Установка Hermes Agent
Цели урока
После прохождения этого урока вы сможете:
- 1Установить Hermes Agent через Docker (рекомендуемый способ)
- 2Узнать альтернативный способ установки из исходников
- 3Настроить API-ключ и базовую конфигурацию
- 4Понять системные требования для разных сценариев
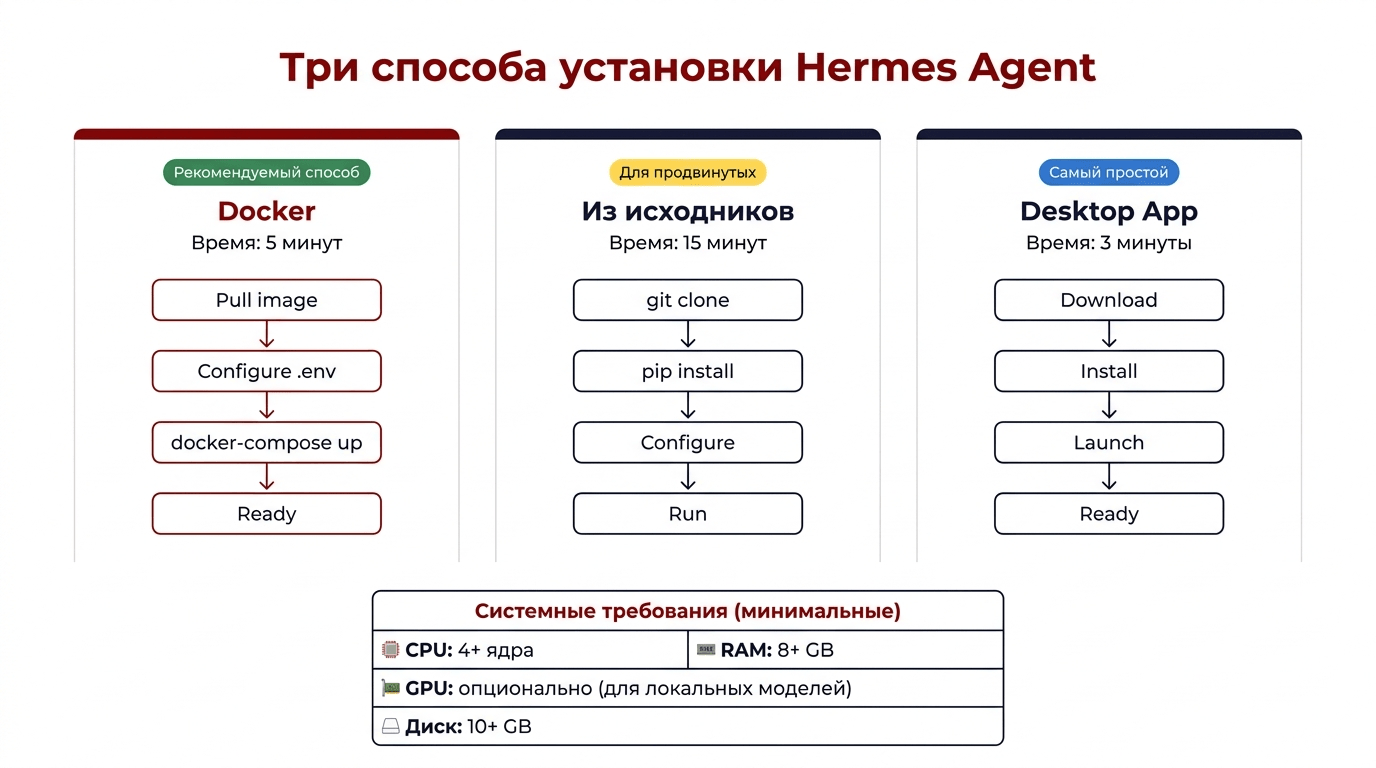
Три способа установки
Hermes Agent можно установить тремя способами: через Docker (рекомендуется), из исходников или через Desktop App. Docker - самый простой и надежный вариант: все зависимости уже собраны в контейнер.
Системные требования
| Компонент | Минимум (API-режим) | Рекомендуемый (локальная модель) | Оптимальный (Hermes 4.3 36B) |
|---|---|---|---|
| ОС | Linux, macOS, Windows (WSL2) | Linux, macOS | Linux |
| ОЗУ | 4 ГБ | 16 ГБ | 64 ГБ |
| GPU | Не требуется | 8 ГБ VRAM (RTX 3070) | 24+ ГБ VRAM (RTX 4090, A100) |
| Диск | 2 ГБ | 20 ГБ | 80 ГБ |
| Docker | v20+ | v24+ с NVIDIA Container Toolkit | v24+ с NVIDIA Container Toolkit |
| Python | 3.10+ | 3.10+ | 3.10+ |
Способ 1: Docker (рекомендуется)
Docker - самый простой способ начать. Все зависимости, модели и конфигурации уже собраны в контейнер. Четыре команды - и агент работает.
Клонируйте репозиторий: git clone https://github.com/NousResearch/hermes-agent.git
Перейдите в директорию: cd hermes-agent
Создайте файл конфигурации: cp .env.example .env
Добавьте API-ключ в .env (или настройте локальную модель)
Запустите контейнер: docker compose up -d
# Клонируем репозиторий
git clone https://github.com/NousResearch/hermes-agent.git
cd hermes-agent
# Создаем конфигурацию
cp .env.example .env
# Редактируем .env - добавляем API-ключ
# (или оставляем пустым для локальной модели)
nano .env# Файл .env - базовая конфигурация
# Выбор модели (одно из):
HERMES_MODEL=hermes-4.3 # Локальная модель (нужен GPU 24GB+)
# OPENAI_API_KEY=sk-... # Или используйте OpenAI API
# ANTHROPIC_API_KEY=sk-ant-... # Или Anthropic API
# Основные настройки
HERMES_MEMORY_DIR=./data/memory
HERMES_LOG_LEVEL=info
HERMES_MAX_STEPS=50
# Telegram (опционально)
# TELEGRAM_BOT_TOKEN=123456:ABC-DEF...
# TELEGRAM_ALLOWED_USERS=user_id_1,user_id_2# Запускаем контейнер
docker compose up -d
# Проверяем статус
docker compose ps
# Смотрим логи
docker compose logs -f hermes-agent
# Первый запрос к агенту
docker compose exec hermes-agent hermes chat "Привет! Расскажи о себе"Способ 2: Из исходников
Установка из исходников дает больше контроля, но требует ручной настройки зависимостей. Подходит для разработчиков, которые планируют модифицировать код агента.
# Клонируем и устанавливаем зависимости
git clone https://github.com/NousResearch/hermes-agent.git
cd hermes-agent
python -m venv .venv
source .venv/bin/activate
pip install -e ".[all]"
# Настраиваем конфигурацию
cp .env.example .env
nano .env
# Запускаем
hermes serve # Сервер с API
# или
hermes chat # Интерактивный чатСпособ 3: Desktop App
Desktop App - графическое приложение для macOS, Windows и Linux. Самый простой способ для нетехнических пользователей: скачиваете установщик, запускаете, вводите API-ключ и начинаете работать.
Локальный запуск через Ollama и vLLM
Hermes Agent не привязан к одной модели. Его можно запустить на любом OpenAI-совместимом API - включая локальные серверы Ollama, vLLM, llama.cpp или LM Studio. Это позволяет использовать квантизованные версии для слабого железа.
| Модель | Размер (GGUF) | VRAM | Подходящий GPU | Качество |
|---|---|---|---|---|
| Hermes 4.3 36B (FP16) | 72 ГБ | 80 ГБ | A100 80GB, 2x RTX 4090 | Максимальное |
| Hermes 4.3 36B (Q8) | 36 ГБ | 40 ГБ | A100 40GB, RTX A6000 | Отличное |
| Hermes 4.3 36B (Q4_K_M) | 20 ГБ | 24 ГБ | RTX 4090, RTX 3090 | Хорошее |
| Hermes 3.5 8B (Q8) | 8 ГБ | 10 ГБ | RTX 3070, RTX 4060 | Приемлемое |
| Hermes 3.5 8B (Q4_K_M) | 4.5 ГБ | 6 ГБ | RTX 3060, Apple M1 | Базовое |
# Вариант 1: Ollama (самый простой для локального запуска)
ollama pull hermes3.5:8b-q4_K_M # Скачать модель 4.5 ГБ
ollama serve # Запустить сервер
# В .env Hermes Agent:
HERMES_MODEL=hermes-3.5
OPENAI_API_BASE=http://localhost:11434/v1
OPENAI_API_KEY=ollama # Любое значение
# Вариант 2: vLLM (для продакшна, быстрее Ollama)
pip install vllm
vllm serve NousResearch/Hermes-3-Llama-3.1-8B \
--quantization awq --max-model-len 8192
# В .env:
OPENAI_API_BASE=http://localhost:8000/v1
OPENAI_API_KEY=vllmМульти-модельные профили
Hermes Agent поддерживает профили моделей - можно переключаться между провайдерами или использовать разные модели для разных задач. Например, быструю 8B модель для рутинных задач и мощную 36B для сложного анализа.
# config/models.yaml - профили моделей
profiles:
local-fast:
provider: ollama
model: hermes3.5:8b-q4_K_M
endpoint: http://localhost:11434/v1
use_for: [chat, simple_tasks]
local-powerful:
provider: vllm
model: NousResearch/Hermes-4.3-36B-AWQ
endpoint: http://localhost:8000/v1
use_for: [analysis, code_review, planning]
cloud-codex:
provider: openai-compatible
model: codex-mini-latest
endpoint: https://api.openai.com/v1
api_key: ${OPENAI_API_KEY}
use_for: [coding]
cloud-glm:
provider: openai-compatible
model: glm-4-plus
endpoint: https://open.bigmodel.cn/api/paas/v4
api_key: ${GLM_API_KEY}
use_for: [chinese_content]
default: local-fast
routing: auto # Агент сам выбирает профиль по задачеЛюбой OpenAI-совместимый API работает как бэкенд для Hermes Agent: OpenAI, Anthropic (через прокси), Together AI, Groq, Fireworks, DeepSeek, GLM, локальные Ollama/vLLM/LM Studio. Достаточно указать endpoint и API-ключ.
Для запуска Hermes 4.3 (36B параметров) локально требуется GPU с 24+ ГБ видеопамяти. Но квантизованная версия 8B модели работает даже на RTX 3060 или Apple M1 с 16 ГБ RAM. Начните с малого и масштабируйте по мере необходимости.
Docker - рекомендуемый способ установки. Для модели: начните с API-режима (NousResearch API, OpenAI, Anthropic) или Ollama с 8B моделью. Hermes Agent работает с любым OpenAI-совместимым API - от локального Ollama до облачного Codex или GLM. Мульти-модельные профили позволяют автоматически выбирать модель под задачу.
Вопросы для размышления
- •Какой способ установки подходит для вашей инфраструктуры?
- •Есть ли у вас GPU, достаточный для запуска Hermes 4.3 локально, или лучше начать с API-режима?