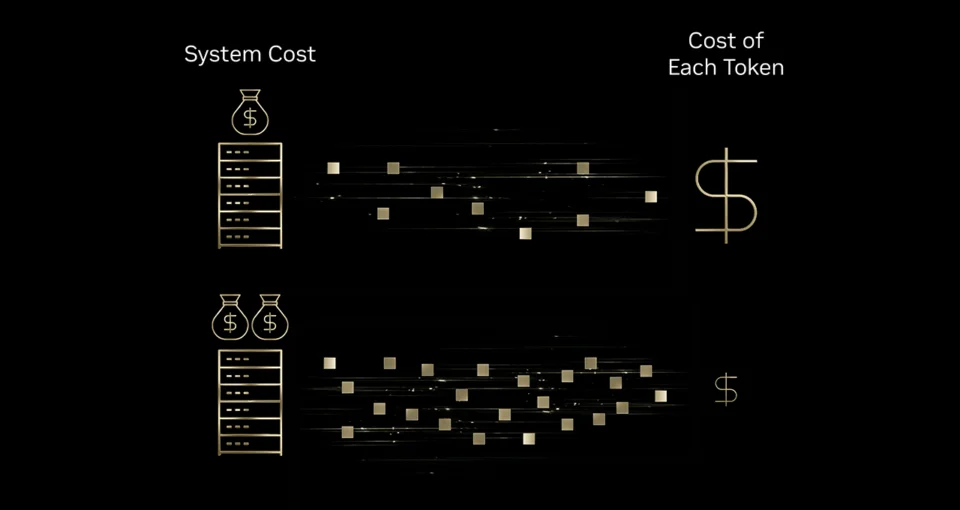
Компания NVIDIA опубликовала данные о том, как переход на новую архитектуру графических процессоров Blackwell влияет на экономику искусственного интеллекта. Ключевые провайдеры инфраструктуры — Baseten, DeepInfra, Fireworks AI и Together AI — сообщают о снижении стоимости генерации токена (единицы информации в AI) до 10 раз по сравнению с предыдущим поколением чипов Hopper. Это изменение делает рентабельными сложные сценарии использования ИИ, которые ранее были слишком дорогими для массового внедрения.
Контекст: почему важна стоимость токена
В основе любого взаимодействия с генеративным ИИ лежит токен. Будь то диагностика в медицине, диалог в игре или ответ службы поддержки — все это последовательности токенов. Для бизнеса вопрос масштабирования ИИ упирается в «токеномику»: сколько стоит сгенерировать миллион токенов?
До недавнего времени высокая стоимость инференса (процесса работы нейросети) ограничивала применение мощных моделей. Компании были вынуждены выбирать: либо платить дорого за закрытые проприетарные модели, либо жертвовать качеством ради скорости и дешевизны. Появление открытых моделей пограничного уровня (frontier-level open source models) в сочетании с более эффективным железом меняет правила игры.
Детали и примеры из индустрии
NVIDIA приводит конкретные кейсы, показывающие, как оптимизация оборудования и программного стека влияет на бизнес-показатели:
Здравоохранение (Sully.ai и Baseten)
Платформа Sully.ai создает «цифровых сотрудников» для врачей, автоматизируя кодирование диагнозов и ведение записей. Использование закрытых моделей создавало проблемы с задержкой и стоимостью. Переход на открытые модели (например, gpt-oss-120b), запущенные на чипах Blackwell через API Baseten, позволил:
- Снизить затраты на инференс на 90% (в 10 раз).
- Ускорить время ответа на 65%.
- Использовать формат данных низкой точности NVFP4 для оптимизации.
Гейминг (Latitude и DeepInfra)
Создатели игры AI Dungeon столкнулись с проблемой масштабирования: каждое действие игрока требует генерации текста. Переход с архитектуры Hopper на Blackwell позволил снизить стоимость миллиона токенов с 20 до 10 центов. А использование формата NVFP4 опустило цену до 5 центов. Итоговое снижение затрат составило 4 раза при сохранении качества.
Агентные системы (Sentient и Fireworks AI)
Приложения, где множество AI-агентов общаются друг с другом для решения задачи, требуют огромных вычислительных ресурсов. Платформа Sentient смогла повысить эффективность затрат на 25–50%, что позволило обработать 5,6 миллиона запросов за неделю после вирусного запуска.
Служба поддержки (Decagon и Together AI)
Голосовые боты требуют мгновенной реакции (менее секунды), иначе клиент начинает говорить одновременно с роботом. Использование Blackwell и методов спекулятивного декодирования (когда маленькая модель генерирует варианты, а большая их проверяет) позволило достичь задержки менее 400 мс и снизить стоимость диалога в 6 раз по сравнению с закрытыми моделями.
Анализ: что это значит для рынка
Мы наблюдаем классический эффект масштаба, сравнимый с развитием печатного станка. Если новое оборудование позволяет печатать в 10 раз больше страниц при незначительном росте затрат на энергию и обслуживание, стоимость одной страницы резко падает.
Снижение стоимости токена открывает дорогу для:
- Агентных систем: когда для решения одной задачи требуется цепочка из сотен внутренних диалогов между нейросетями.
- Массовой персонализации: генерация уникального контента для каждого пользователя в реальном времени (например, в играх) перестает быть убыточной.
- Отказу от закрытых API: открытые модели на эффективном железе становятся экономически выгоднее подписок на проприетарные сервисы.
Перспектива
Тенденция на удешевление вычислений продолжится. NVIDIA уже анонсировала платформу Rubin, которая обещает еще одно десятикратное снижение стоимости токена. Это означает, что в ближайшие годы мы перейдем от модели «экономии токенов» к модели их избытка, что позволит внедрять ИИ в процессы, где раньше это считалось нецелесообразным.