Суть
Microsoft Research обратила внимание на одну из главных проблем современной робототехники — разрыв между пониманием задачи и ее физическим выполнением. Исследователи представили GroundedPlanBench. Это платформа для оценки того, как визуально-языковые модели (VLM) справляются с долгосрочным планированием задач для роботов-манипуляторов с учетом точной пространственной привязки. Это важный шаг к созданию более автономных и надежных роботизированных систем.
Контекст
Сегодня визуально-языковые модели отлично описывают изображения и генерируют пошаговые инструкции. Однако, когда дело доходит до управления роботами, разработчики обычно используют уязвимый двухэтапный подход.
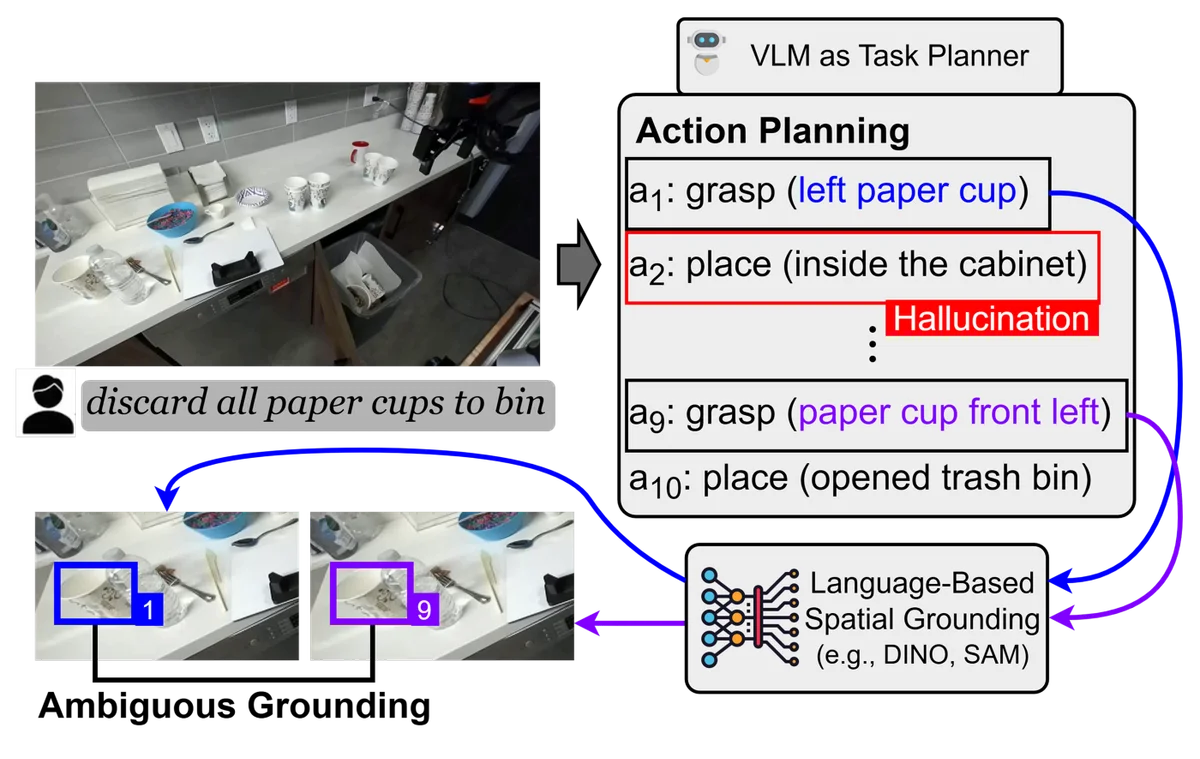
Figure 1: This figure shows some failure cases for a vision-language robot task planner. Given the instruction “discard all paper cups to bin,” the planner produces an action sequence with ambiguous cup references and a hallucinated step, “place inside the cabinet.” Cropped object views and arrows to a language-based spatial grounding module show that ambiguous grounding can lead to non-executable plans.
Сначала модель анализирует сцену через камеры и пишет текстовый план, например: «взять синюю деталь и поместить ее в контейнер». Затем отдельная программная система пытается перевести этот естественный язык в конкретные координаты и команды для моторов. Проблема заключается в том, что на этапе этого перевода теряется критически важный контекст. Текст редко содержит точные физические параметры, из-за чего система часто дает сбой, не понимая, как именно захватить объект или где именно находится препятствие.
Детали
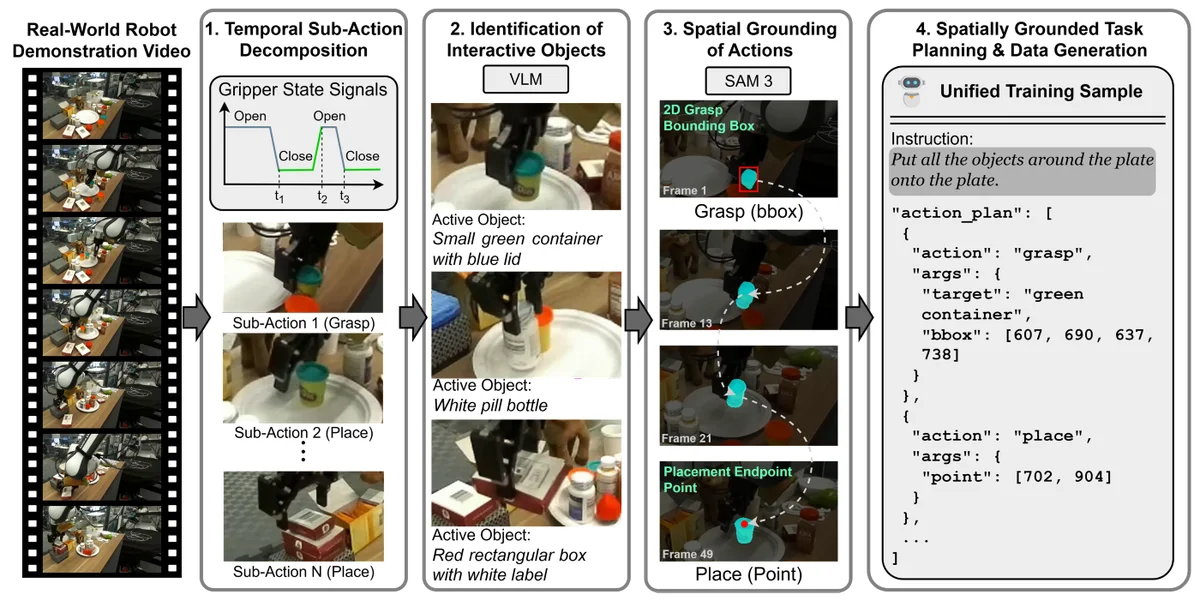
GroundedPlanBench фокусируется на двух сложных аспектах работы алгоритмов: пространственной привязке (spatial grounding) и долгосрочном планировании (long-horizon planning).
Пространственная привязка означает, что искусственный интеллект должен не просто идентифицировать объект на картинке, но и понимать его положение в трехмерном пространстве, оценивать габариты и доступность для захвата. Долгосрочное планирование требует удержания контекста на протяжении множества последовательных действий. При выполнении сложных задач ошибка на первом этапе делает невозможным выполнение десятого. Бенчмарк позволяет исследователям точно измерить, насколько хорошо модели справляются с этими вызовами, минуя ненадежные промежуточные переводы текста в код.
Анализ
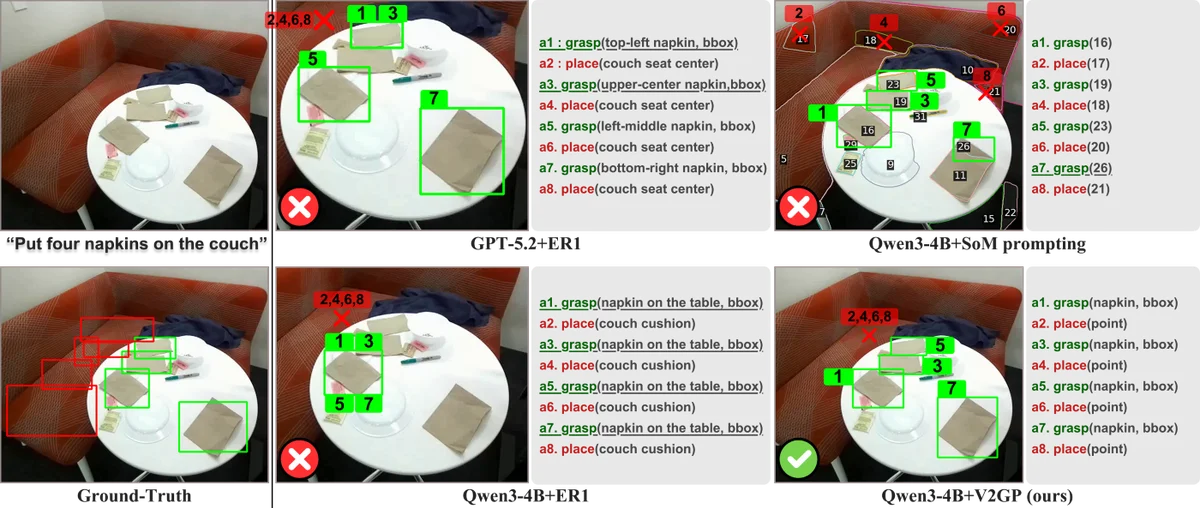
Figure 2: This figure shows two examples comparing explicit and implicit task instructions: one about placing bottles and a cup into a sink, and another about placing eggs and vegetables into a silver bowl. The figure shows that implicit instructions summarize explicit object lists into higher-level descriptions. This figure shows two examples comparing explicit and implicit task instructions: one about placing bottles and a cup into a sink, and another about placing eggs and vegetables into a silver bowl. The figure shows that implicit instructions summarize explicit object lists into higher-level descriptions.
Появление такого инструмента оценки указывает на важный сдвиг в индустрии. Разработчики осознали, что разделение логики (планирования) и моторики (исполнения) является узким местом для сложных задач.
Мы наблюдаем переход к воплощенному искусственному интеллекту (embodied AI), который способен напрямую связывать визуальные данные с физическими действиями. Модели нового поколения должны будут выдавать не просто описательный текст, а готовые к выполнению пространственные инструкции. Это требует принципиально иного подхода к обучению алгоритмов, где зрение, язык и физика пространства объединены в едином процессе.
Перспектива
В ближайшие годы индустрия, вероятнее всего, начнет отказываться от фрагментированных архитектур в робототехнике. Инструменты вроде GroundedPlanBench задают новый стандарт качества и вектор развития для создателей фундаментальных моделей.
По мере того как алгоритмы научатся лучше понимать геометрию пространства и планировать действия на много шагов вперед, роботы-манипуляторы станут значительно более автономными. Это ускорит их внедрение за пределами строго контролируемых заводских линий — на динамичных складах, в лабораториях и, со временем, в повседневной среде обитания человека.