Суть
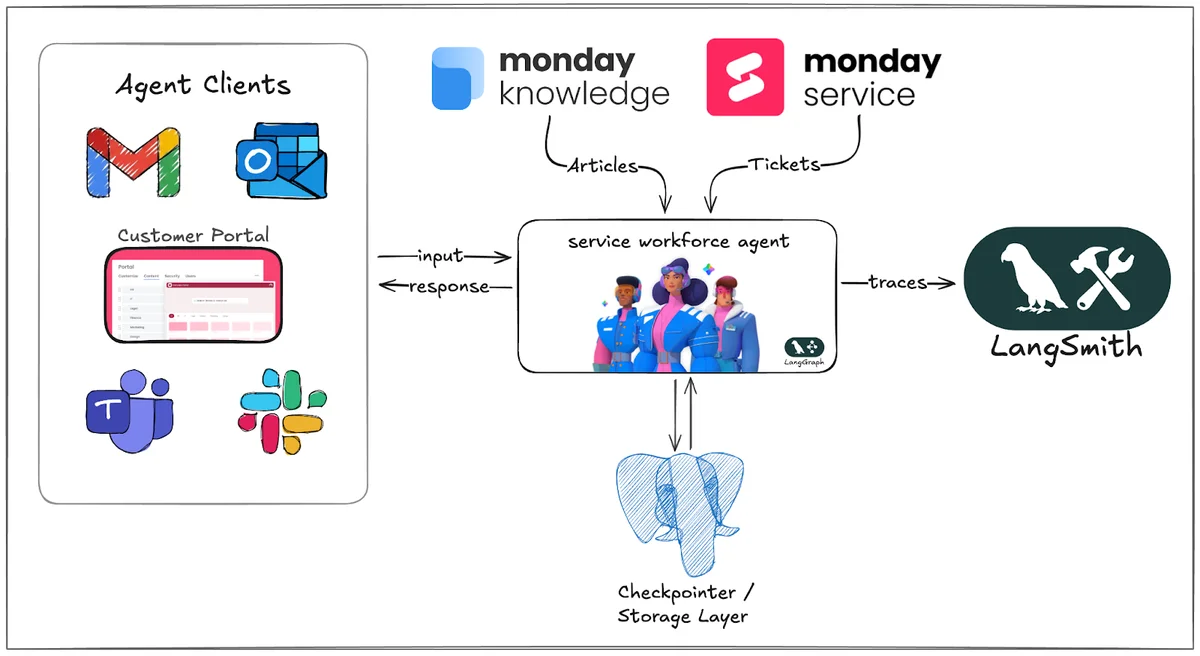
Команда Monday.com поделилась деталями разработки своей платформы monday Service — системы на базе AI-агентов для автоматизации корпоративных услуг (IT, HR, юридические вопросы). Главная особенность их подхода заключается в том, что они не оставили тестирование качества ответов нейросети «на потом», а внедрили его как обязательный инженерный этап с первого дня разработки.
Вместо того чтобы ждать жалоб от пользователей, инженеры создали систему, где логика оценки качества (evals) управляется как обычный программный код. Это позволило сократить время проверки гипотез с нескольких минут до секунд и выявлять ошибки еще до того, как они попадут в продакшн.
Контекст
В индустрии разработки AI-продуктов существует распространенная проблема: тестирование часто воспринимается как финальный этап перед релизом. Разработчики создают промпт, проверяют его на паре примеров и выпускают в мир. Однако для сложных систем, таких как ReAct-агенты (Reasoning + Acting), которые самостоятельно принимают решения и вызывают инструменты, такой подход опасен. Малейшее изменение в промпте может привести к каскадным ошибкам в логике агента.
Monday.com столкнулись с тем, что их агенты должны работать автономно в критически важных сферах бизнеса. Им требовалась уверенность, что агент не просто «звучит правильно», но и корректно использует базу знаний компании, соблюдает политики безопасности и правильно выбирает инструменты для решения задач.
Детали реализации
Инженеры Monday.com разделили процесс оценки на два фундаментальных столпа:
1. Офлайн-оценка («Страховочная сеть»)
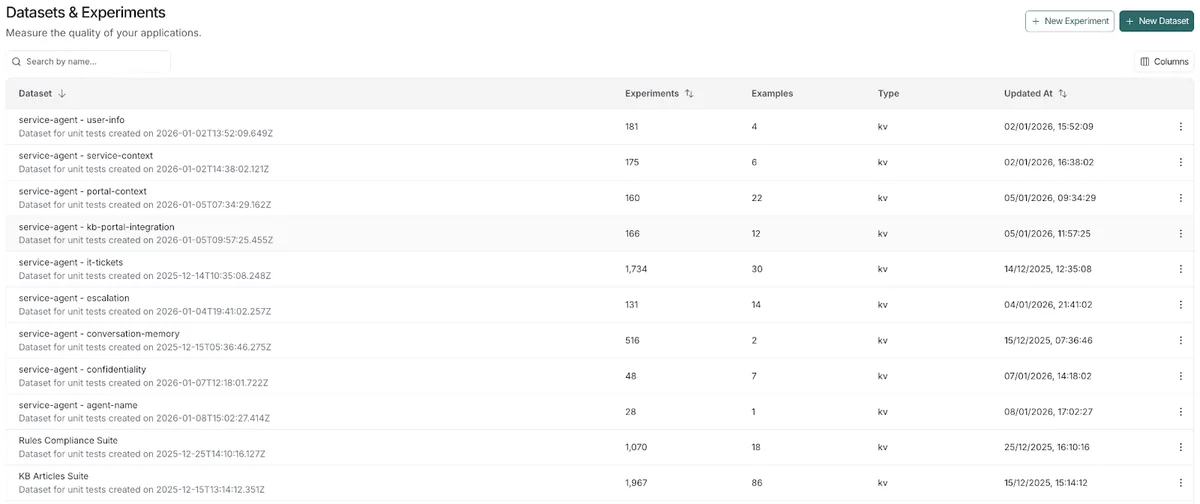
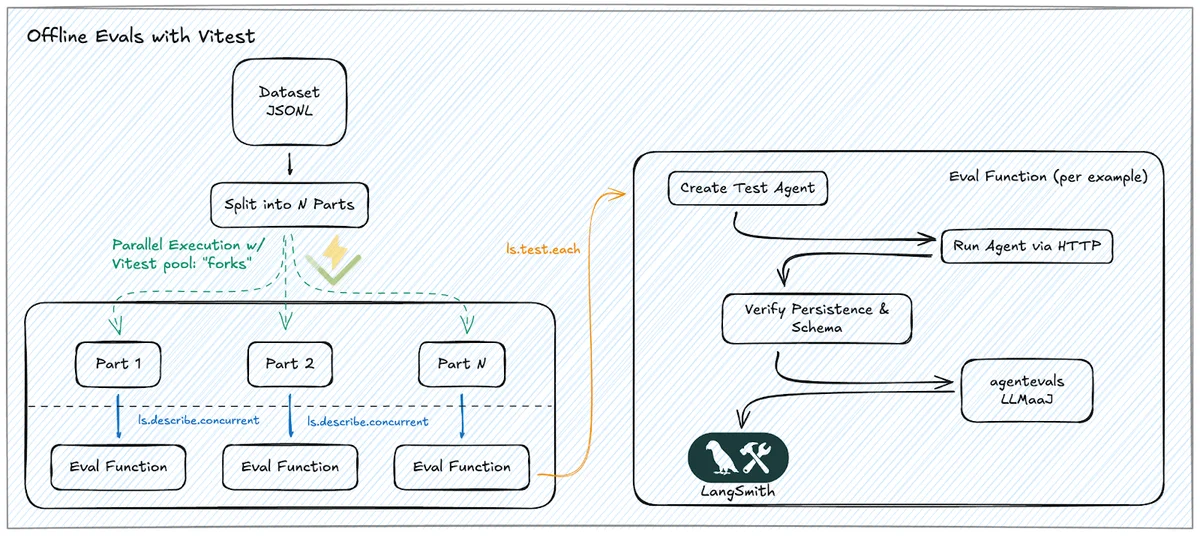
Это аналог модульных тестов (unit tests). Проверка происходит на этапе разработки:
- Детерминированные проверки: Агент не упал? Ответ соответствует нужному формату (JSON/схема)? Инструменты вызваны корректно?
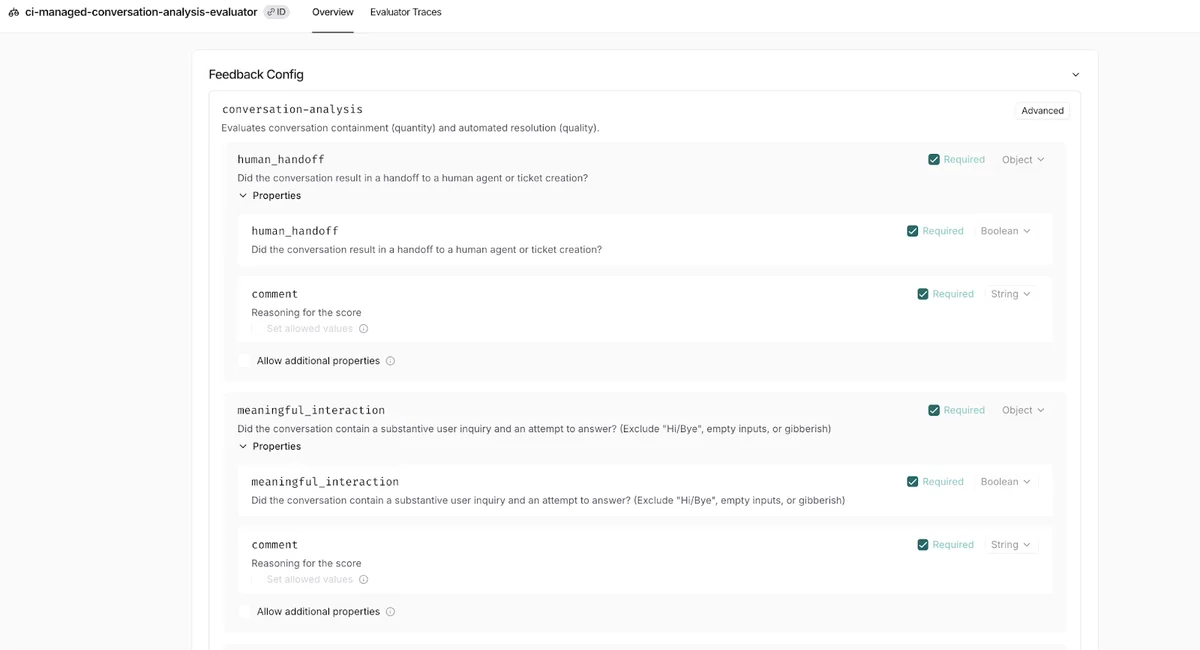
- LLM как судья: Специальная модель сверяет ответ агента с эталонным решением («золотым датасетом»). Проверяется точность фактов, отсутствие галлюцинаций и корректность ссылок на базу знаний.
- Инструментарий: Использовалась связка LangSmith и Vitest. Это позволило запускать тесты параллельно, используя все ядра процессора для локальных задач и асинхронные вызовы для обращений к LLM. Результат: ускорение цикла проверки в 8,7 раза (с 162 до 18 секунд).
2. Онлайн-оценка («Мониторинг»)
Это проверка работы агента в реальных условиях (в продакшене):
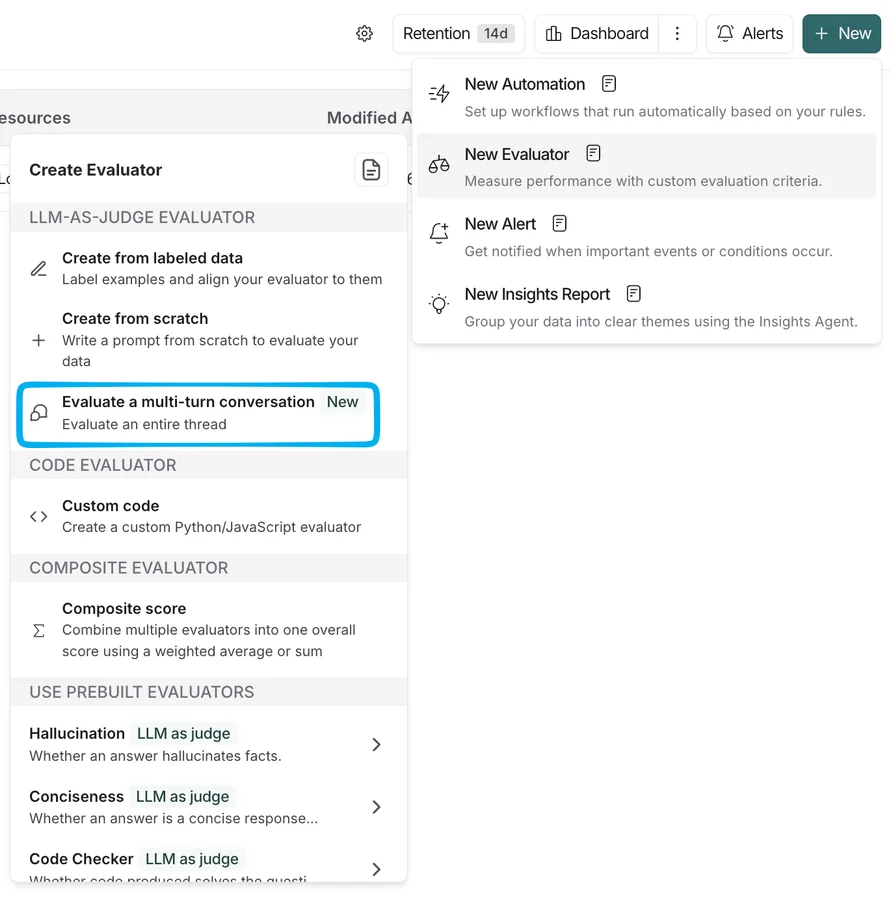
- Многоходовая оценка: Поскольку агент ведет диалог, важно оценивать не одну реплику, а всю цепочку рассуждений. Система анализирует, насколько эффективно агент привел пользователя к решению проблемы.
- Метрики бизнеса: Отслеживаются показатели автоматического разрешения тикетов и удовлетворенности пользователей.
Анализ
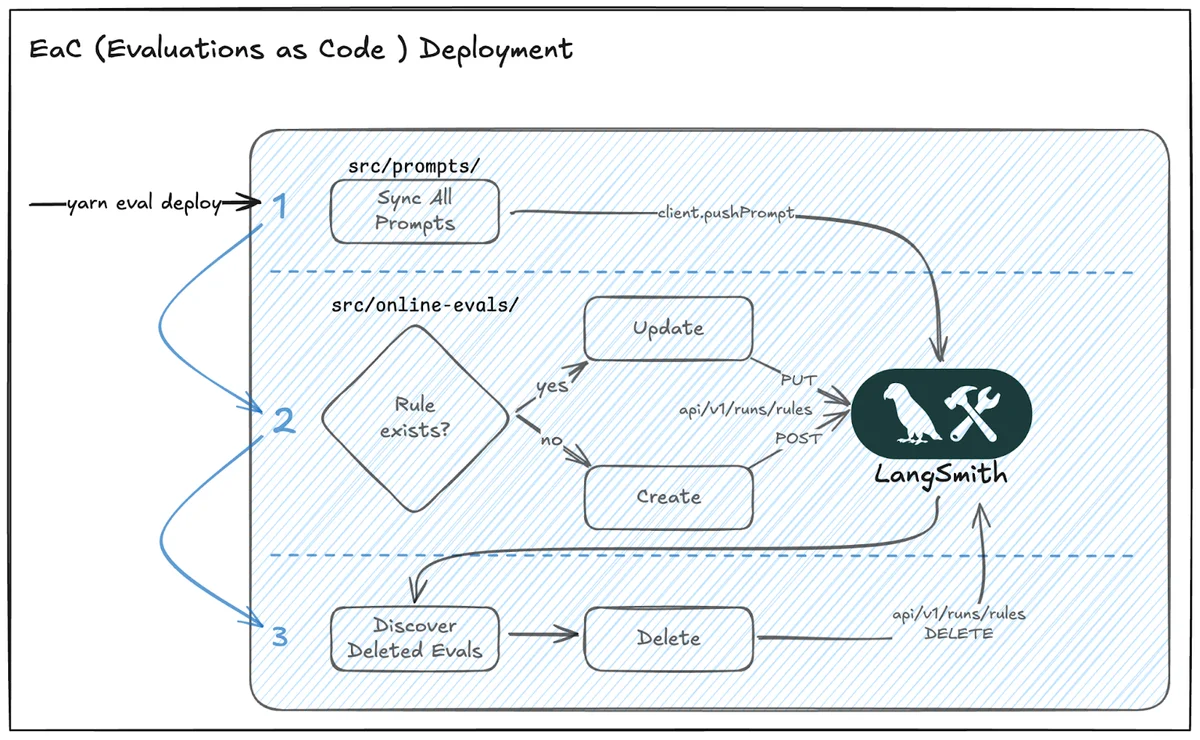
Этот кейс демонстрирует важный сдвиг в культуре разработки AI-приложений: переход от «алхимии» (подбора промптов наугад) к строгой инженерной дисциплине. Подход «Evaluations as Code» (Оценка как код) означает, что критерии качества версионируются в Git, проходят ревью и являются частью CI/CD пайплайна.
Использование Vitest для запуска тестов LLM — нестандартное, но эффективное решение. Обычно фреймворки для тестирования кода не приспособлены для работы с вероятностными моделями, но адаптация существующих инструментов (Vitest) под новые задачи (LangSmith) позволяет разработчикам оставаться в привычной среде, не теряя в скорости.
Перспектива
Опыт Monday.com подтверждает тренд на профессионализацию разработки LLM-приложений. В ближайшем будущем мы увидим стандартизацию подобных практик: наличие автоматизированных тестов на галлюцинации и логику станет таким же обязательным требованием для AI-сервисов, как наличие тестов безопасности для банковских приложений. Компании, которые игнорируют этот этап, рискуют столкнуться с непредсказуемым поведением своих агентов и потерей доверия клиентов.