Суть
Команда LangChain раскрыла внутреннюю кухню разработки и тестирования автономных систем на примере платформы Deep Agents. Главный тезис разработчиков заключается в том, что оценки (evals) напрямую формируют поведение ИИ-агента. Слепое наращивание количества тестов создает лишь иллюзию улучшения, в то время как по-настоящему качественные метрики должны измерять конкретное поведение системы в реальных условиях.
Контекст
Индустрия искусственного интеллекта стремительно переходит от простых запросов к большим языковым моделям (LLM) к созданию автономных агентов. Агенты способны использовать инструменты, планировать шаги и работать с файловыми системами. Однако тестирование таких систем представляет собой сложную задачу.
Каждый тест — это вектор, который смещает поведение всей системы. Если агент не справляется с задачей эффективного чтения файла, разработчик обычно корректирует системный промпт или описание инструмента. Это исправление влияет на все последующие действия агента. Поэтому добавление каждого нового теста требует осознанного подхода: неверно подобранные метрики будут оказывать давление на систему, уводя ее от желаемого поведения в рабочей среде (production).
Детали
LangChain выделяет три основных источника данных для создания тестов. Во-первых, это использование собственных продуктов (dogfooding) — каждая ошибка в работе внутренних инструментов, таких как Open SWE, становится основой для нового теста. Во-вторых, применяются внешние бенчмарки (например, Terminal Bench 2.0 или BFCL), которые адаптируются под конкретного агента. В-третьих, разработчики пишут собственные узконаправленные тесты для проверки специфических функций.
Процесс оценки строится в два этапа:
- Проверка корректности. Это базовый фильтр. Если модель не способна правильно выполнить задачу, остальные параметры не имеют значения. Для проверки используются точные совпадения, пользовательские утверждения или метод "LLM в качестве судьи" (LLM-as-a-judge) для семантических задач.
- Оценка эффективности. Две модели могут решить задачу верно, но совершенно по-разному. Разработчики измеряют соотношение шагов, количество вызовов инструментов, задержку и общую скорость решения (solve rate).
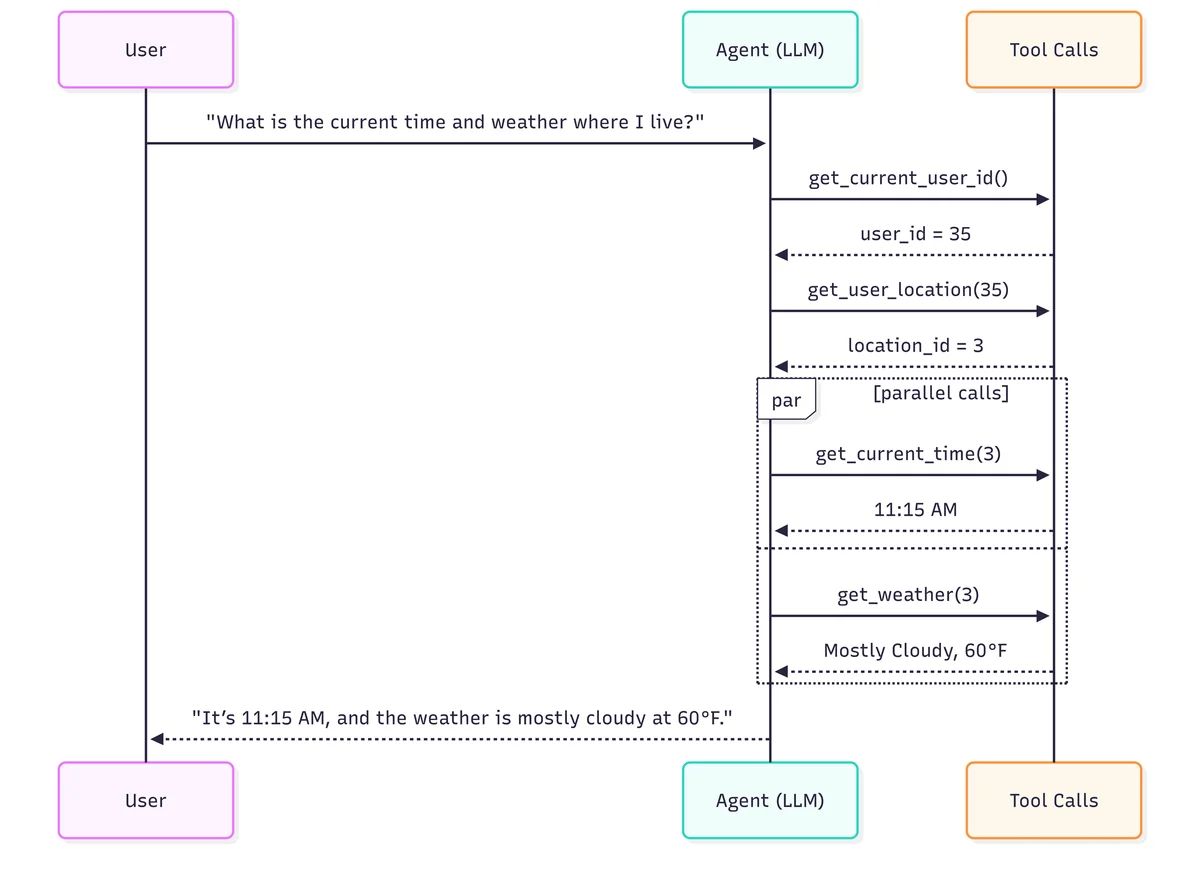
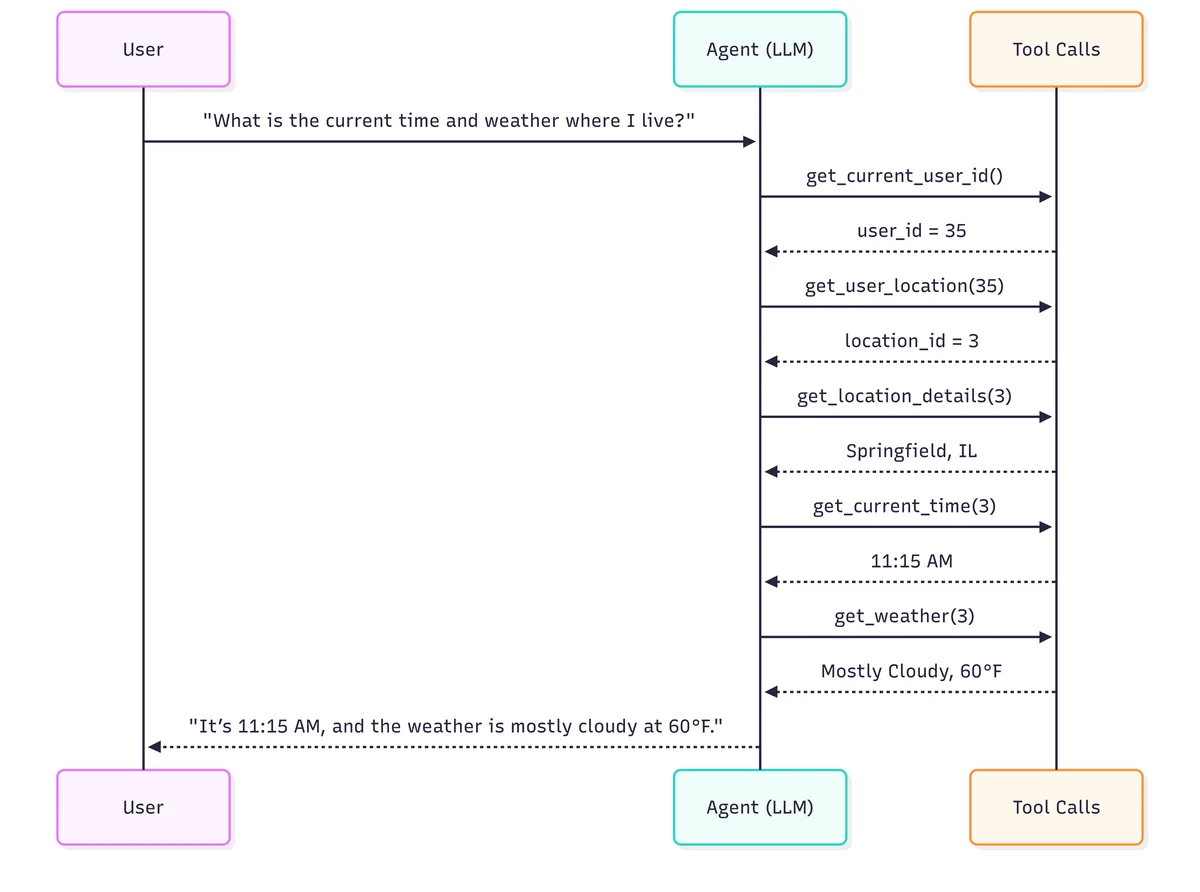
Для сравнения эффективности вводится понятие "идеальной траектории". Это последовательность действий, которая приводит к правильному результату без лишних шагов, с максимальным распараллеливанием процессов и минимальными затратами времени.
Анализ
Подход LangChain демонстрирует важный сдвиг в парадигме оценки ИИ. Индустрия отходит от использования агрегированных оценок из стандартизированных наборов данных. Единая цифра в бенчмарке больше не является показателем готовности агента к реальной работе.
Разделение оценки на "корректность" и "эффективность траектории" позволяет оптимизировать не только качество ответов, но и экономику продукта. Лишние шаги агента — это не просто технический недочет. В реальных условиях это означает увеличение задержки для пользователя и рост расходов на API поставщика модели.
Перспектива
По мере усложнения агентных архитектур, методы оценки будут все больше напоминать классическую разработку программного обеспечения с ее модульным и интеграционным тестированием. Однако специфика ИИ потребует развития инструментов для анализа трассировок (traces) в реальном времени.
Вероятно, в ближайшем будущем мы увидим появление стандартизированных платформ, которые позволят автоматически вычислять "идеальные траектории" для любых бизнес-задач и динамически корректировать системные промпты агентов без участия человека.