Суть
Разработка AI-агентов требует фундаментального пересмотра подходов к качеству программного обеспечения. В отличие от традиционного софта, где ошибка обычно кроется в конкретной строке кода, сбой агента — это ошибка в цепочке рассуждений. Команда LangChain объясняет, что создать надежного агента невозможно без глубокого понимания того, как он «мыслит», а улучшить его работу нельзя без систематической оценки (evaluation). Главный тезис: вы не узнаете, как поведет себя ваш агент, пока не запустите его, поэтому наблюдаемость (observability) становится основой для любой оценки качества.
Контекст
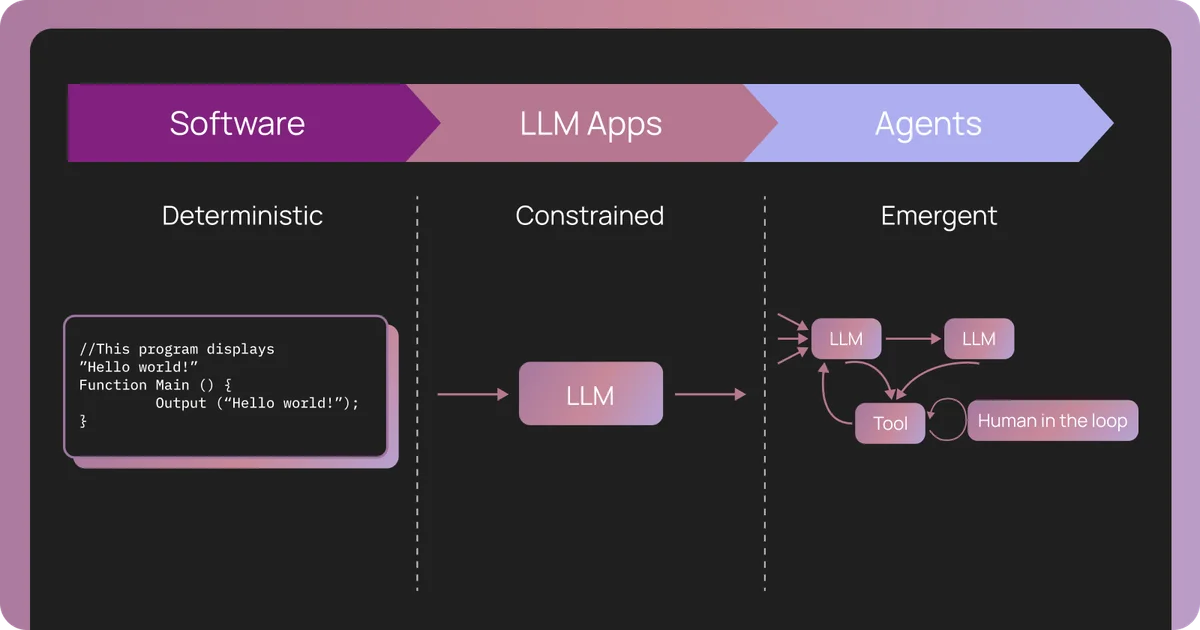
До эпохи больших языковых моделей (LLM) программное обеспечение было преимущественно детерминированным. При одних и тех же входных данных мы получали одинаковый результат. Логика была жестко прописана в коде. Если что-то ломалось, логи указывали на конкретный сервис или функцию, и разработчик исправлял ошибку в коде.
С появлением простых LLM-приложений (цепочек) добавилась неопределенность естественного языка, но структура оставалась линейной: один запрос — один ответ. Агенты же меняют всё кардинально. Они работают в цикле, самостоятельно принимая решения о вызове инструментов и сохраняя контекст на протяжении десятков или сотен шагов. Здесь источником истины становится не код, а трассировка (trace) реального поведения модели.
Детали
Когда агент ошибается, проблема редко заключается в том, что функция вернула исключение. Проблема звучит иначе: «Почему на 23-м шаге из 200 агент решил отредактировать файл вместо того, чтобы прочитать его?». Традиционные инструменты мониторинга здесь бессильны, так как они фиксируют время отклика и статус кода, но не контекст принятия решений.
LangChain выделяет три примитива новой наблюдаемости:
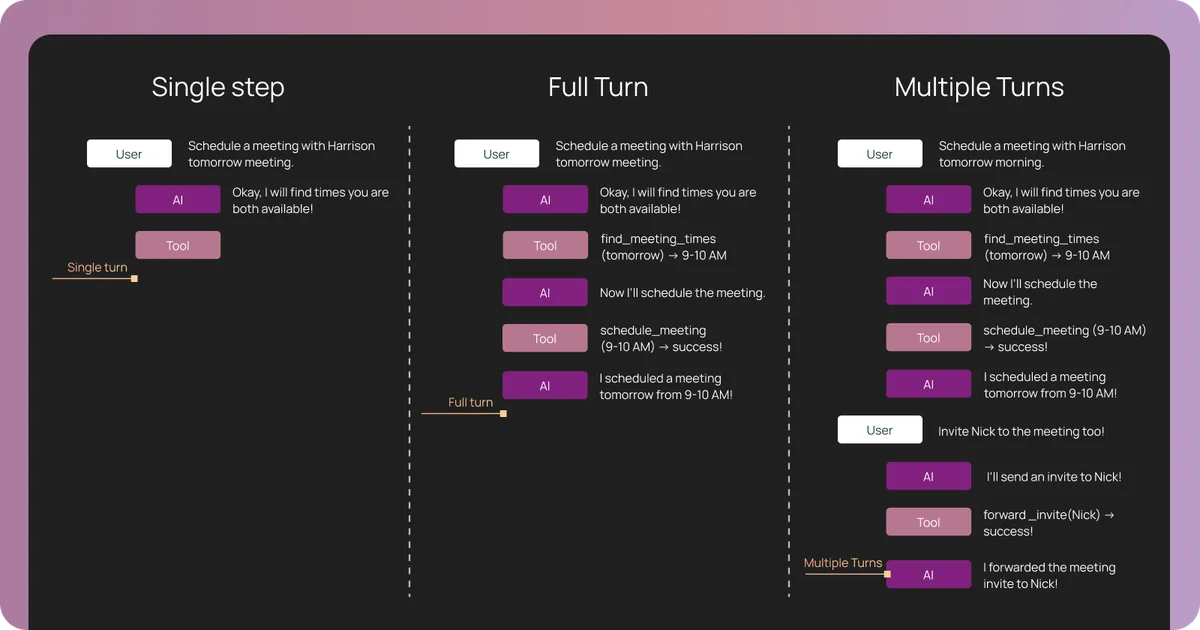
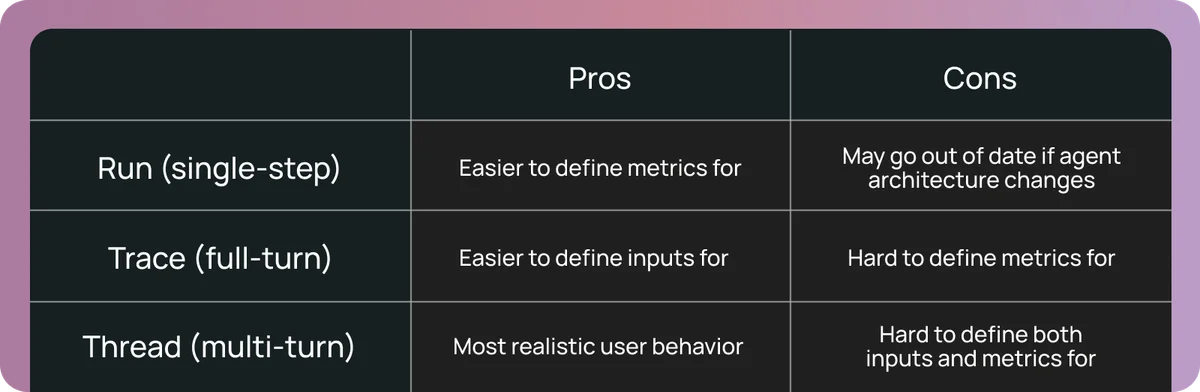
- Запуски (Runs): Единичный шаг выполнения (один вызов LLM). Это аналог юнит-теста для рассуждений: правильно ли модель выбрала инструмент в конкретной ситуации?
- Трассировки (Traces): Полная запись выполнения задачи, связывающая все запуски. Они могут быть огромными по объему, но необходимы для понимания того, где логика свернула не туда.
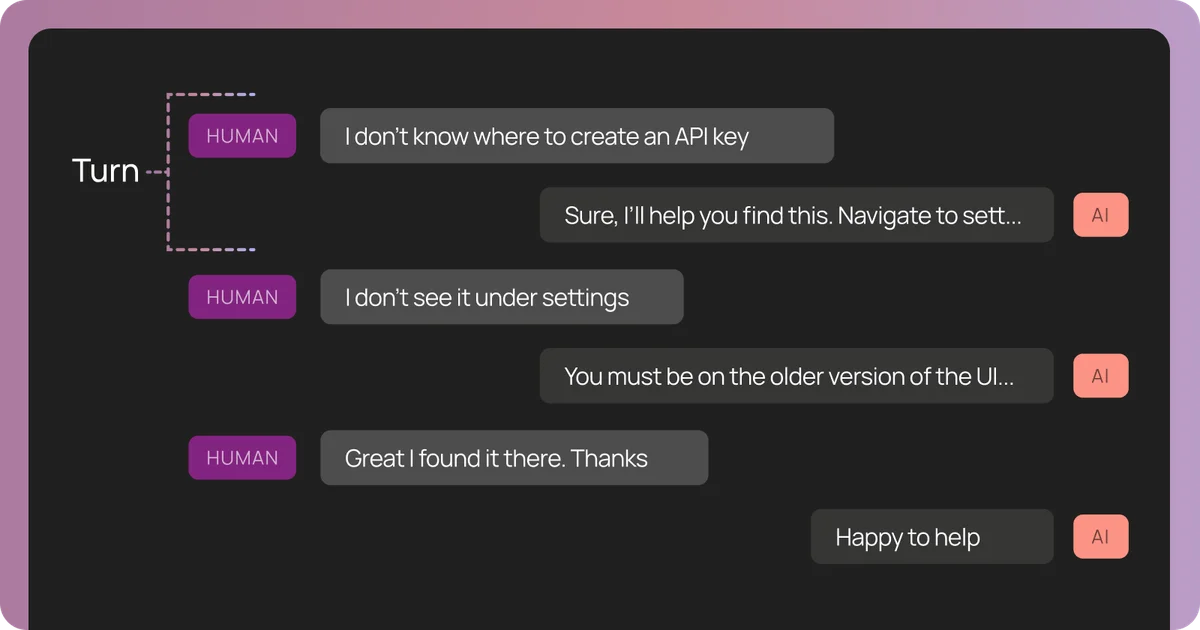
- Потоки (Threads): Группировка нескольких трассировок в одну сессию. Это критично для агентов, которые помнят историю общения. Ошибка на 11-м шаге может быть следствием неверного сохранения информации в память на 6-м шаге.
Анализ
Этот сдвиг означает, что продакшн становится главной средой обучения. В классической разработке тестирование в продакшене — это риск. В агентной разработке — это необходимость. Поскольку вариативность естественного языка бесконечна, вы не сможете предусмотреть все сценарии в оффлайн-тестах (pre-production).
Реальные пользовательские трассировки превращаются в новые тестовые кейсы. Если пользователь задал вопрос так, как вы не ожидали, и агент ошибся, этот лог становится основой для нового теста. Оценка агентов (evaluation) перестает быть разовым этапом перед релизом и становится непрерывным процессом, неразрывно связанным с наблюдаемостью.
Мы переходим от тестирования путей выполнения кода (code paths) к тестированию рассуждений. Это требует проверки на разных уровнях: принял ли агент верное решение сейчас (single-step), выполнил ли задачу целиком (full-turn) и удержал ли контекст беседы (multi-turn).
Перспектива
Индустрия движется к стандартизации инструментов для «отладки мышления». В ближайшем будущем мы увидим рост платформ, которые не просто показывают логи, а автоматически анализируют трассировки агентов, выявляя паттерны неудачных рассуждений. Разработчикам придется освоить новые навыки: вместо написания жестких assert-проверок они будут создавать наборы данных для оценки (eval sets) и курировать логику поведения моделей, превращаясь из «писателей кода» в «архитекторов систем рассуждения».