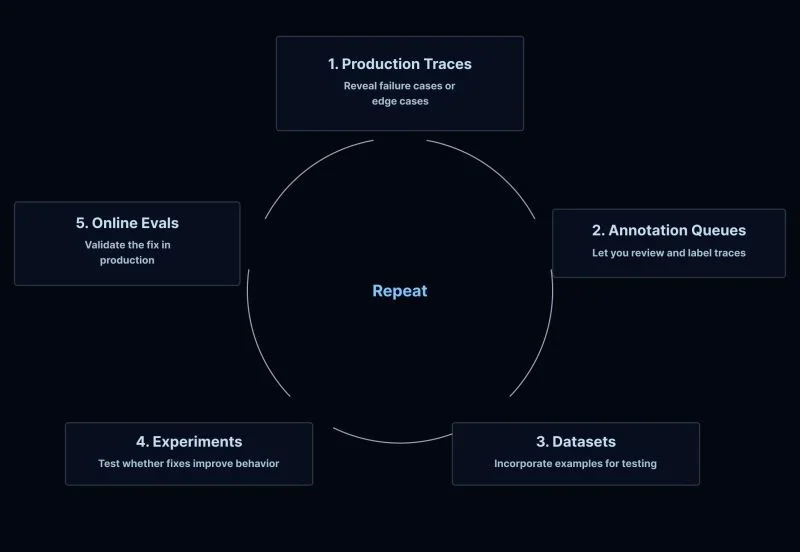
Создание автономных ИИ-агентов часто сталкивается с серьезной преградой: как доказать, что они работают надежно. Инженеры компании LangChain опубликовали подробный чек-лист, который помогает систематизировать процесс оценки агентов перед их внедрением в рабочую среду. Главный посыл документа заключается в том, что автоматизация ради автоматизации не работает — начинать всегда нужно с ручного анализа.
Тестирование агентов на базе больших языковых моделей (LLM) кардинально отличается от классического тестирования программного обеспечения. Если в обычном коде результат предсказуем, то агенты могут находить нестандартные пути решения задач или совершать непредсказуемые ошибки. Именно поэтому разработчикам требуется принципиально иной подход к мониторингу и оценке качества.
Согласно рекомендациям LangChain, первый шаг к созданию системы оценки — это ручной просмотр 20-50 реальных логов работы агента (traces). Этот процесс дает больше понимания паттернов ошибок, чем любая автоматизированная система. На анализ ошибок должно уходить от 60 до 80 процентов всего времени, выделенного на тестирование.
Критически важно разделять тесты на две категории. Первая — оценка возможностей (capability evals). Она отвечает на вопрос, на что способен агент, и помогает развивать систему, предлагая сложные задачи с изначально низким процентом успеха. Вторая категория — регрессионные тесты (regression evals). Они проверяют, не сломалось ли то, что уже работало, и должны выполняться с вероятностью успеха, близкой к 100 процентам.
Специалисты выделяют три уровня оценки поведения агента. Одношаговая оценка (single-step) проверяет, правильно ли агент выбрал инструмент. Оценка полного цикла (full-turn) анализирует всю цепочку действий и финальный ответ. Многошаговая оценка (multi-turn) применяется для сложных диалоговых систем. Начинать рекомендуется именно с полного цикла, так как он дает наиболее полную картину.
Особое внимание стоит уделять проверке изменений состояния (state changes). Если агент должен назначить встречу, недостаточно проверить, что он написал текст "Встреча назначена". Необходимо убедиться, что событие действительно появилось в календаре с правильными участниками и временем.
В будущем процесс оценки ИИ-агентов станет отдельной инженерной дисциплиной. Практика показывает, что 20-50 тщательно проверенных вручную примеров работают гораздо лучше, чем сотни сгенерированных синтетических тестов. Надежность агентов будет зависеть от того, насколько глубоко разработчики готовы погружаться в ручной анализ отказов на ранних этапах.