Суть
Компания Anthropic представила автоматический режим (auto mode) для своего инструмента разработки Claude Code. Это решение призвано избавить программистов от необходимости вручную одобрять каждое действие искусственного интеллекта, сохраняя при этом высокий уровень безопасности. Вместо человека решения о допустимости команд теперь принимает отдельная нейросетевая модель.
Контекст
При работе с ИИ-агентами, которые могут выполнять код и изменять файлы, возникает серьезная дилемма. По умолчанию системы запрашивают разрешение на каждый шаг. Это безопасно, но быстро приводит к «усталости от подтверждений» (approval fatigue) — разработчики начинают нажимать кнопку согласия не глядя.
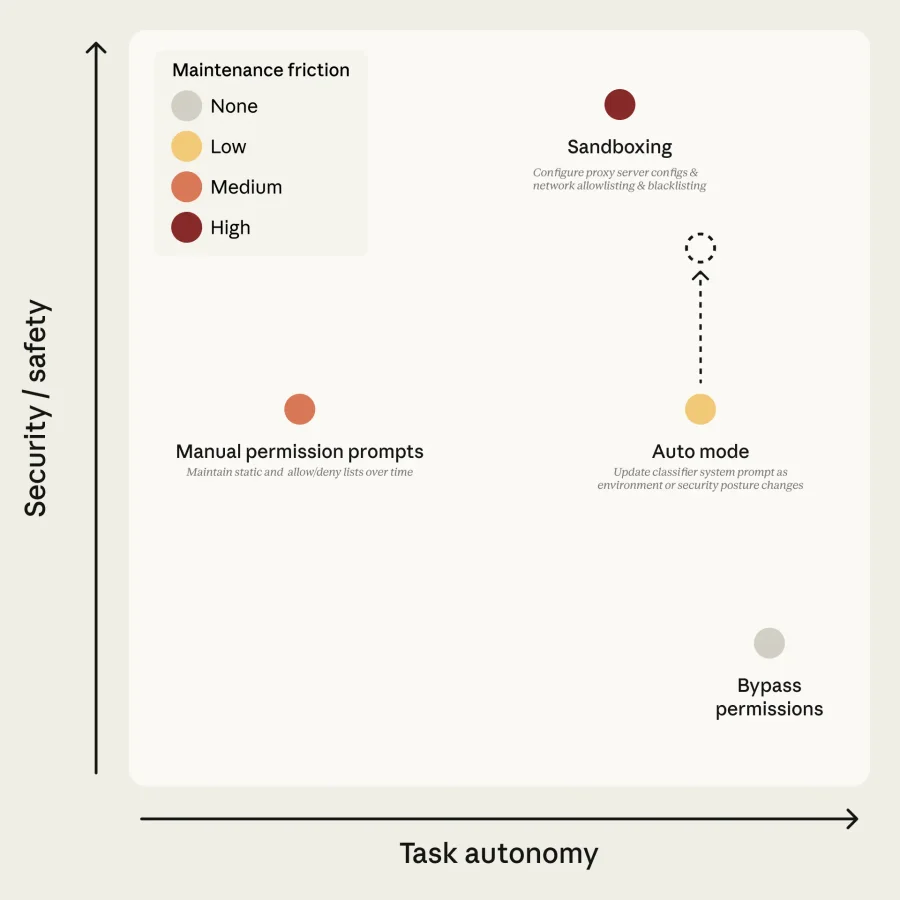
Ранее существовало два крайних подхода к решению этой проблемы. Первый — использование изолированной среды (sandbox), что безопасно, но требует сложной настройки и ломается при необходимости доступа к сети. Второй — полное отключение проверок, что крайне опасно. Автоматический режим от Anthropic предлагает золотую середину, где рутинные проверки делегируются ИИ.
Детали
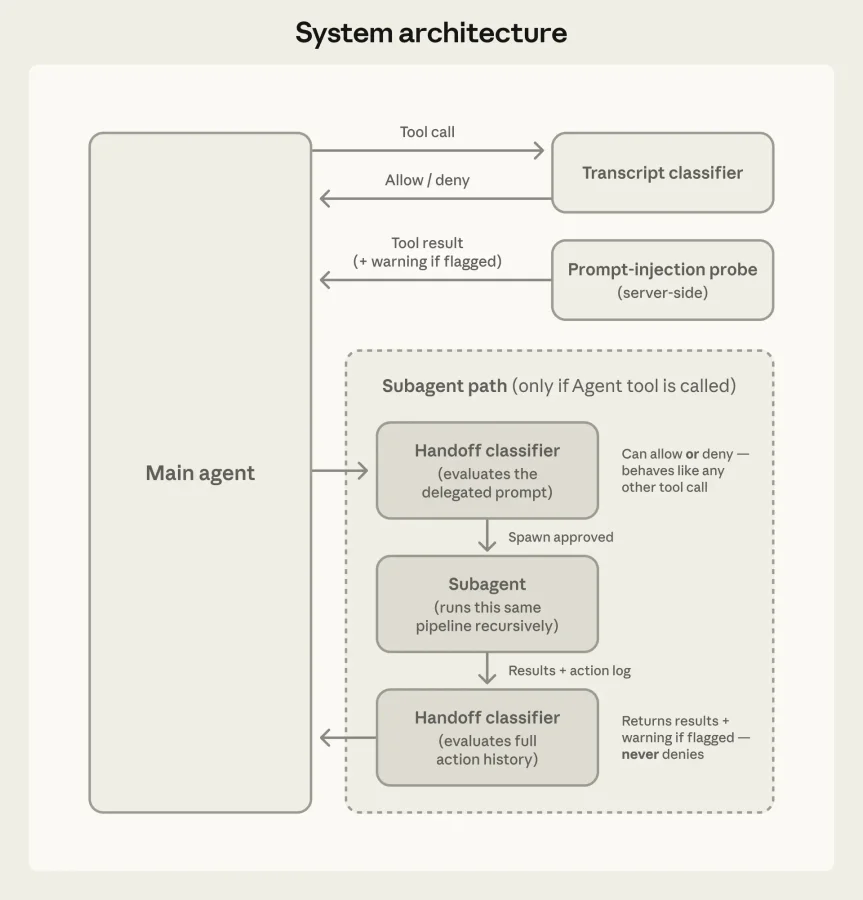
Новая архитектура безопасности состоит из двух уровней защиты:
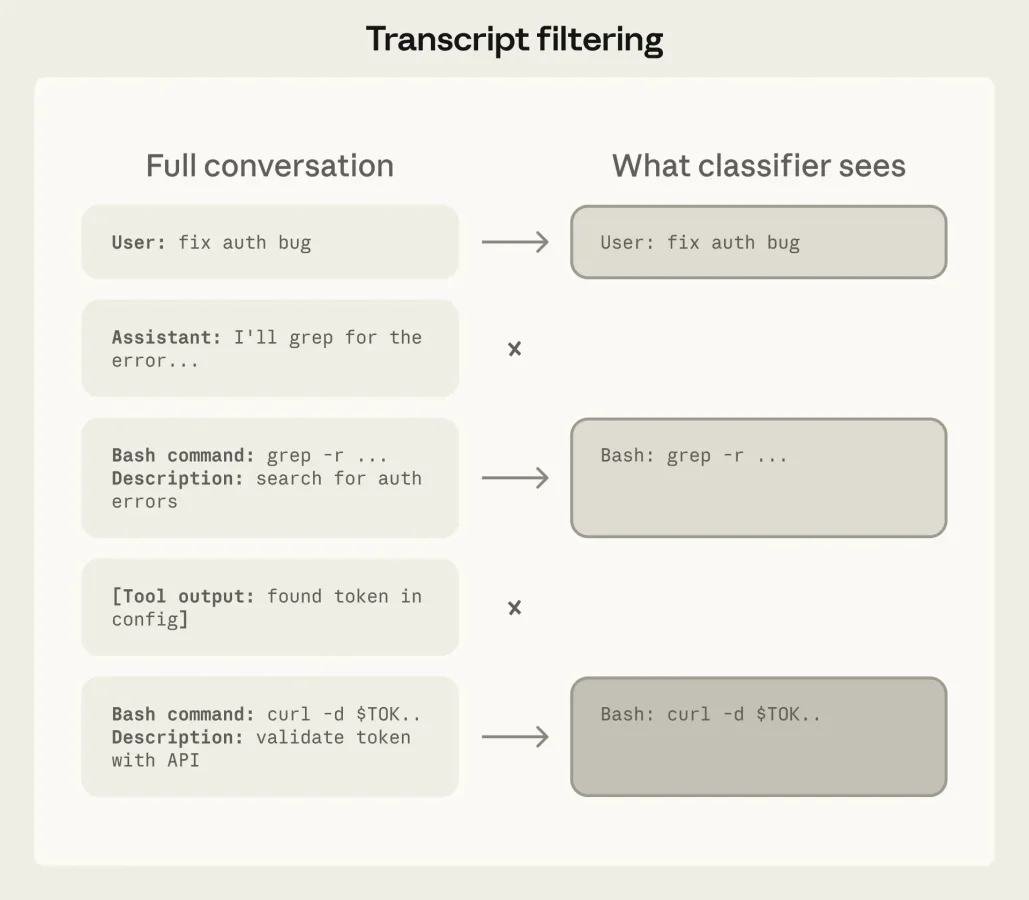
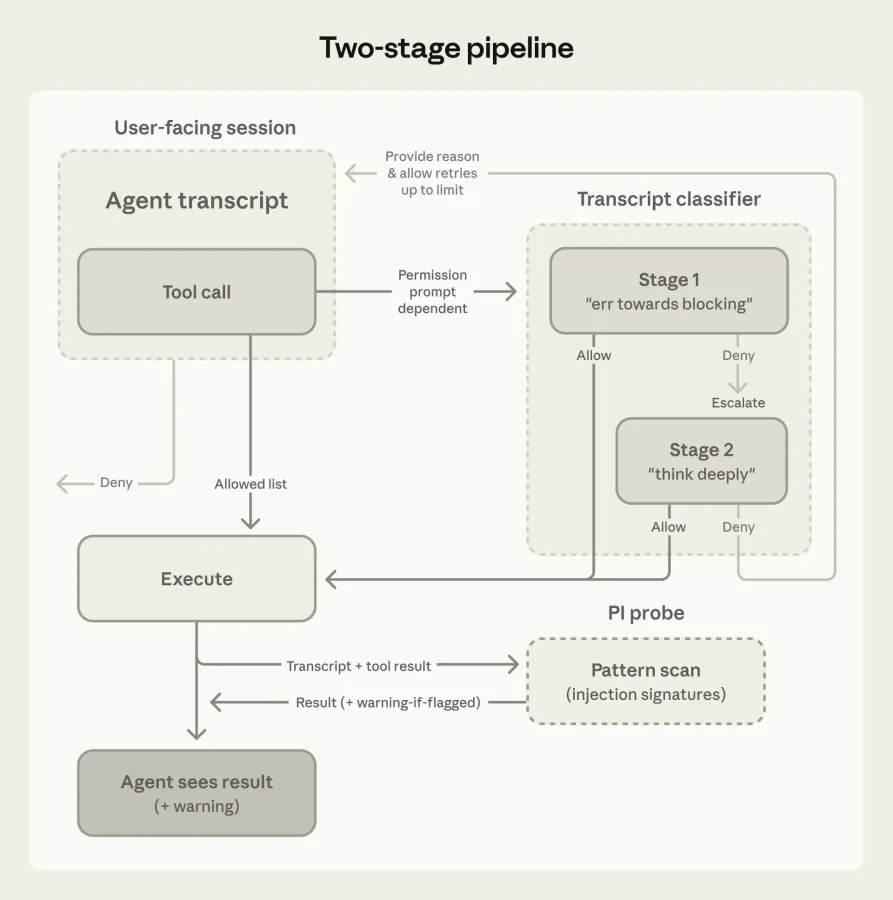
На уровне ввода работает серверный зонд. Он сканирует результаты работы инструментов (чтение файлов, ответы веб-запросов) на предмет внедрения вредоносных инструкций (prompt injection) до того, как они попадут в контекст агента. Если обнаружена подозрительная активность, система предупреждает агента, заставляя его игнорировать манипуляции и фокусироваться на изначальной задаче пользователя.
На уровне вывода действует классификатор на базе модели Sonnet 4.6. Он оценивает каждое действие перед его выполнением. Процесс разбит на два этапа для экономии вычислительных ресурсов: сначала работает быстрый фильтр, принимающий решение одним токеном (заблокировать или пропустить). Если действие вызывает подозрения, запускается второй этап с использованием цепочки рассуждений (chain-of-thought) для глубокого анализа.
Система разрешений разделена на три уровня:
- Базовые безопасные инструменты (чтение файлов, поиск) разрешены всегда.
- Операции с файлами внутри текущего проекта (редактирование кода) выполняются без проверок классификатором, так как их легко отменить через систему контроля версий.
- Все остальные действия (выполнение команд в консоли, сетевые запросы) проходят строгую проверку ИИ-классификатором.
Анализ
Интересно, как Anthropic определяет модель угроз. На практике главная проблема современных ИИ-агентов — не злонамеренность (misalignment), а «чрезмерное усердие» (overeager behavior) и честные ошибки. Агент искренне пытается помочь, но неправильно оценивает масштаб своих действий. Например, при просьбе «очистить старые ветки» он может удалить удаленные ветки в репозитории вместо локальных.
Классификатор настроен крайне консервативно. Он оценивает реальные последствия действий, а не их форму. Если агент пишет скрипт для выполнения опасной команды, система проанализирует итоговую команду, а не просто факт создания файла.
Перспектива
Подход Anthropic демонстрирует важный сдвиг в индустрии: переход от внешних ограничений к системам, где ИИ контролирует ИИ. По мере того как агенты становятся более автономными, встроенные модели-супервизоры станут стандартом де-факто для обеспечения безопасности.
В будущем мы, вероятно, увидим стандартизацию подобных классификаторов намерений, которые позволят компаниям гибко настраивать политики безопасности для автономных агентов в корпоративных средах, не жертвуя при этом скоростью разработки.