Суть
Разработка и запуск AI-агентов фундаментально отличаются от привычного процесса создания программного обеспечения. В классической разработке мы привыкли к детерминированным системам: пользователь нажимает кнопку, система выполняет предсказуемое действие. Если что-то идет не так, мы смотрим на коды ошибок и время отклика. Однако с приходом агентов на базе больших языковых моделей (LLM) правила игры изменились. В недавнем материале LangChain подробно разбирается, почему традиционные инструменты мониторинга (APM) бесполезны для оценки качества работы агентов и как индустрия переходит к анализу семантики и трассировке диалогов.
Контекст
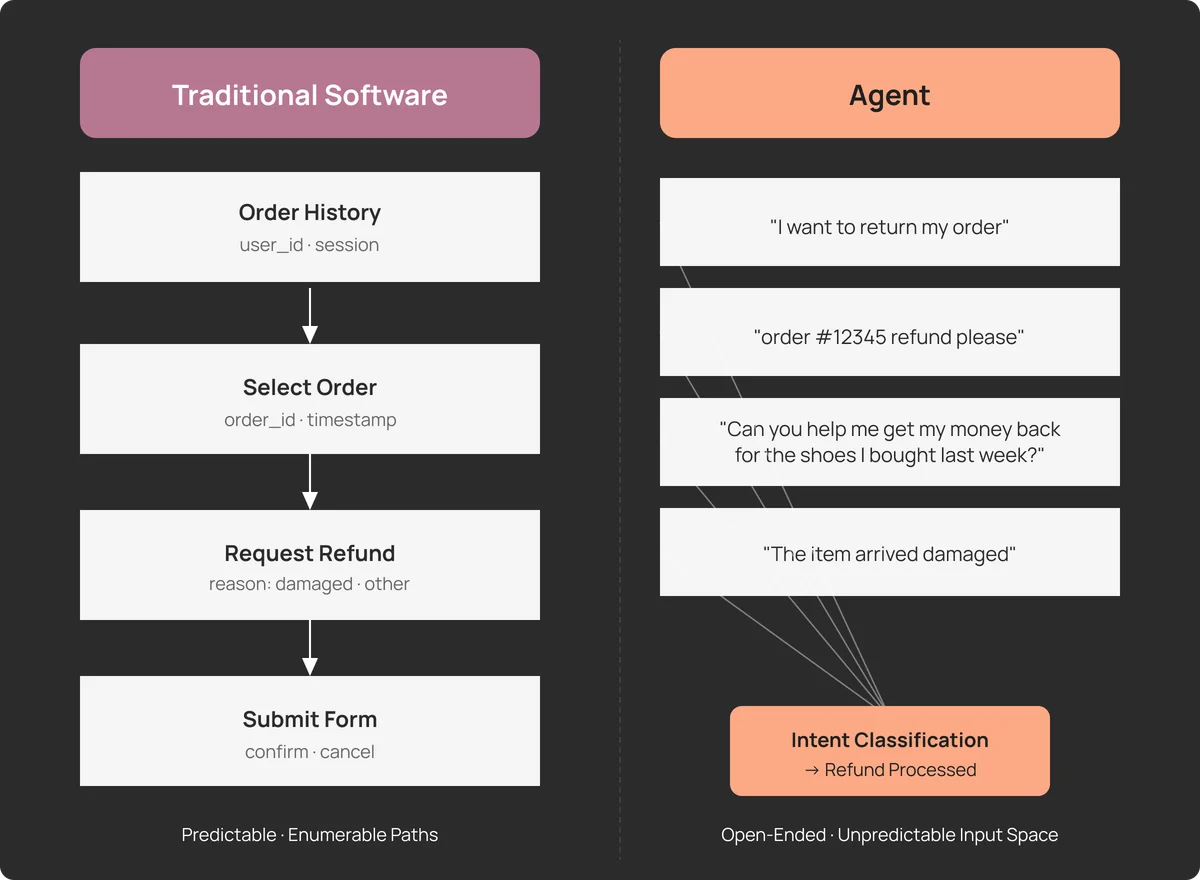
Традиционное программное обеспечение оперирует конечным набором входных данных. Формы имеют валидацию, API требуют строгой структуры JSON, а пути пользователя по интерфейсу заранее спроектированы. Вы можете покрыть тестами 90% кода и быть уверенными в стабильности системы.
AI-агенты работают иначе. Их основной интерфейс — естественный язык. Пространство ввода здесь бесконечно: один и тот же запрос на возврат товара пользователь может сформулировать тысячью разных способов — от формального заявления до сленгового сообщения с опечатками. Более того, сами модели (LLM) чувствительны к малейшим изменениям в формулировках и недетерминированы по своей природе. Один и тот же запрос может привести к разным результатам в разное время. Это означает, что поведение агента в тестовой среде часто не совпадает с тем, что происходит в реальной эксплуатации (продакшене).
Детали
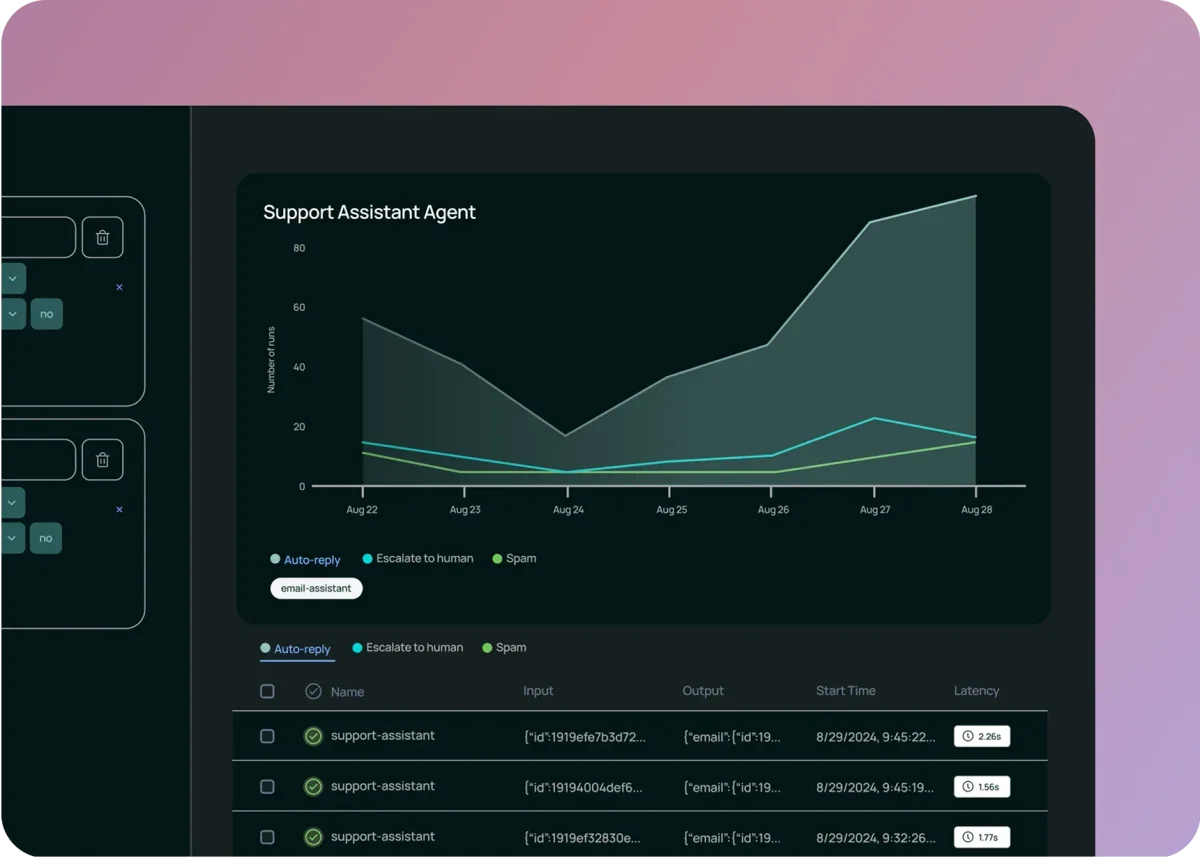
Основная проблема заключается в том, что «качество» работы агента скрыто внутри самого разговора, а не в системных метриках. Успешный HTTP-ответ со статусом 200 OK ничего не говорит о том, помог ли агент пользователю или нахамил ему. Для эффективного наблюдения необходимо внедрять новые подходы:
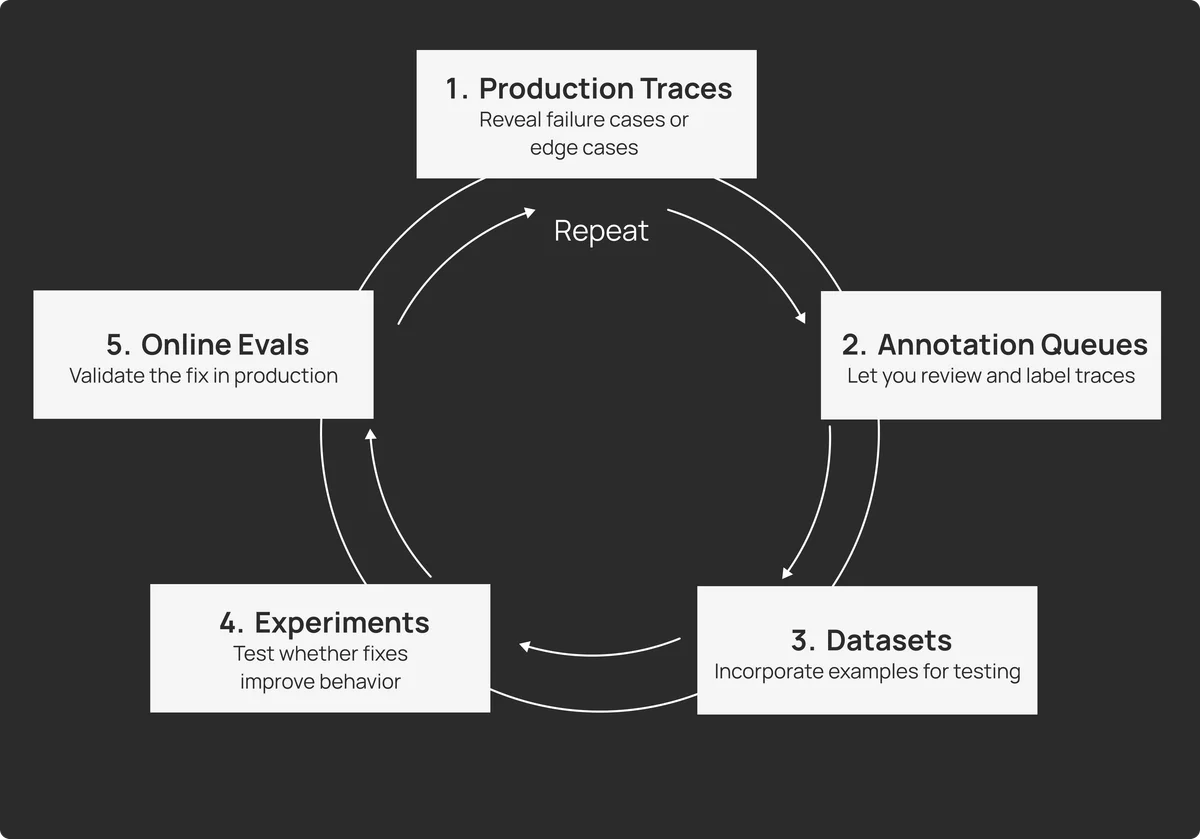
- Полная трассировка диалогов: Нужно сохранять не просто факт запроса, а весь контекст — что спросил пользователь, что ответил агент, и, что критически важно, какие промежуточные шаги (вызовы инструментов, поиск информации) предпринял агент для формирования ответа.
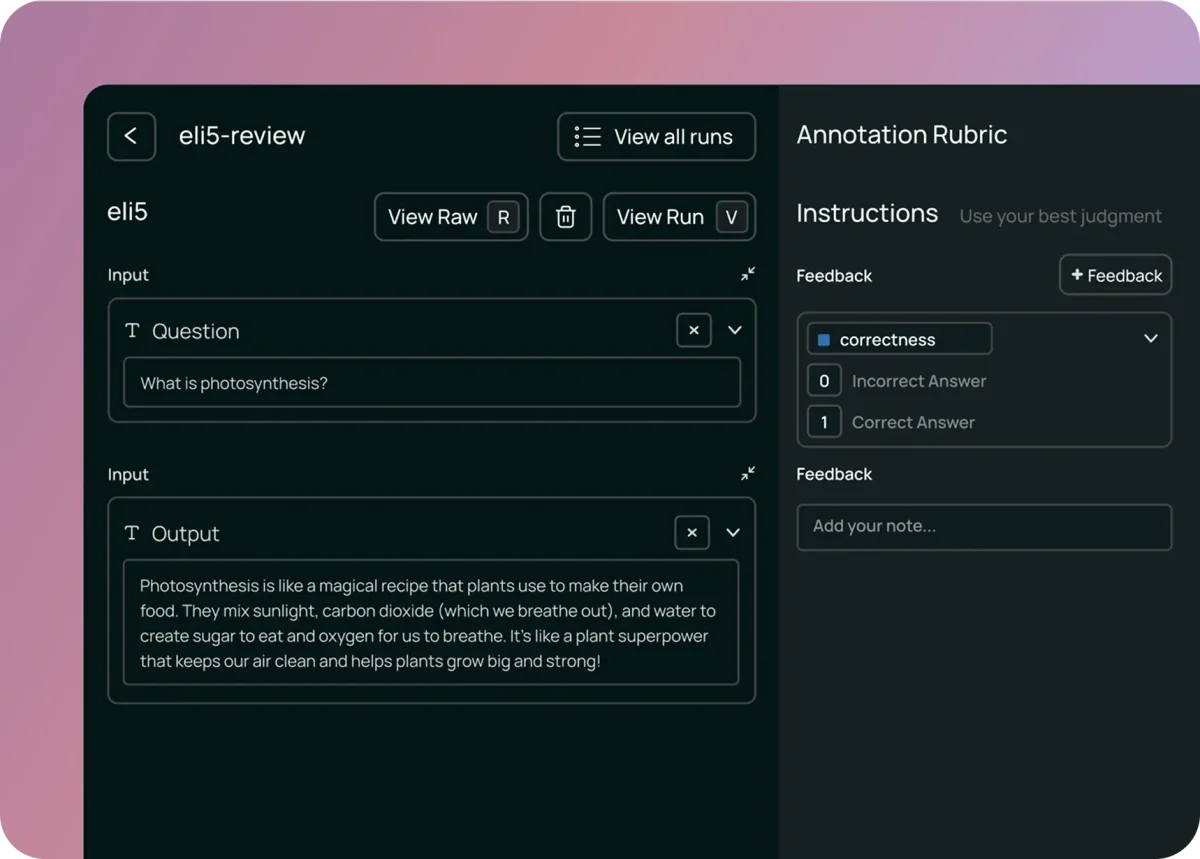
- Оценка человеческим суждением: Поскольку критерии «хорошего ответа» субъективны (тон, полезность, безопасность), необходима экспертная оценка. Однако масштабировать ручную проверку на тысячи диалогов невозможно.
- Очереди аннотаций: Это гибридный подход, когда на ручную проверку отправляются только специфические выборки диалогов (например, с негативными оценками пользователей или высокими затратами токенов).
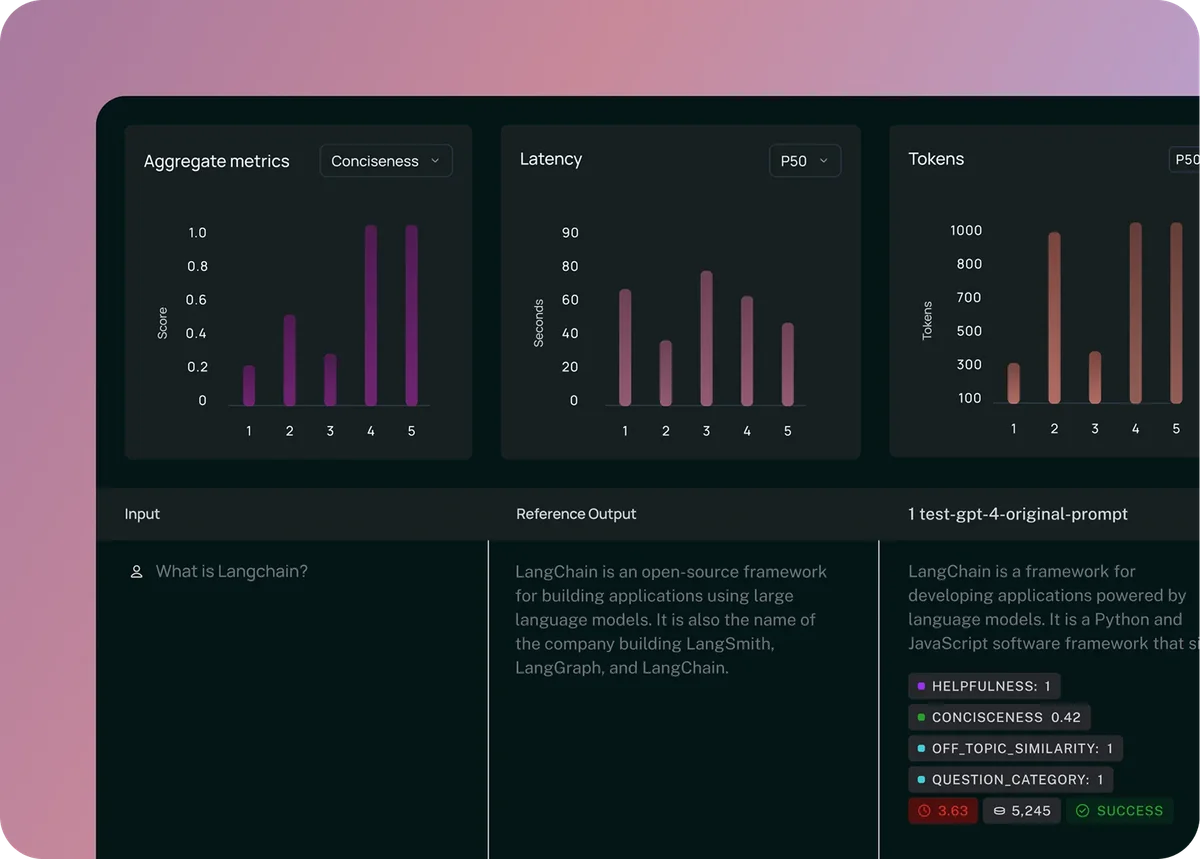
- LLM как судья: Использование одной языковой модели для оценки работы другой. Это позволяет автоматизировать проверку на масштабных данных, оценивая такие параметры, как вежливость, соответствие формату или отсутствие галлюцинаций.
Анализ
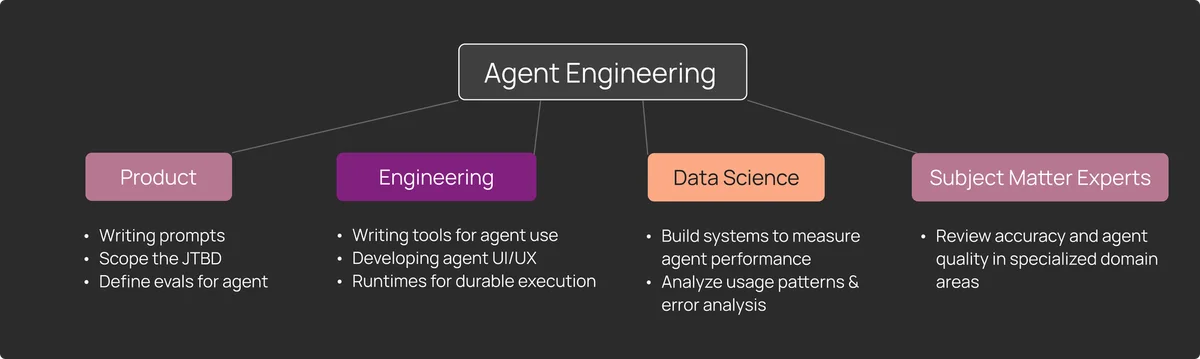
Мы наблюдаем формирование нового стека инструментов для LLM Ops. Если раньше инженеру достаточно было Grafana или Datadog для отслеживания загрузки CPU и памяти, то теперь необходимы платформы для семантического анализа логов.
Главный вызов здесь — баланс между стоимостью и точностью. Использование мощных моделей (например, GPT-4) для проверки каждого диалога в реальном времени может удвоить стоимость эксплуатации системы. Поэтому индустрия движется к выборочному анализу (сэмплированию) и использованию специализированных, более легких моделей-оценщиков.
Кроме того, меняется само понятие «ошибки». В традиционном ПО ошибка — это исключение в коде (Exception). В мире агентов ошибка — это галлюцинация, неверно выбранный инструмент или потеря контекста беседы. Эти сбои не видны в стандартных логах, их можно найти только путем анализа текста.
Перспектива
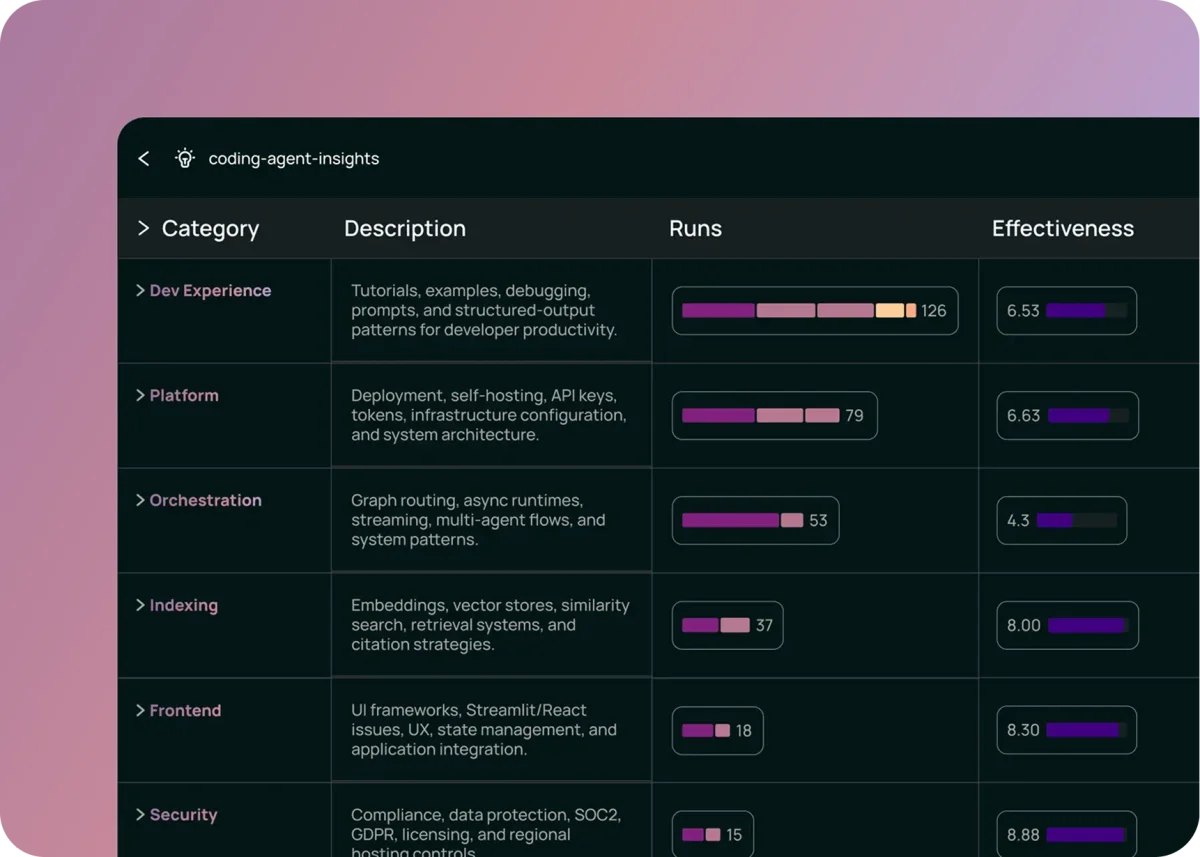
В ближайшем будущем мы увидим развитие инструментов автоматического поиска паттернов (кластеризации). Поскольку разработчики не могут заранее знать все сценарии использования своего агента, системы аналитики будут самостоятельно группировать похожие диалоги и подсвечивать аномалии или новые тренды в запросах пользователей.
Также ожидается стандартизация метрик качества для агентов. Сейчас каждая команда изобретает свои критерии оценки, но со временем появятся индустриальные стандарты для измерения «полезности» и «безопасности» автономных систем. Это позволит перевести разработку агентов из разряда экспериментов в надежный инженерный процесс.