Суть
В индустрии разработки искусственного интеллекта наметился важный тренд: отказ от идеи «всемогущего агента» в пользу гибридных архитектур. Анализ реальных внедрений показывает, что наиболее эффективные системы передают большим языковым моделям (LLM) лишь часть задач, оставляя до 90% работы старому доброму программному коду. Это не шаг назад, а признак взросления технологии: мы начинаем понимать, где нейросети действительно незаменимы, а где они лишь усложняют процесс и снижают надежность.
Контекст
Еще полгода назад подход к созданию AI-агентов был максималистским. Разработчики стремились создать системы, где модель получала бы задачу (например, «исследуй этот рынок») и самостоятельно выполняла все шаги: от поиска инструментов до структурирования данных. Это называлось «полностью агентным» подходом.
Однако практика показала слабости такой архитектуры. Модели, получив полную свободу, часто «галлюцинировали», выбирали неверные инструменты или застревали в бесконечных циклах попыток. Попытки ограничить их с помощью промптов (инструкций) или специальных инструментов помогали лишь отчасти. Надежность таких систем в продакшене оставалась низкой, а стоимость — высокой из-за огромного количества токенов, расходуемых на размышления модели.
Julius Workflow Determinism
Детали
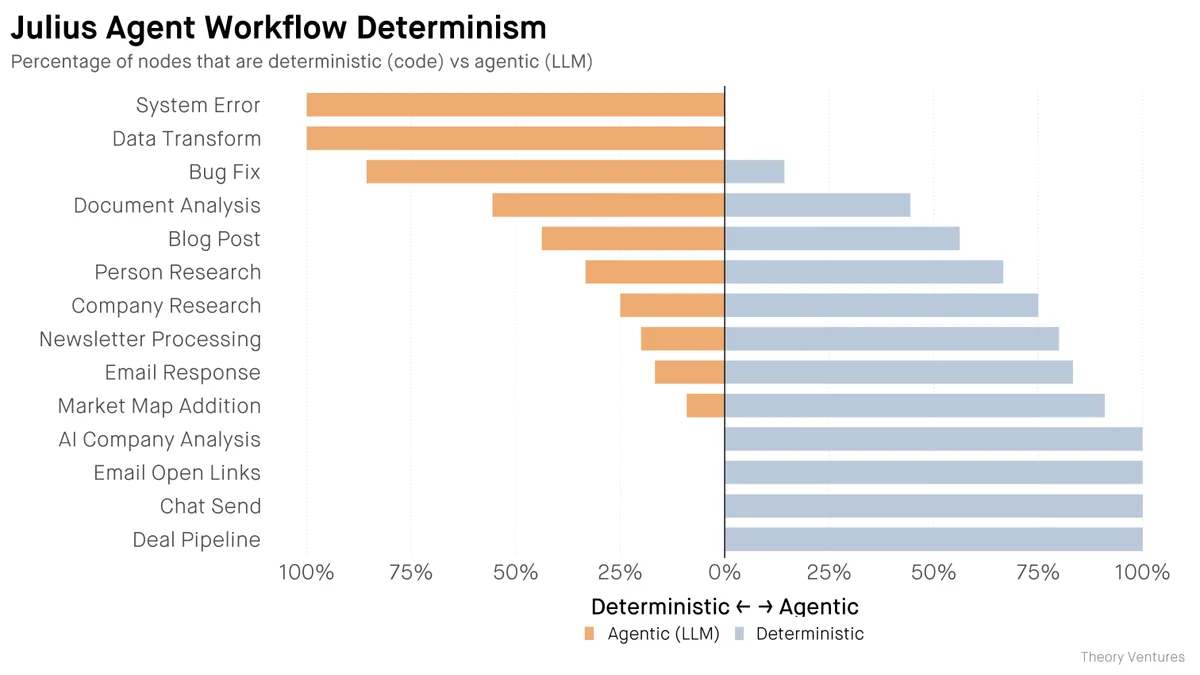
Том Тунгуз, известный венчурный инвестор и аналитик, провел исследование 14 рабочих процессов AI-агентов. Результаты оказались показательными. В оптимизированных системах около 65% узлов рабочего процесса выполняются как чистый, детерминированный код, без участия нейросетей.
Архитектура сместилась в сторону так называемых «чертежей» (blueprints). Это жестко прописанные в коде графы, где четко определены шаги, переходы и условия. В отличие от навыков (skills), которые просто говорят модели, что делать, чертежи определяют, когда вообще стоит привлекать модель.
Пример эффективной цепочки выглядит так:
- Извлечение домена (обычный код).
- Поиск данных в CRM (обычный код).
- Обогащение данных через API (обычный код).
- Генерация саммари (LLM, всего один шаг).
- Сохранение в базу знаний (обычный код).
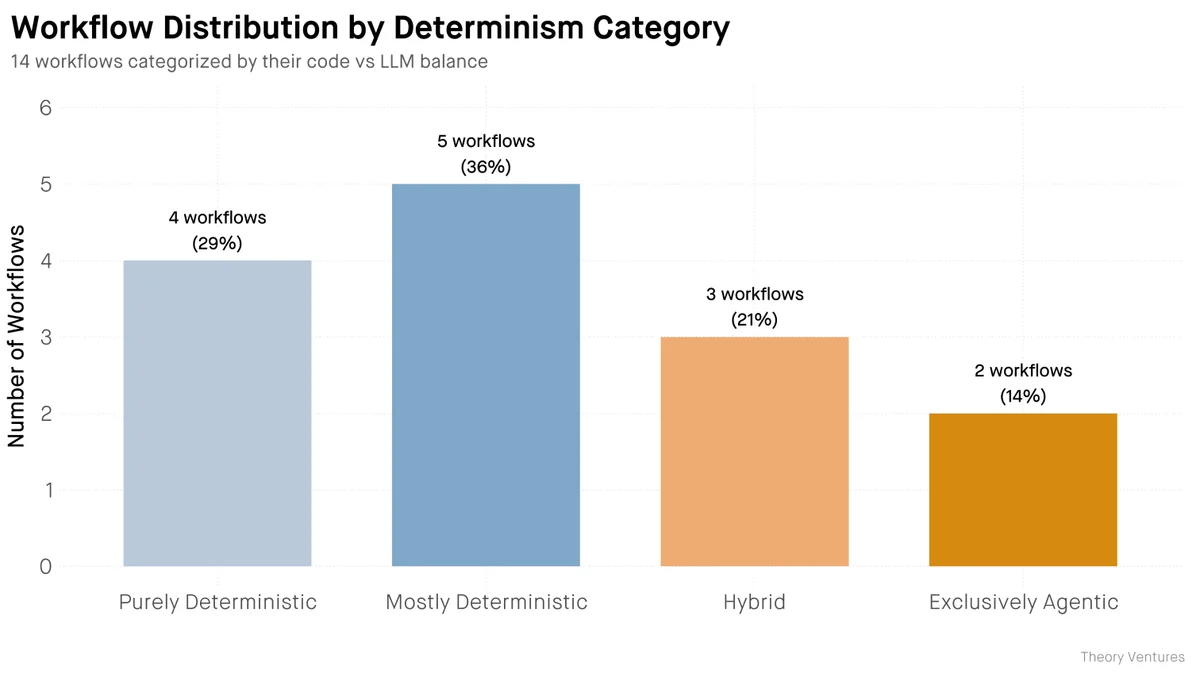
Статистика распределения задач выглядит следующим образом:
- 29% рабочих процессов (обновление сделок, маршрутизация писем) вообще не требуют вызова LLM.
- 36% задач (исследование компаний, обработка новостей) используют код на 67–91%, привлекая AI только для извлечения смысла и синтеза.
- 21% задач являются истинно гибридными (написание постов, анализ документов), где требуется итеративная работа модели.
- Лишь 14% задач остаются полностью агентными (сложные трансформации данных, расследование ошибок), где модели нужна свобода для экспериментов.
Анализ
Этот сдвиг напоминает архитектуру «миньонов», которую ранее описывали инженеры Stripe: детерминированный код обрабатывает предсказуемое, а LLM берут на себя неопределенность. Мы видим переход от «магического» мышления к инженерному прагматизму.
Когда модель получает только необходимый контекст (фрагмент текста для резюмирования или список для категоризации), она работает точнее и дешевле. Ей не нужно планировать весь маршрут — маршрут уже проложен инженером. Это снижает вероятность ошибок и делает поведение системы предсказуемым, что критически важно для бизнеса.
Фактически, AI делает меньше в процентном соотношении, но сама система становится более мощной и полезной. Мы перестаем использовать микроскоп для забивания гвоздей.
Перспектива
Значит ли это, что роль AI будет снижаться и дальше? Скорее всего, нет. Текущие «чертежи» и жесткие рамки могут оказаться временными строительными лесами.
По мере выхода новых, более мощных моделей (таких как ожидаемые GPT-5 или Claude 4), границы возможностей снова расширятся. Задачи, которые сегодня требуют написания жесткого кода из-за ненадежности текущих моделей, завтра могут быть снова делегированы AI. Это динамический баланс: сегодня мы ограничиваем AI ради надежности, но завтра расширим его полномочия ради гибкости.