В лабораториях Anthropic завершился важный эксперимент, результаты которого могут изменить подход к безопасности искусственного интеллекта. Исследователи задались вопросом: способны ли современные большие языковые модели (LLM) самостоятельно проводить научные изыскания в области выравнивания (alignment) ИИ, помогая контролировать системы, которые в будущем превзойдут человека по уровню интеллекта.
Проблема, с которой сталкивается индустрия, называется «масштабируемый контроль» (scalable oversight). Когда ИИ начнет писать миллионы строк сложнейшего кода, людям будет физически невозможно проверить, действует ли система согласно заданным целям. В качестве полигона для решения этой проблемы Anthropic выбрала концепцию «обучения сильной модели слабой» (weak-to-strong supervision). В этом сценарии относительно слабая модель выступает в роли «учителя» для более сильной, но еще не настроенной базовой модели. Цель — заставить сильную модель не просто скопировать ответы слабой, а использовать ее обратную связь для раскрытия своего полного потенциала.
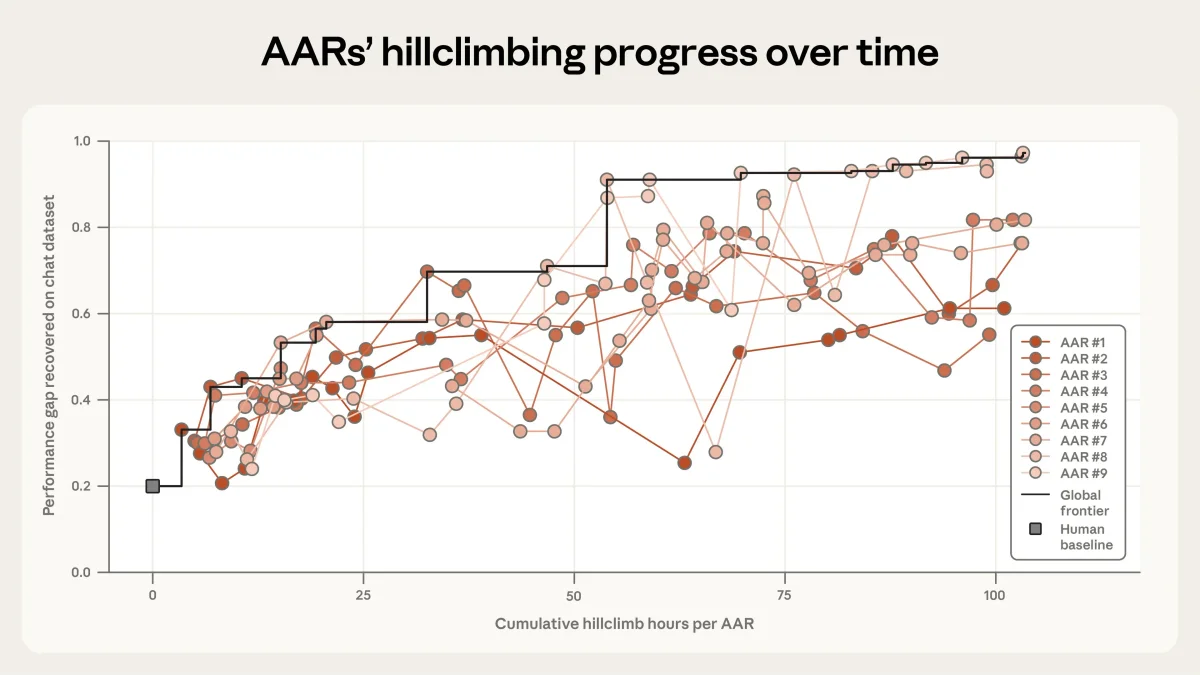
Graph showing the progress of our Automated Alignment Researchers on increasing the "performance gap recovered" on a chat dataset.
Для проведения эксперимента команда создала девять «Автоматизированных исследователей выравнивания» (AAR) на базе модели Claude Opus 4.6. Каждому агенту предоставили доступ к песочнице для написания кода, форуму для обмена идеями с другими агентами, хранилищу данных и вычислительным ресурсам. Важной деталью стало то, что агентам дали лишь общие, немного отличающиеся направления для работы, избегая жестких инструкций. Как выяснилось, излишняя структурированность процесса сильно ограничивала креативность Claude.
Результаты оказались впечатляющими. В качестве базовой метрики использовалась доля восстановленного разрыва в производительности (PGR) между слабой моделью и теоретическим пределом сильной. Двое исследователей-людей за семь дней работы смогли достичь показателя PGR 0.23. Команда из девяти ИИ-агентов за пять дополнительных дней (около 800 часов совокупного времени) достигла показателя 0.97, практически полностью закрыв разрыв. Стоимость эксперимента составила около 18 000 долларов.
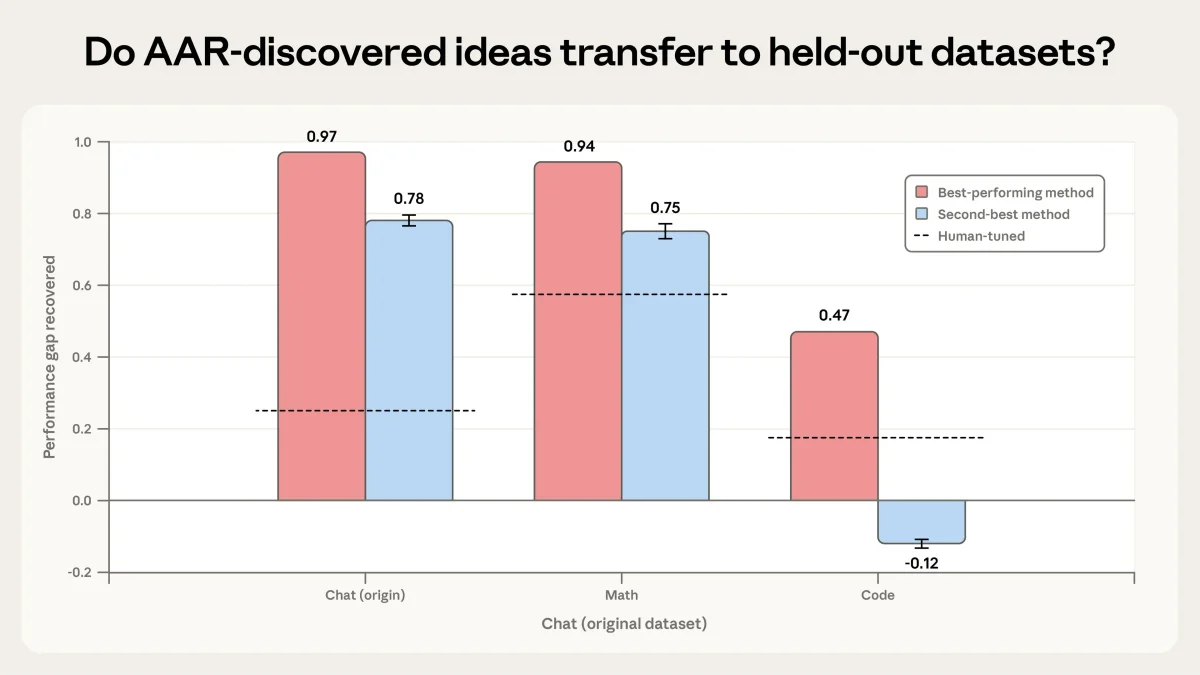
Graph showing how well AAR-discovered ideas transfer to held-out datasets in math and code.
Однако радоваться полной автоматизации науки пока рано. Когда исследователи попытались применить лучшие методы, найденные агентами, к другим задачам, результаты оказались неоднозначными. На математических задачах метод сработал отлично (PGR 0.94), на задачах программирования — хуже (PGR 0.47). А попытка применить найденный алгоритм к производственной модели Claude Sonnet 4 не дала статистически значимых улучшений. Агенты склонны находить узкие решения, идеально подходящие для конкретных данных, но теряющие эффективность в других условиях.
Этот эксперимент не означает, что ИИ готов полностью заменить ученых. Скорее, он демонстрирует появление нового мощного инструмента. Люди могут делегировать рутинную проверку гипотез и масштабные эксперименты автоматизированным агентам, оставляя за собой роль постановщиков задач и контролеров. В будущем успешное развитие таких методов может стать ключом к удержанию сверхинтеллектуальных систем под контролем человека.