Система памяти Hermes
Цели урока
После прохождения этого урока вы сможете:
- 1Понять три уровня памяти AI-агента: краткосрочная, долгосрочная, эпизодическая
- 2Научиться сохранять и извлекать данные из постоянного хранилища
- 3Оценить разницу между агентом с памятью и без нее
Зачем AI-агенту память
Обычный чат-бот начинает каждый разговор с чистого листа. Он не помнит, о чем вы говорили вчера, какие задачи решали и какие предпочтения высказывали. AI-агент с памятью - это принципиально другой уровень. Hermes может накапливать знания между сессиями, обучаться на ошибках и адаптироваться под конкретного пользователя.
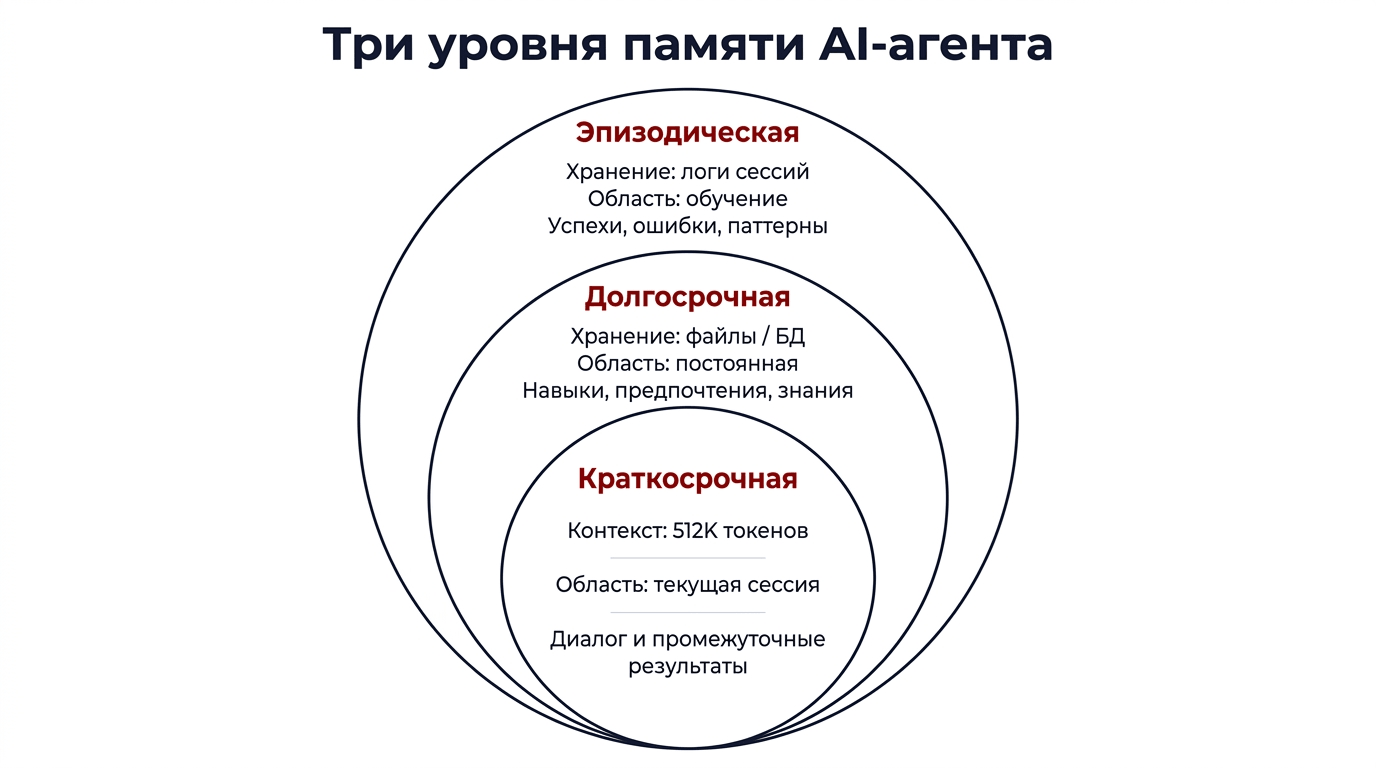
Три уровня памяти
Система памяти Hermes построена по аналогии с человеческой памятью и включает три уровня, каждый из которых решает свою задачу.
| Уровень | Аналогия | Хранилище | Время жизни | Объем |
|---|---|---|---|---|
| Краткосрочная | Оперативная память | Контекстное окно (до 512K токенов) | Текущая сессия | Ограничен контекстом модели |
| Долгосрочная | Жесткий диск | Файлы, база данных, векторное хранилище | Между сессиями (постоянно) | Практически неограничен |
| Эпизодическая | Дневник | Логи сессий, журнал действий | Между сессиями (с ротацией) | Настраивается пользователем |
Краткосрочная память - контекстное окно
Контекстное окно Hermes 3 (на базе Llama 3.1) составляет до 128K токенов, но при локальном развертывании обычно используется 32K-64K. Hermes 4 (на базе Llama 4 Maverick) поддерживает до 512K токенов. В этом окне хранится текущий диалог, системный промпт, описания инструментов и результаты последних действий. Когда окно заполняется, старые сообщения вытесняются - агент буквально забывает начало разговора.
Долгосрочная память - постоянное хранилище
Долгосрочная память - это то, что отличает настоящего AI-агента от чат-бота. Hermes может сохранять информацию в файлы, базу данных или векторное хранилище. Эта информация доступна между сессиями. Агент запоминает ваши предпочтения, контекст проектов, частые запросы и накопленные знания.
# Конфигурация долгосрочной памяти Hermes
memory:
# Файловое хранилище (простейший вариант)
file_store:
path: ./data/memory
format: json
# Векторное хранилище (для семантического поиска)
vector_store:
provider: chromadb
collection: hermes_memory
embedding_model: nomic-embed-text
# Структурированные данные
database:
provider: sqlite
path: ./data/hermes.db
tables:
- user_preferences
- project_context
- learned_patternsЭпизодическая память - журнал сессий
Эпизодическая память хранит логи прошлых сессий: какие задачи выполнялись, какие ошибки возникали, какие решения были приняты. Это позволяет агенту учиться на собственном опыте. Например, если в прошлой сессии определенный подход не сработал, агент может избежать этой ошибки в будущем.
Сохранение и извлечение из памяти
# Пример навыка для работы с долгосрочной памятью
name: memory_manager
description: Управление долгосрочной памятью агента
tools:
- name: save_memory
description: Сохранить информацию в постоянную память
parameters:
category: string # preferences, facts, patterns
key: string
value: string
importance: number # 1-10
- name: recall_memory
description: Извлечь информацию из памяти
parameters:
query: string
category: string # optional filter
limit: number # max results
instructions: |
При каждом значимом взаимодействии:
1. Определи, содержит ли сообщение пользователя
новую информацию о его предпочтениях
2. Если да - сохрани через save_memory
3. Перед ответом на вопрос - проверь recall_memory
на наличие релевантного контекста
4. Используй найденный контекст для персонализацииПрактический пример: извлечение знаний
# Python - работа с памятью через API
import json
from pathlib import Path
class HermesMemory:
def __init__(self, storage_path="./data/memory"):
self.path = Path(storage_path)
self.path.mkdir(parents=True, exist_ok=True)
def save(self, category: str, key: str, value: str, importance: int = 5):
"""Сохранить факт в долгосрочную память"""
file = self.path / f"{category}.json"
data = json.loads(file.read_text()) if file.exists() else {}
data[key] = {
"value": value,
"importance": importance,
"updated": "2026-06-09"
}
file.write_text(json.dumps(data, ensure_ascii=False, indent=2))
def recall(self, category: str, key: str = None) -> dict:
"""Извлечь из памяти по категории и ключу"""
file = self.path / f"{category}.json"
if not file.exists():
return {}
data = json.loads(file.read_text())
if key:
return data.get(key, {})
return data
# Использование
memory = HermesMemory()
memory.save("preferences", "timezone", "Europe/Moscow", importance=8)
memory.save("preferences", "language", "Russian", importance=9)
memory.save("facts", "project_stack", "Next.js + PostgreSQL", importance=7)
# Извлечение
prefs = memory.recall("preferences")
print(prefs) # {"timezone": {...}, "language": {...}}Агент без памяти и с памятью
После 10 сессий агент с памятью работает значительно эффективнее, чем в первый день. Он знает ваш стек, предпочтения, типичные задачи и частые ошибки. Это экономит от 5 до 15 минут на каждое взаимодействие - время, которое вы раньше тратили на повторное объяснение контекста.
Начните с файлового хранилища памяти - это самый простой способ. Когда объем данных вырастет, переходите на векторное хранилище для семантического поиска по накопленным знаниям.
Вопросы для размышления
- •Какую информацию о вашей работе агент должен запоминать в первую очередь?
- •Где бы вы хранили долгосрочную память агента - в файлах, базе данных или векторном хранилище?