Суть
Компания OpenAI внедрила поддержку протокола WebSockets в свой Responses API, что позволило сократить задержки в агентных рабочих процессах на 40 процентов. Это обновление решает фундаментальную проблему: по мере того как генерация текста моделями становится быстрее, традиционная архитектура передачи данных начинает тормозить весь процесс.
Контекст
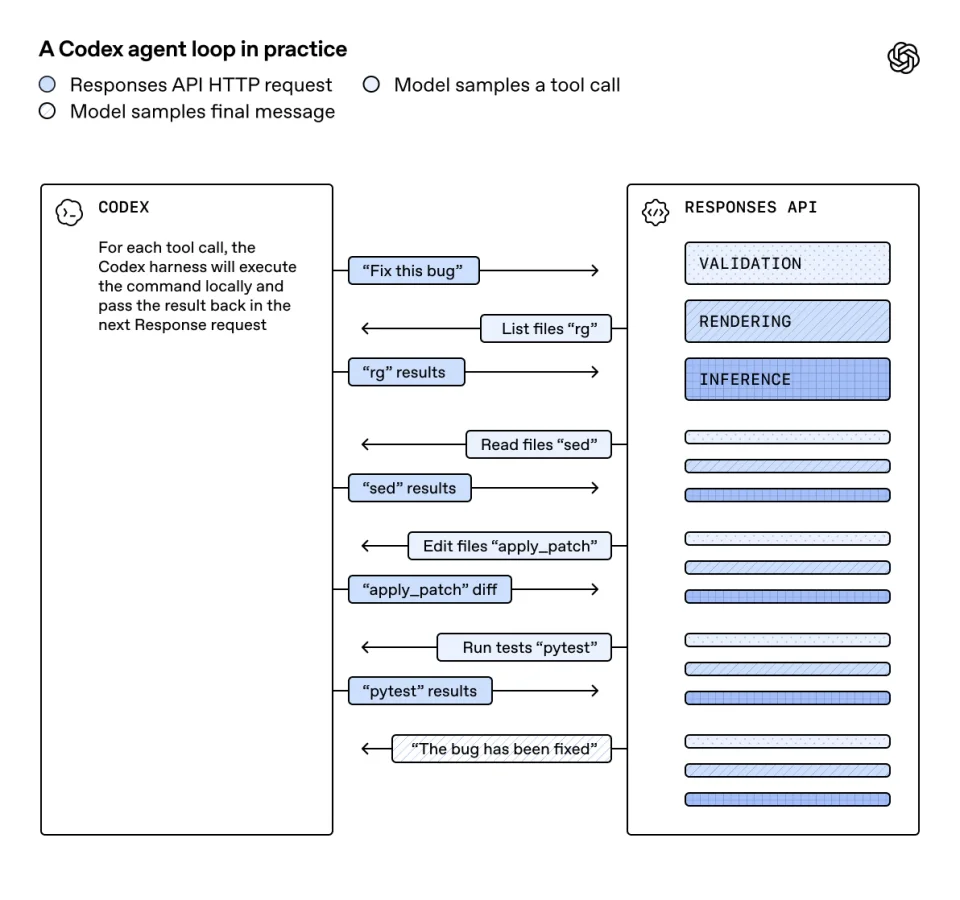
Когда автономный агент, например Codex, выполняет сложную задачу (анализирует код, вносит правки, запускает тесты), он совершает десятки последовательных обращений к API. Исторически самым медленным этапом этого цикла был вывод (inference) — процесс генерации новых токенов на графических процессорах (GPU).
Diagram titled “A Codex agent loop in practice” showing an iterative flow between Codex and the Responses API, with tool calls (rg, sed, apply_patch, pytest) and results exchanged until the final message: “The bug has been fixed.”
Однако с появлением новых специализированных аппаратных решений, таких как чипы Cerebras, скорость вывода многократно возросла. Для модели GPT-5.3-Codex-Spark целевой показатель составил более 1000 токенов в секунду. При таких скоростях узким местом стала сама инфраструктура API. В старой парадигме каждый запрос обрабатывался как независимый: системе приходилось заново передавать и обрабатывать всю историю диалога, что создавало огромные накладные расходы.
Детали
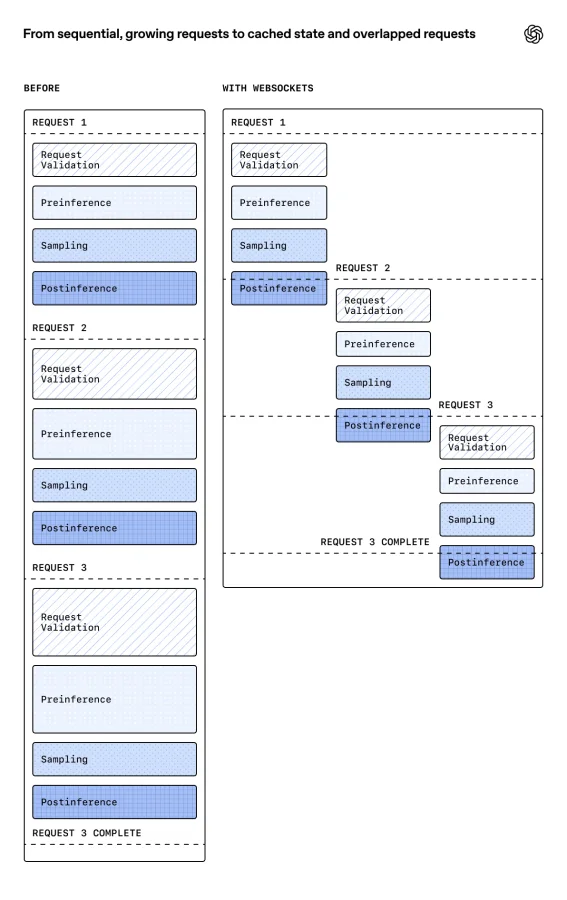
Чтобы устранить эти ограничения, разработчики пересмотрели транспортный протокол и перешли на использование постоянного соединения через WebSockets.
Вместо того чтобы при каждом запросе заново собирать контекст, сервер теперь хранит кэш состояния предыдущего ответа в оперативной памяти в рамках одного соединения. Разработчикам достаточно передать параметр previous_response_id, чтобы продолжить работу. В кэше сохраняются предыдущие объекты ответов, определения инструментов и уже отрендеренные токены.
Такой подход позволил:
- Избежать повторной токенизации всей истории переписки.
- Запускать проверки безопасности только для новых входных данных.
- Устранить лишние сетевые переходы между промежуточными сервисами.
Diagram titled “From sequential requests to overlapped execution” comparing a sequential request pipeline with a WebSocket-based approach where multiple requests overlap across validation, preinference, sampling, and postinference stages.
Анализ
Результаты внедрения оказались впечатляющими. В рабочих условиях модель GPT-5.3-Codex-Spark стабильно выдает 1000 токенов в секунду, а на пиках достигает 4000 токенов в секунду.
Эффект быстро распространился по всей экосистеме разработчиков. Интеграция режима WebSocket в Vercel AI SDK привела к снижению задержек на 40 процентов. Многофайловые процессы в Cline ускорились на 39 процентов, а работа моделей OpenAI в редакторе Cursor стала быстрее на 30 процентов. Это показывает, что оптимизация на уровне инфраструктуры передачи данных имеет критическое значение для конечного пользовательского опыта.
Перспектива
Этот переход демонстрирует важный сдвиг в развитии индустрии искусственного интеллекта. Фокус внимания смещается с чистой скорости самих моделей на оптимизацию систем, которые их обслуживают. По мере дальнейшего аппаратного ускорения вывода, разработчикам инфраструктуры придется искать новые способы минимизации сетевых и вычислительных издержек, чтобы пользователи могли в полной мере ощутить рост производительности.