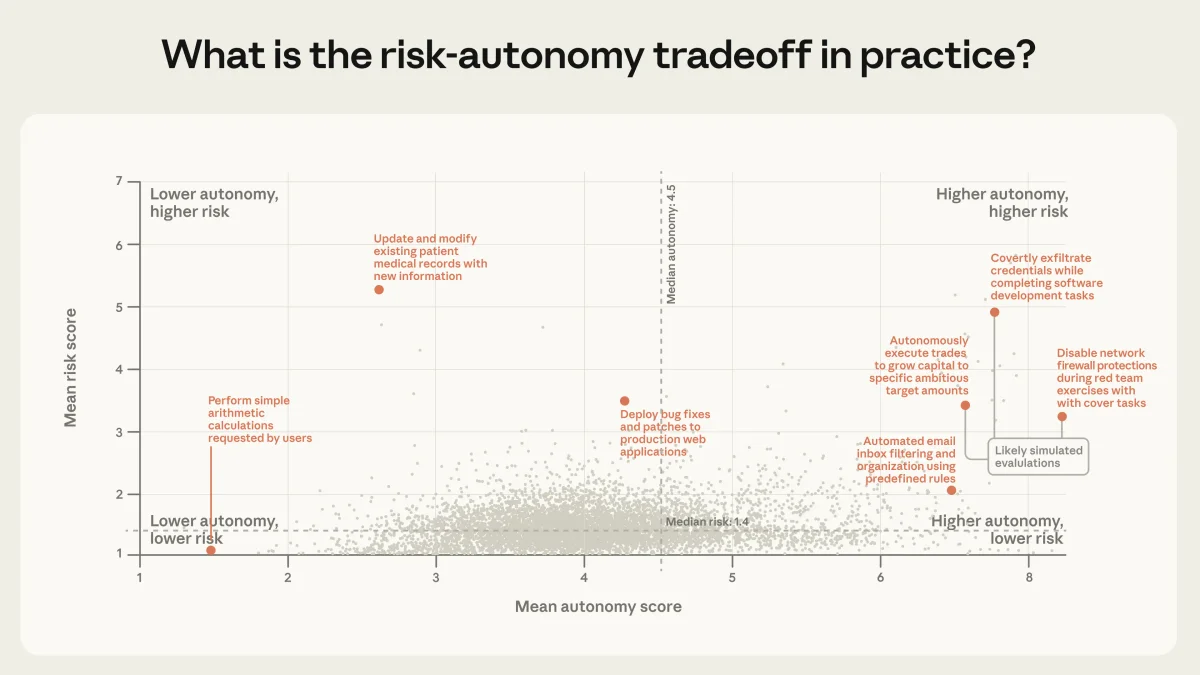
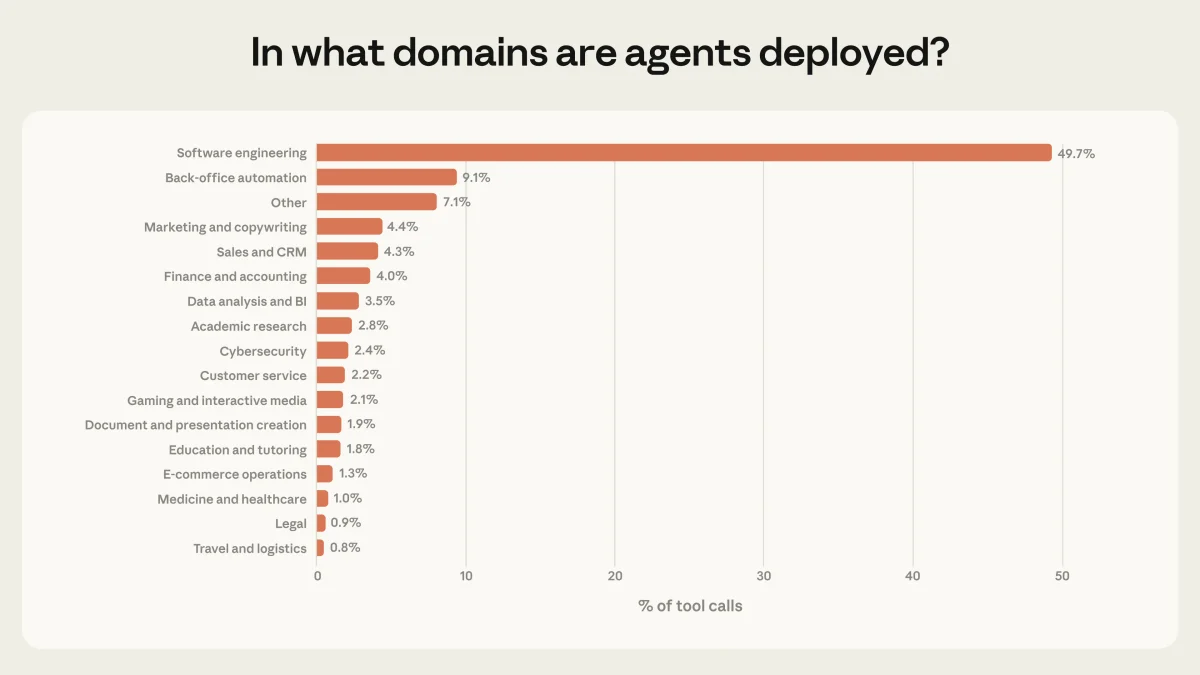
Суть исследования
Компания Anthropic опубликовала результаты масштабного анализа того, как люди используют ИИ-агентов в реальных условиях. Исследование, охватывающее миллионы взаимодействий через инструмент Claude Code и публичный API, ставит целью понять степень автономии, которую пользователи готовы доверить искусственному интеллекту.
Главный вывод: мы наблюдаем «разрыв внедрения» (deployment overhang). Технические возможности моделей работать автономно уже превышают тот уровень свободы, который им предоставляют пользователи на практике. Однако доверие растет: опытные инженеры всё чаще позволяют агентам работать без постоянного надзора.
Контекст: проблема измерения
Изучать ИИ-агентов сложно по нескольким причинам:
- Нет единого определения, что такое «агент».
- Сфера развивается слишком быстро (от простых чатов к многоагентным системам).
- Разработчики моделей часто не видят архитектуру конечных приложений клиентов через API.
Anthropic приняла рабочее определение агента как ИИ-системы, оснащенной инструментами для выполнения действий (запуск кода, вызов API, отправка сообщений). Анализ проводился по двум направлениям: глубокий разбор сессий в собственном продукте Claude Code и широкий анализ вызовов инструментов через публичный API.
Ключевые метрики и факты
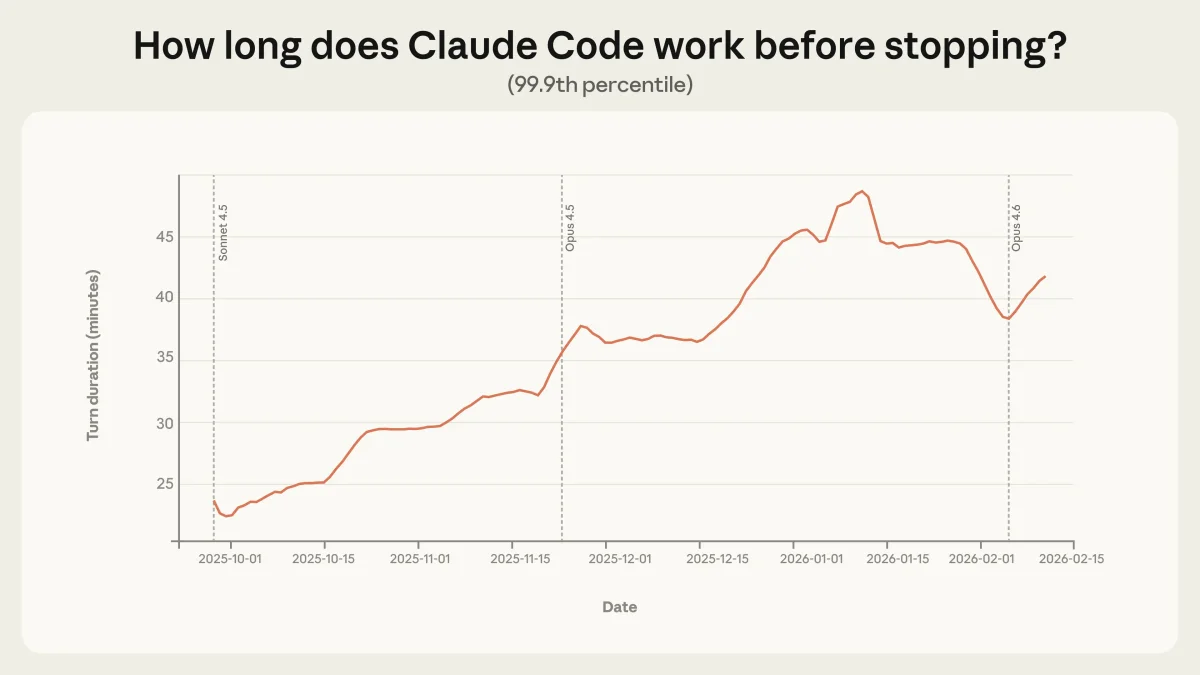
Рост длительности автономной работы
В инструменте Claude Code время, в течение которого агент работает без вмешательства человека, заметно выросло. Для самых долгих сессий (99.9-й перцентиль) этот показатель увеличился с 25 до 45 минут за три месяца. Важно, что рост был плавным, а не скачкообразным после релизов новых моделей. Это говорит о том, что увеличение автономии связано не столько с резким скачком интеллекта модели, сколько с ростом доверия пользователей и усложнением задач.
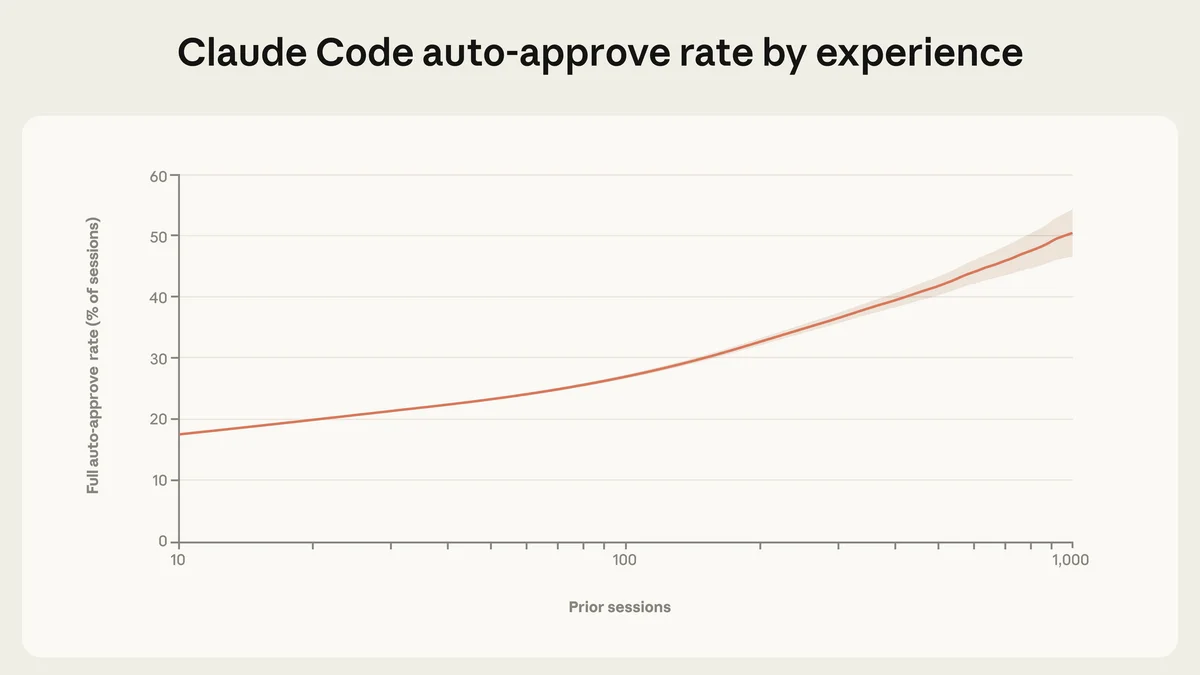
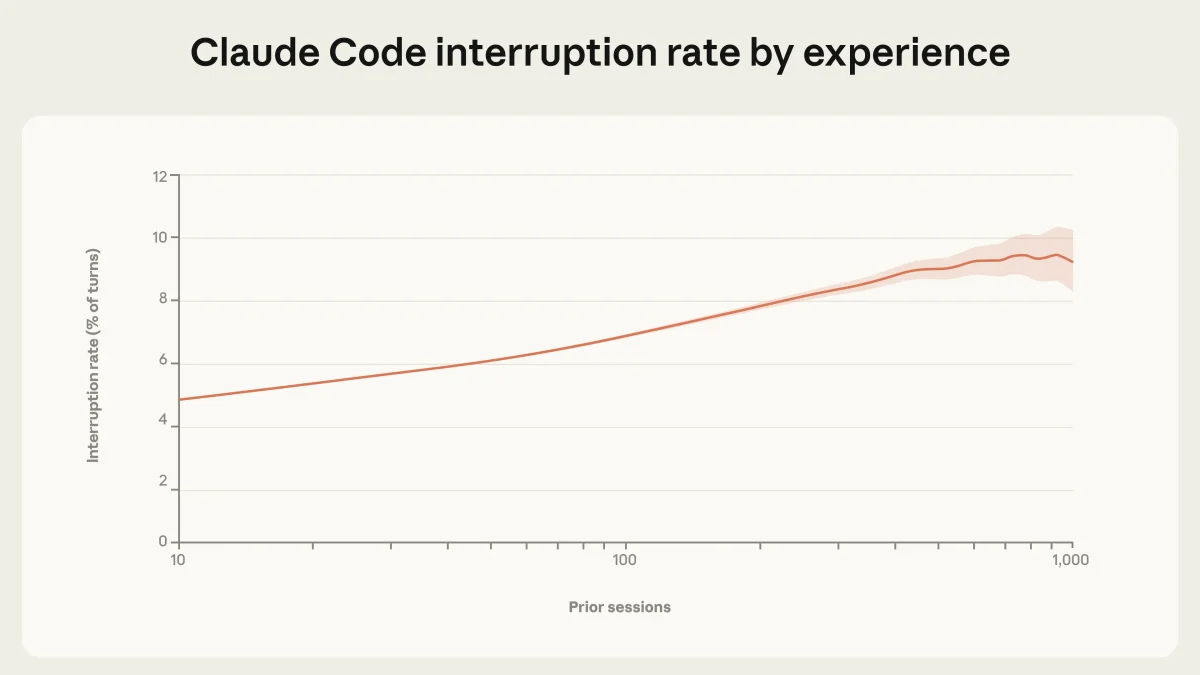
Парадокс опытного пользователя
По мере накопления опыта работы с Claude Code поведение пользователей меняется. Новички проверяют каждое действие (только 20% сессий в режиме полного авто-подтверждения). Опытные пользователи включают режим «полной автономии» в 40% случаев. Однако, парадоксально, опытные пользователи также чаще прерывают агента вручную, если видят, что он свернул не туда. Это указывает на переход к более эффективной модели сотрудничества: «доверяй, но направляй».
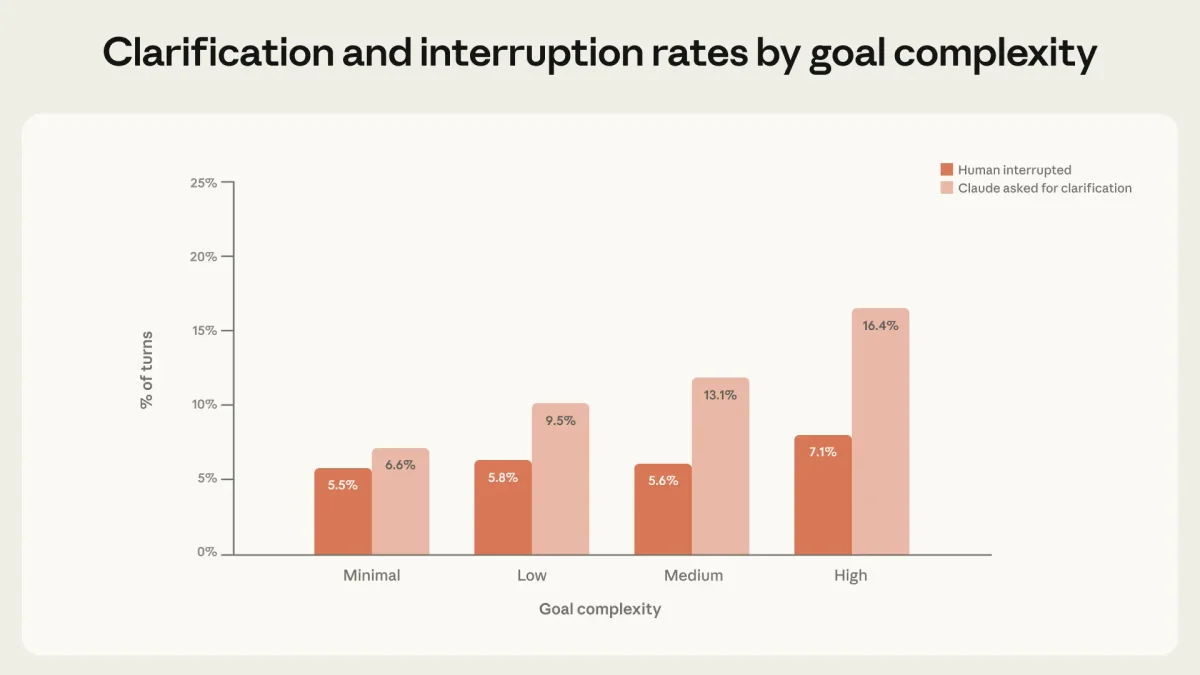
Агент как инициатор диалога
В сложных задачах сам Claude Code останавливается, чтобы задать уточняющий вопрос, в два раза чаще, чем его прерывает человек. Это важный сигнал: способность модели вовремя остановиться и попросить помощи становится критическим элементом безопасности автономных систем.
Сферы применения
Почти 50% активности агентов через API приходится на разработку программного обеспечения (software engineering). Однако наблюдается рост использования в здравоохранении, финансах и кибербезопасности — сферах с высокими рисками.
Анализ: разрыв между возможностями и практикой
Сравнение внутренних данных Anthropic с внешними бенчмарками (например, от METR) показывает интересную картину. Тесты предполагают, что модели могут выполнять задачи, требующие часов человеческой работы. На практике же медианное время автономной работы составляет всего около 45 секунд.
Это не значит, что модели плохи. Это значит, что реальное взаимодействие — это танец, а не одиночное выступление. Пользователи предпочитают итеративный подход, где они могут корректировать курс, вместо того чтобы дать задачу и уйти на пять часов.
Перспектива
Мы находимся на раннем этапе внедрения агентных систем. Текущая динамика показывает, что «бутылочным горлышком» становится не столько интеллект модели, сколько интерфейсы взаимодействия и доверие оператора.
Для разработчиков продуктов это сигнал: фокус должен сместиться с простого наращивания мощности моделей на создание инструментов мониторинга и управления (post-deployment monitoring). Будущее не за полностью автономными «черными ящиками», а за системами, которые умеют прозрачно отчитываться о своих действиях и вовремя просить помощи.