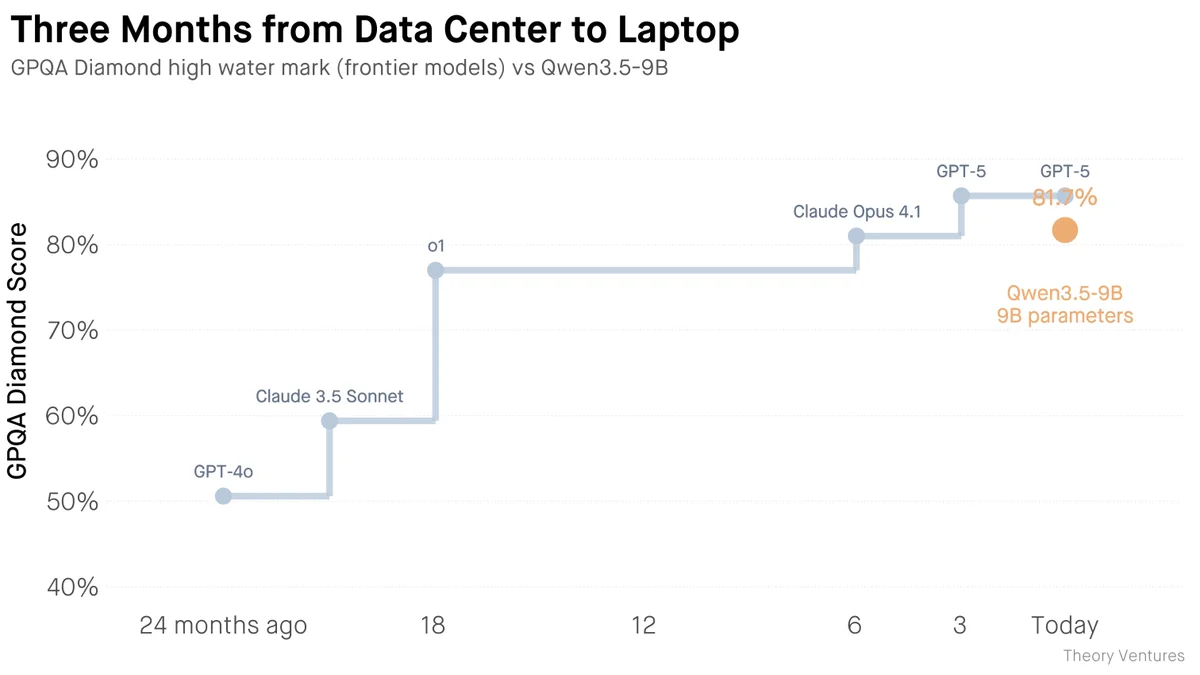
Компания Alibaba выпустила открытую языковую модель Qwen3.5-9B. Ее главная особенность заключается в том, что она сопоставима по качеству ответов с передовыми коммерческими решениями конца прошлого года, но при этом способна работать локально, требуя всего 12 гигабайт оперативной памяти. Это событие знаменует важный сдвиг в индустрии: вычислительная мощность, для которой еще недавно требовался полноценный дата-центр, теперь доступна на обычном рабочем ноутбуке.
Чтобы понять значимость этого перехода, необходимо взглянуть на текущую экономику использования больших языковых моделей (LLM). Активные исследователи, разработчики и аналитики ежедневно пропускают через нейросети десятки миллионов токенов. Они анализируют компании, составляют документы и запускают автономных агентов. При средней стоимости коммерческих программных интерфейсов (API) около 9 долларов за миллион токенов, интенсивный рабочий день может обойтись пользователю в сотни долларов. Облачные вычисления по тарифам передовых моделей быстро становятся существенной статьей расходов.
Появление Qwen3.5-9B кардинально меняет математику выбора между арендой облачных мощностей и покупкой собственного оборудования. Рабочая станция или мощный ноутбук стоимостью 5000 долларов окупает себя примерно за 556 миллионов обработанных токенов. Для специалиста, генерирующего около 20 миллионов токенов в день, возврат инвестиций наступает всего за четыре недели. После того как оборудование окупилось, предельная стоимость каждого нового запроса снижается до стоимости потребленной электроэнергии.
GPQA Diamond high water mark chart showing frontier models vs Qwen3.5-9B
Важно отметить, что этот переход не требует компромиссов в качестве базовых навыков искусственного интеллекта. Локальная модель успешно справляется с логическими рассуждениями, написанием кода, обработкой сложных документов и точным следованием инструкциям. Более того, перенос вычислений на собственное устройство решает фундаментальные проблемы безопасности и надежности. Все данные, будь то черновики писем, финансовая аналитика или проприетарный код, остаются на локальной машине. Пользователь больше не зависит от стабильности интернет-соединения, сбоев на стороне провайдера, лимитов на количество запросов и скрытого сбора данных.
Однако у локального подхода есть существенный недостаток — отсутствие распараллеливания (parallelization). Облачные сервисы спроектированы так, чтобы обрабатывать тысячи запросов одновременно. Локальный компьютер, как правило, выполняет только один вывод (inference) за раз. Для последовательных задач, таких как обобщение текста, написание черновиков или ответы на вопросы, это не является проблемой. Задачи можно поставить в очередь и оставить выполняться в фоновом режиме. Но для сложных рабочих процессов, где автономные агенты создают десятки параллельных потоков, ожидание локальной обработки может оказаться слишком долгим.
Мы наблюдаем, как цикл демократизации технологий сжимается. Путь от эксклюзивного доступа в дата-центрах до запуска на персональном компьютере теперь занимает считанные месяцы. Экономика использования искусственного интеллекта начинает благоприятствовать глубине, а не ширине: становится выгоднее запускать меньшее количество задач, но позволять им работать дольше и значительно дешевле.