Анализ отчета Anthropic: почему пользователи заметили ухудшение работы Claude Code
Разбор трех технических ошибок, которые привели к временному снижению качества ответов Claude Code, и выводы компании для предотвращения подобных ситуаций.

Суть
Компания Anthropic опубликовала детальный отчет об ошибках (postmortem) в ответ на жалобы пользователей об ухудшении работы инструмента Claude Code. Расследование показало, что проблема заключалась не в деградации базовых моделей, а в трех независимых изменениях на уровне продукта и интерфейса. Все проблемы были устранены, а этот случай стал важным уроком по управлению качеством ИИ-систем.
Контекст
Создание продуктов на базе больших языковых моделей (LLM) — это постоянный поиск компромисса между качеством ответов, скоростью работы и стоимостью вычислений. В случае с Claude Code инженеры пытались оптимизировать пользовательский опыт: уменьшить задержки и снизить расход лимитов. Однако эти благие намерения, наложившись друг на друга в короткий промежуток времени, создали у пользователей ощущение глобальной деградации интеллекта модели.
Детали
Изображение из источника
В ходе расследования инженеры выявили три отдельные проблемы, повлиявшие на разные группы пользователей.
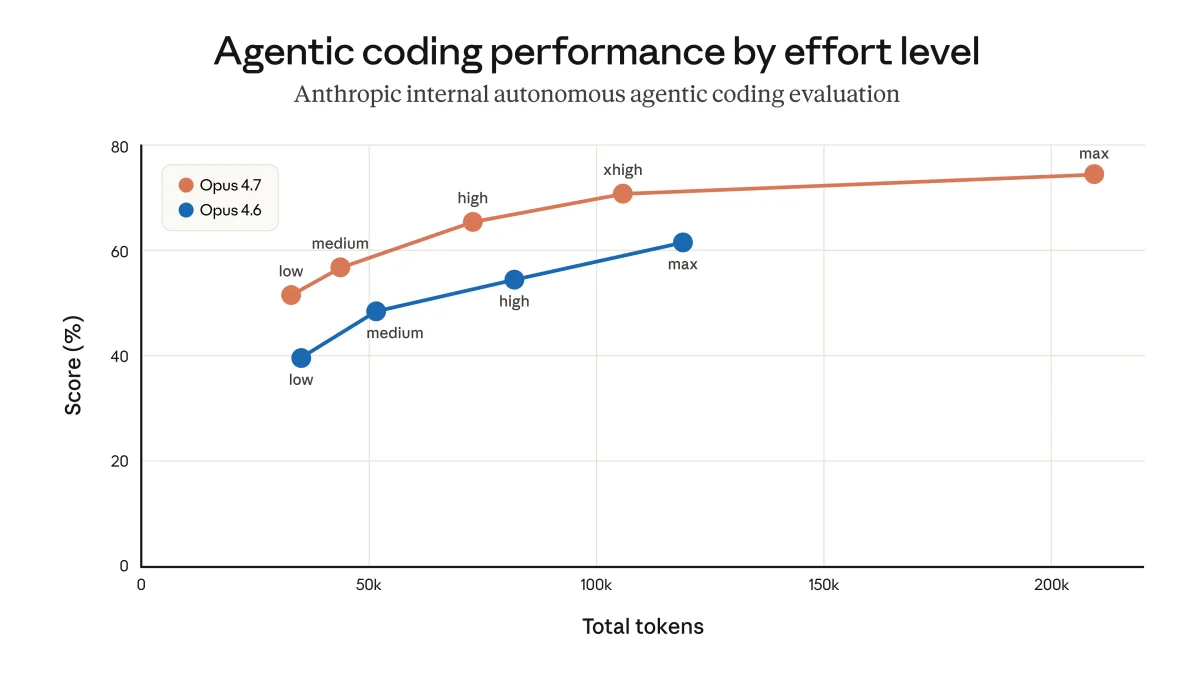
Во-первых, изменение уровня усилий для размышлений (reasoning effort). В начале марта разработчики сделали средний уровень размышлений настройкой по умолчанию, чтобы интерфейс не казался «зависшим» при сложных запросах. Оказалось, что пользователи предпочитают ждать дольше, но получать максимально качественный результат. Изменение было отменено.
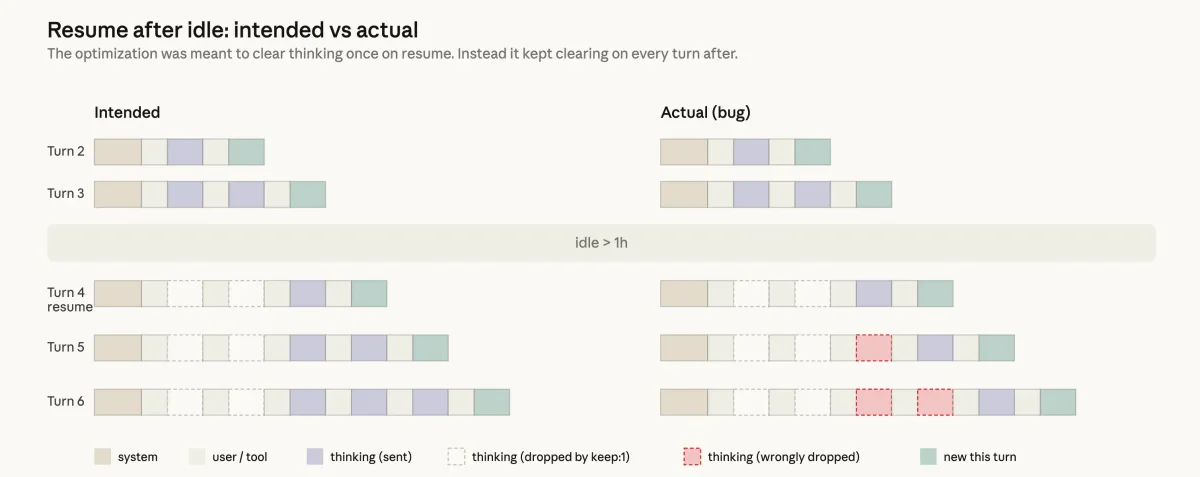
Во-вторых, ошибка в оптимизации кэширования. Чтобы ускорить возобновление старых сессий, разработчики внедрили функцию очистки старых «размышлений» модели после часа неактивности. Из-за программной ошибки эта очистка начала срабатывать на каждом шаге диалога. Модель постоянно теряла контекст своих предыдущих действий, что выглядело как забывчивость и повторения.