Gemini 3.1 Flash-Lite: Google делает ставку на скорость и экстремально низкую цену
Google представила самую быструю и дешёвую модель в линейке Gemini 3. Новинка ориентирована на массовые операции и задачи, требующие мгновенного отклика, при этом сохраняя высокие показатели качества.

Суть события
Google объявила о запуске новой модели искусственного интеллекта — Gemini 3.1 Flash-Lite. Это решение позиционируется как самый быстрый и экономически эффективный инструмент в третьем поколении моделей Gemini. Главная цель выпуска — предоставить разработчикам и бизнесу доступ к качественному интеллекту для задач огромного масштаба, где критичны не столько глубина философских рассуждений, сколько скорость реакции и стоимость обработки данных.
Модель уже доступна в предварительном просмотре (preview) через Gemini API в Google AI Studio и для корпоративных клиентов через Vertex AI. По сути, Google продолжает агрессивную ценовую войну, предлагая инструменты, которые делают внедрение ИИ в повседневные бизнес-процессы рентабельным.
Технические детали и цифры
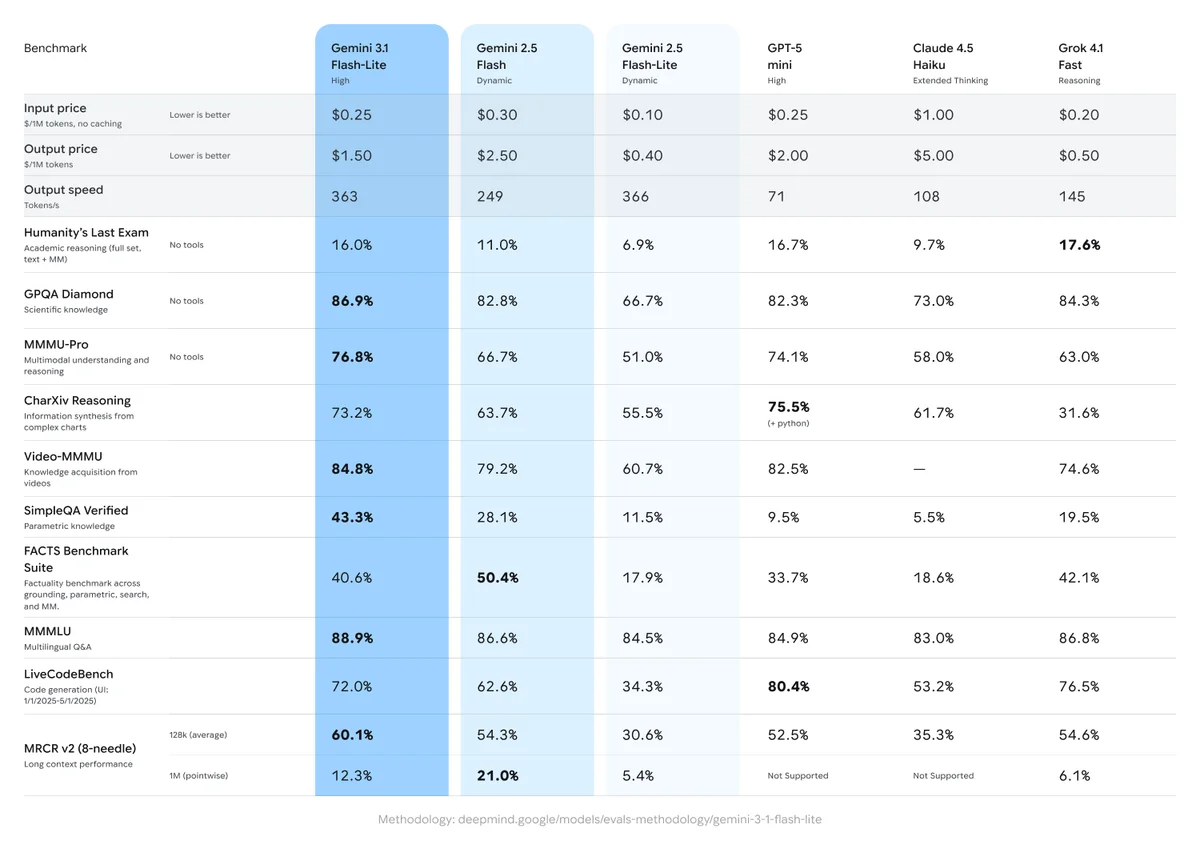
Самое важное в этом анонсе — это комбинация цены и производительности. Google заявляет следующие характеристики:
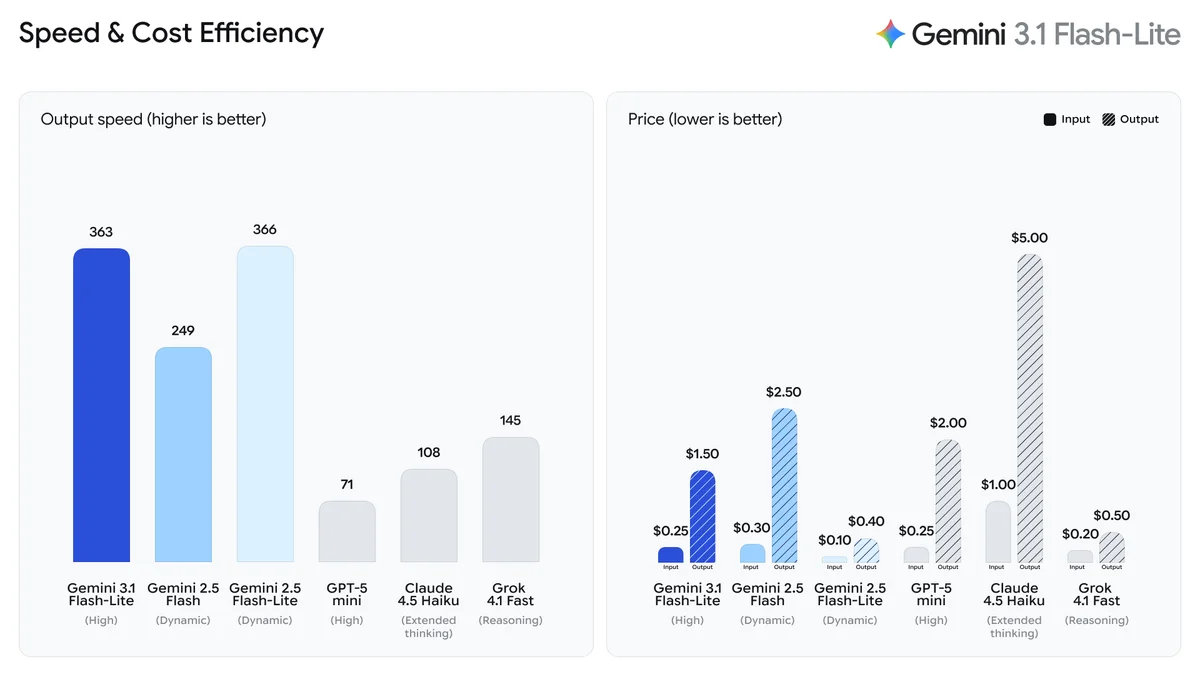
The image shows two bar charts titled "Speed & Cost Efficiency," comparing the "Output speed (higher is better)" and "Price (lower is better)" of Gemini 3.1 Flash-Lite against several other models, including Gemini 2.5 Flash-Lite, GPT-5 mini, Claude 4.5 Haiku, and Grok 4.1 Fast.
- Стоимость: $0.25 за 1 миллион входных токенов и $1.50 за 1 миллион выходных токенов. Это крайне низкий порог входа, позволяющий обрабатывать огромные массивы текста без разорения бюджета.