Взаимодействие ученых и разработчиков с искусственным интеллектом постепенно меняет свой формат. Если раньше работа строилась в режиме диалога, где человек контролировал каждый шаг модели, то сейчас индустрия переходит к автономным агентам. Исследователи из Anthropic продемонстрировали, как можно поставить перед ИИ высокоуровневую цель и оставить его работать самостоятельно на несколько дней. Это открывает новые возможности для научных вычислений и разработки сложного программного обеспечения.
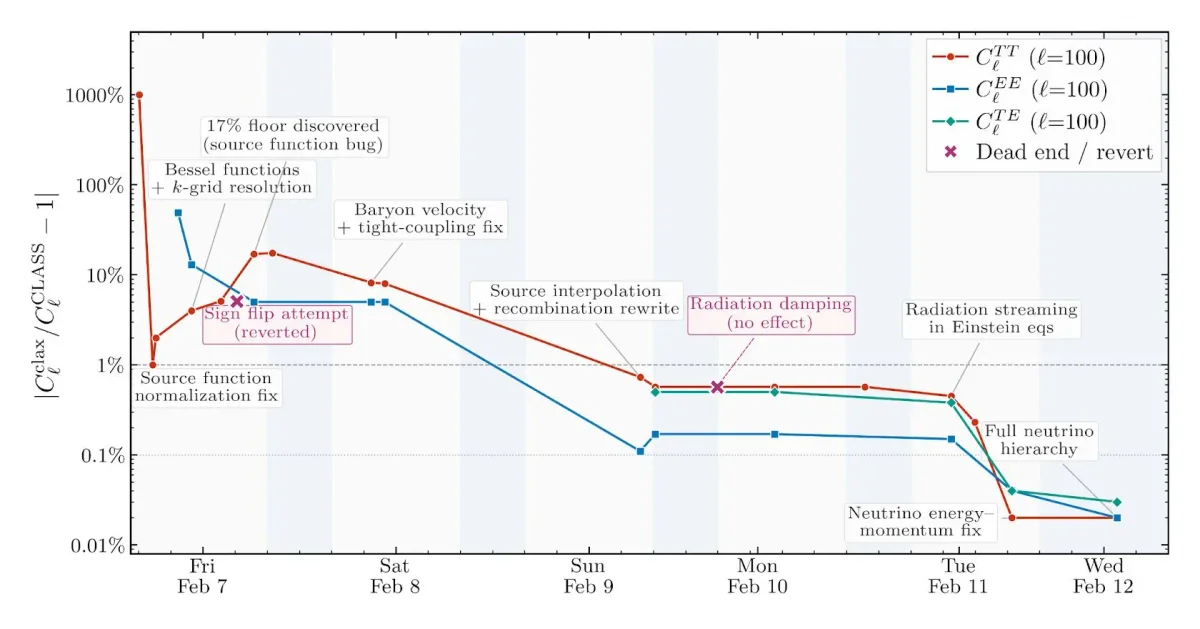
Традиционно перенос старого научного кода на современные языки программирования или создание новых математических решателей требует месяцев работы узких специалистов. В качестве эксперимента исследователь из Anthropic поручил модели Claude Opus создать дифференцируемую версию космологического решателя Больцмана на базе библиотеки JAX. Эта задача требует высокой точности, так как малейшая ошибка в расчетах ранней Вселенной приведет к искажению всех последующих данных. Важно отметить, что автор эксперимента не был глубоким экспертом в этой узкой области, выступая скорее в роли руководителя проекта.
Для успешной автономной работы агента потребовалось создать специальную поддерживающую инфраструктуру. Во-первых, это файл с инструкциями (CLAUDE.md), в котором зафиксированы цели проекта и критерии успеха. Модель может сама обновлять этот файл по мере продвижения. Во-вторых, агенту необходима долговременная память. Ее роль выполняет файл истории изменений (CHANGELOG.md), куда ИИ записывает текущий статус, выполненные задачи и, что критически важно, неудачные подходы. Это предотвращает хождение по кругу и повторение одних и тех же ошибок в разных сессиях.
Третьим важным элементом стал «тестовый оракул» — система проверки результатов. В данном случае использовалась эталонная реализация решателя на языке C. Агент постоянно писал и запускал модульные тесты, сравнивая свои результаты с эталоном. Для координации работы использовалась система контроля версий Git. Агенту было поручено делать коммиты после каждого осмысленного блока работы и успешного прохождения тестов. Это обеспечило сохранность прогресса и возможность отката в случае критической ошибки.
С технической точки зрения процесс запускался на вычислительном кластере через планировщик задач SLURM. Агент работал внутри терминального мультиплексора (tmux), что позволяло исследователю отключаться от сессии и проверять результаты в удобное время, например, просматривая изменения в репозитории с мобильного телефона.
Интересным наблюдением стала проблема «агентской лени». Современные модели при выполнении сложных многосоставных задач иногда склонны преждевременно завершать работу, заявляя, что задача выполнена или требует перерыва. Для борьбы с этим применялся так называемый «цикл Ральфа» (Ralph loop) — программный цикл, который принудительно возвращает агента в контекст задачи, пока не будет достигнут строгий математический критерий успеха (в данном случае — точность 0.1% по сравнению с эталоном).
Этот опыт показывает, что по мере развития больших языковых моделей (LLM) меняется и роль человека-оператора. Фокус смещается с написания конкретных промптов на проектирование надежных рабочих процессов, систем тестирования и управления памятью агента. В будущем такой подход может существенно ускорить развитие научной инфраструктуры, позволяя лабораториям делегировать рутинную, но сложную работу автономным ИИ-системам.