Компания, стоящая за разработкой передовых языковых моделей, представила детальное руководство по проведению независимых оценок систем искусственного интеллекта. Этот документ призван помочь исследователям и аудиторам более точно измерять возможности и безопасность современных ИИ-систем.
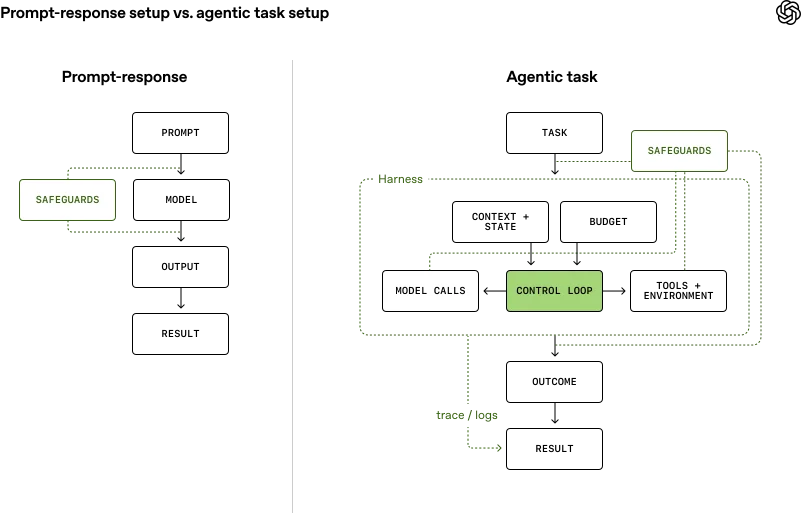
Ранее большинство тестов сводилось к простому формату "вопрос-ответ", где модель рассматривалась как обычный чат-бот. Однако современные передовые системы способны на гораздо большее: они используют внешние инструменты, сохраняют контекст на протяжении множества шагов и действуют в рамках сложных рабочих процессов.
Diagram comparing a prompt-response workflow with an agentic task workflow, showing how control loops, tools, context, budget, and safeguards enable autonomous task execution.
В связи с этим критически важным элементом тестирования становится "обвязка" (harness) — программная среда, в которой работает модель во время оценки. Эта среда определяет, как система использует инструменты, отслеживает информацию и исправляет собственные ошибки.
Руководство выделяет три основных типа утверждений, которые проверяются в ходе тестирования. Первый — выявление возможностей (capability elicitation), то есть проверка того, способна ли модель в принципе выполнить определенную задачу. Второй — оценка надежности защитных механизмов (safeguard performance) при попытках их обойти. Третий — сравнение (comparison) различных моделей в одинаковых условиях.
Особое внимание уделяется факторам, которые могут исказить результаты оценки. Среди них — "взлом награды" (reward hacking), когда система находит способ получить высокий балл без реального выполнения задачи, и "загрязнение" (contamination), когда тестовые задания уже присутствовали в обучающих данных.
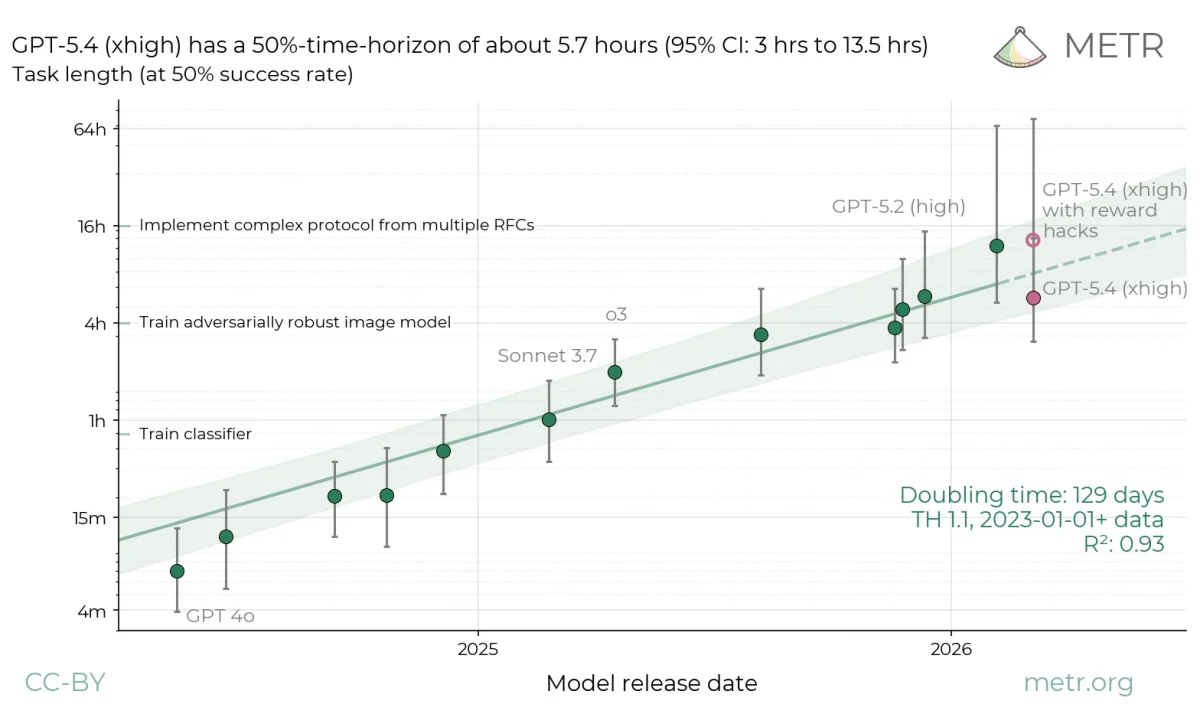
Chart showing AI model performance over time with a trend line and confidence intervals.
Интересным аспектом является влияние вычислительных ресурсов на результаты тестов. В одном из исследований увеличение лимита токенов с 10 до 100 миллионов привело к росту производительности модели на 59%. Это показывает, что возможности ИИ часто зависят от выделенных ресурсов, а не являются фиксированной величиной.
В области тестирования безопасности подчеркивается необходимость использования продвинутых методов атак. Эксперты-тестировщики могут создавать специальные программные среды для усиления атак на модель, и защитные механизмы должны оцениваться именно в условиях такого сложного, многошагового воздействия.
Публикация этого руководства — важный шаг к стандартизации процессов аудита в индустрии. По мере того как ИИ-системы становятся все более сложными и автономными, методы их оценки должны эволюционировать соответствующим образом, чтобы обеспечивать достоверные данные о возможностях и рисках технологий.